Gemini 2.5 Flash vs Claude Sonnet 4.6: Cost vs Code
Gemini 2.5 Flash costs 10x less and runs 4x faster than Claude Sonnet 4.6, but trails badly on coding benchmarks - here is the full breakdown.

Most developers working in production settle on one of these two models. Gemini 2.5 Flash and Claude Sonnet 4.6 both target the same middle tier - too capable to use the cheap nano models, too expensive to justify the flagship. But they get there by opposite means. Flash is Google's bet on raw speed and multimodal breadth at a price that genuinely changes the economics of high-volume applications. Sonnet 4.6 is Anthropic's answer for teams where code quality and instruction precision matter more than the invoice.
TL;DR
- Choose Gemini 2.5 Flash if you need fast, multimodal inference at 10x lower cost - especially for classification, summarization, or any workflow involving audio and video
- Choose Claude Sonnet 4.6 if software engineering quality is non-negotiable: it scores 79.6% on SWE-bench Verified, nearly double Flash's tier
- Flash wins on price and speed; Sonnet wins on coding and instruction following - there's no overall winner, only a right tool for your task
Quick Comparison
| Feature | Gemini 2.5 Flash | Claude Sonnet 4.6 |
|---|---|---|
| Provider | Google DeepMind | Anthropic |
| Release Date | June 2025 | February 2026 |
| Input Pricing | $0.30 / MTok | $3.00 / MTok |
| Output Pricing | $2.50 / MTok | $15.00 / MTok |
| Free Tier | Yes (AI Studio) | Claude.ai Pro ($20/mo) |
| Context Window | 1M tokens | 1M tokens |
| Max Output | 66K tokens | 64K tokens |
| Output Speed | ~192 tokens/sec | ~50 tokens/sec |
| Time to First Token | 0.61s | 1.16s |
| Multimodal Input | Text, images, audio, video | Text, images only |
| SWE-bench Verified | Not published officially | 79.6% |
| GPQA Diamond | 82.8% | 74.1% |
| Thinking Mode | Toggleable (0-24,576 tokens) | Adaptive Thinking |
| Best For | High-volume, multimodal, cost-sensitive | Software engineering, agentic tasks |
Gemini 2.5 Flash
Flash is the model Google uses to prove that fast and smart don't have to be mutually exclusive. Released in June 2025, it sits below Gemini 2.5 Pro in the lineup but borrows the same core architecture, including the toggleable thinking system that made 2.5 Pro remarkable. At 192 output tokens per second with a 0.61s time to first token, it consistently outpaces anything Anthropic ships at this tier by a factor of four.
The thinking controls are a real differentiator. Setting thinkingBudget to 0 disables chain-of-thought completely, delivering 2.0 Flash-level speed for straightforward tasks. Setting it to -1 enables dynamic thinking, where the model scales its reasoning effort to request complexity. The maximum budget caps at 24,576 tokens - enough for meaningful multi-step problems without hitting the cost ceiling of a fully reasoning model. That flexibility lets one model handle both low-latency Q&An and harder analytical tasks within the same API integration.
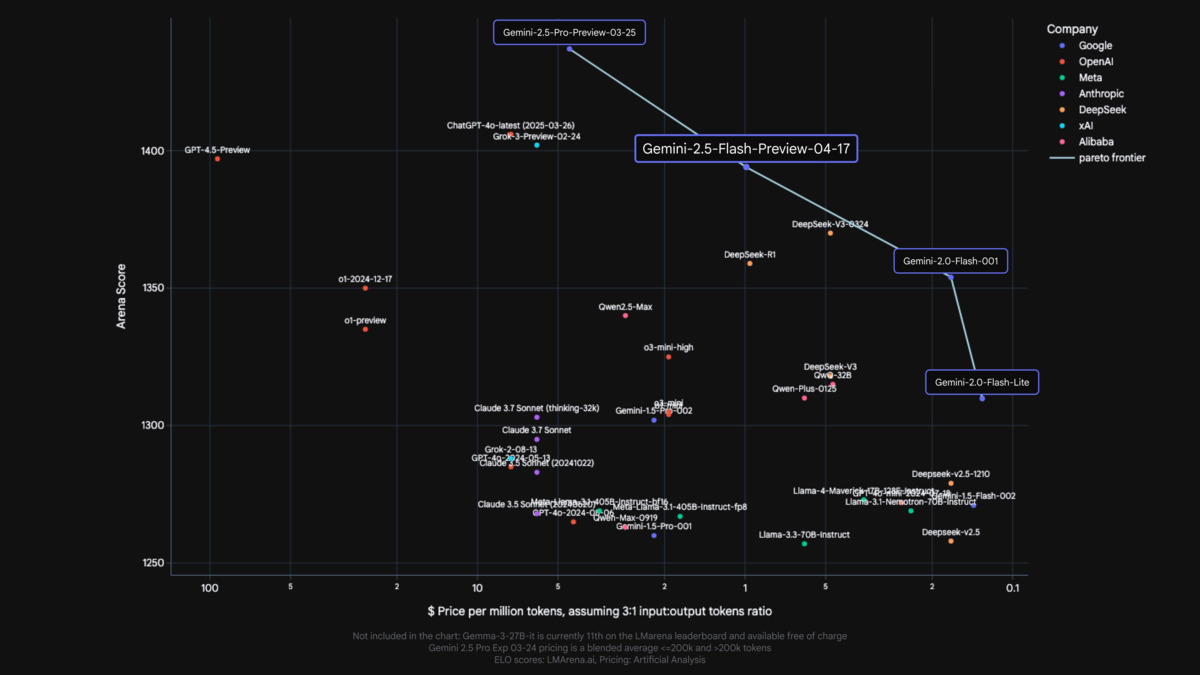 Gemini 2.5 Flash sits on the pareto frontier of cost vs. quality among mid-tier models.
Source: developers.googleblog.com
Gemini 2.5 Flash sits on the pareto frontier of cost vs. quality among mid-tier models.
Source: developers.googleblog.com
On science and math, Flash performs well above its price tier. It scores 82.8% on GPQA Diamond and 88.0% on AIME 2024, which puts it above Claude Sonnet 4.6 on both benchmarks. For applications in education, research assistance, or any domain where scientific accuracy matters, those numbers are meaningful. What Flash doesn't publish is a clean SWE-bench Verified score - Google's model cards focus on reasoning evals rather than software engineering, and the Flash-Lite variant's 41.3% suggests the full Flash model is unlikely to compete with Sonnet 4.6's 79.6% on code generation.
The free tier through Google AI Studio is a genuine advantage for prototyping. Teams can test workloads at scale before committing to API costs, which has no direct equivalent on the Anthropic side.
Claude Sonnet 4.6
Sonnet 4.6 shipped on February 17, 2026, as part of Anthropic's 4.6 generation with Opus 4.6 and Haiku 4.5. It's described internally as delivering near-Opus performance at mid-tier pricing - the Claude Sonnet 4.6 model profile on this site covers the architecture in detail. The headline number is 79.6% on SWE-bench Verified, which measures the ability to resolve real GitHub issues by writing actual patches. That score sits 1.2 points behind Opus 4.6 and represents a 2.4 point improvement over Sonnet 4.5.
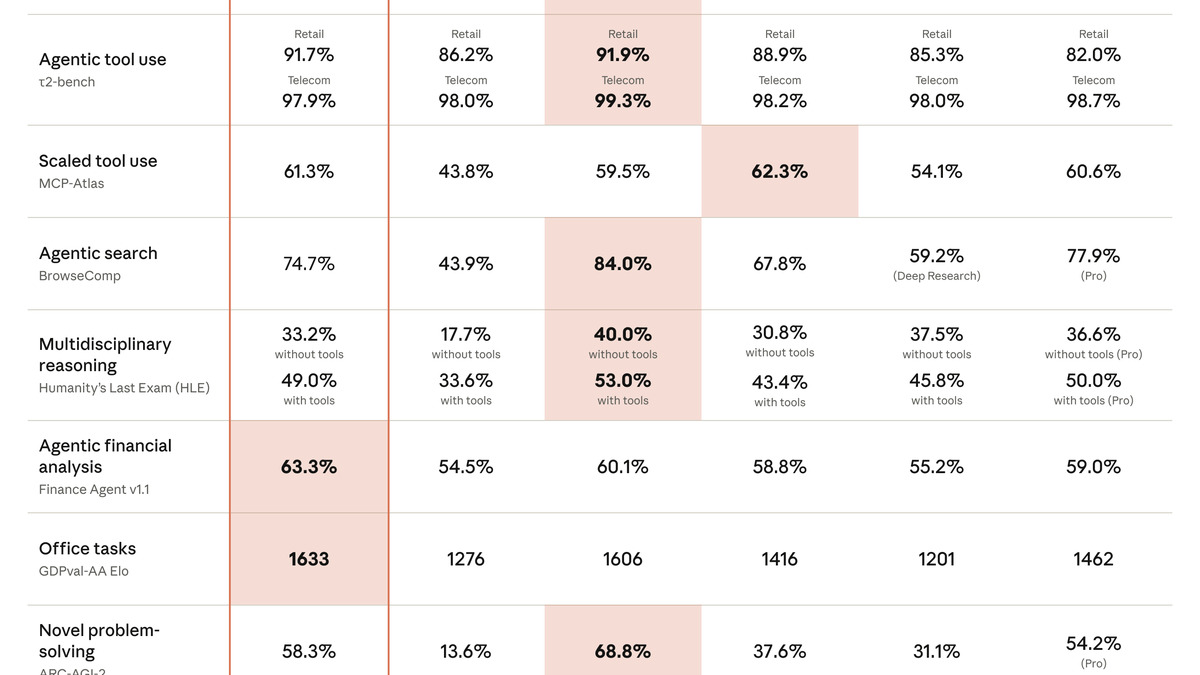 Official benchmark table from Anthropic's Claude Sonnet 4.6 announcement, showing strong coding and computer use scores.
Source: anthropic.com
Official benchmark table from Anthropic's Claude Sonnet 4.6 announcement, showing strong coding and computer use scores.
Source: anthropic.com
In Claude Code testing, developers preferred Sonnet 4.6 over Sonnet 4.5 about 70% of the time, and even over Opus 4.5 (the previous flagship) 59% of the time. For teams running AI coding assistants, those preferences reflect something real: Sonnet 4.6 handles multi-file refactoring, bug location, and test writing with a consistency that lower-tier models struggle to match.
Where Sonnet is limited compared to Flash is in input modalities. It accepts text and images, but not audio or video. For a growing category of workflows - transcription analysis, video summarization, multimedia data pipelines - that's a hard boundary. The 1M-token context window is structurally identical to Flash's, though Anthropic prices the full context at a flat per-token rate rather than tiering at 200K. Prompt caching is well-developed: cache reads cost just $0.30/MTok (10% of base), which substantially cuts costs on repeated large-context requests like codebase analysis.
Sonnet 4.6's Adaptive Thinking mode scales reasoning depth automatically, similar to Flash's dynamic thinking budget. One difference is that Anthropic doesn't expose the thinking token budget directly to API callers - it's managed internally rather than configured per-request.
Benchmark Comparison
Both models are compared below across available public benchmarks. Note that Google hasn't published a formal SWE-bench Verified score for Gemini 2.5 Flash; the coding assessment draws from available data and related model cards.
| Benchmark | Gemini 2.5 Flash | Claude Sonnet 4.6 |
|---|---|---|
| GPQA Diamond | 82.8% | 74.1% |
| MMLU (Global Lite) | 88.4% | Not published |
| AIME 2024 | 88.0% | Not published |
| SWE-bench Verified | Not published | 79.6% |
| OSWorld (computer use) | Not published | 72.5% |
| Output Speed (t/s) | ~192 | ~50 |
| Time to First Token | 0.61s | 1.16s |
The pattern is consistent across sources: Flash leads on reasoning and math; Sonnet 4.6 leads on software engineering and computer use. Those aren't random splits - they reflect different training priorities. See the coding benchmarks leaderboard for an updated view of where both models sit relative to the broader field.
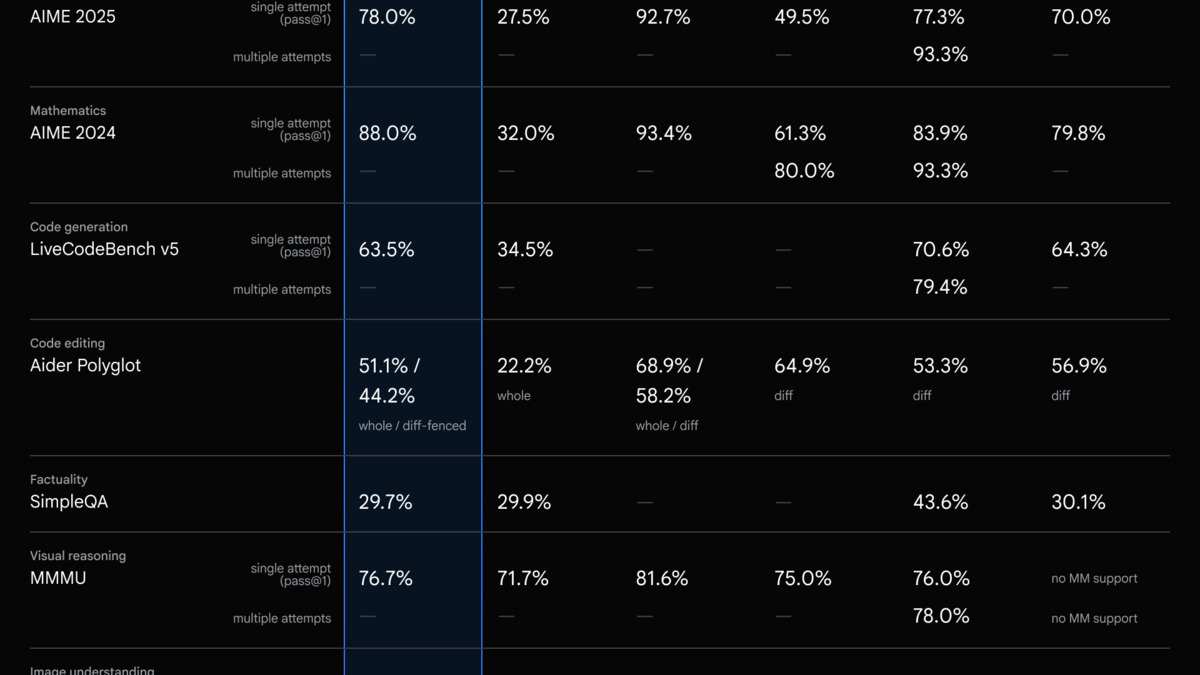 Benchmark comparison: Claude Sonnet 4.6 leads on coding tasks while Gemini 2.5 Flash holds the edge on science and math.
Source: artificialanalysis.ai
Benchmark comparison: Claude Sonnet 4.6 leads on coding tasks while Gemini 2.5 Flash holds the edge on science and math.
Source: artificialanalysis.ai
Pricing Analysis
The pricing gap between these two models is wide enough to shape architecture decisions, not just invoice totals.
| Tier | Gemini 2.5 Flash | Claude Sonnet 4.6 |
|---|---|---|
| Input (standard) | $0.30 / MTok | $3.00 / MTok |
| Output (standard) | $2.50 / MTok | $15.00 / MTok |
| Batch input | $0.15 / MTok | $1.50 / MTok |
| Batch output | $1.25 / MTok | $7.50 / MTok |
| Cache read | $0.03 / MTok | $0.30 / MTok |
| Free tier | Yes (AI Studio) | No (API) |
At standard rates, Flash input is 10x cheaper than Sonnet. Output is 6x cheaper. For a typical API call with a 3:1 input-output ratio, the blended per-token cost comes out around $0.85/MTok for Flash versus roughly $6.75/MTok for Sonnet - a 8x difference.
Flash's batch tier cuts costs further, to $0.15/$1.25/MTok, making it one of the cheaper proprietary models available for non-real-time workloads. Sonnet's batch tier ($1.50/$7.50) is meaningfully cheaper than standard but still roughly 10x above Flash standard pricing.
Where Sonnet closes the gap somewhat: prompt caching. Cache hits at $0.30/MTok mean that for repetitive large-context workloads - sending the same 100K-token codebase on every request, for example - the effective cost per new token drops much. Teams that can structure their calls around prompt caching can bring Sonnet's practical costs down 50-70% on qualifying workloads. See the cost efficiency leaderboard for a broader view of how these models rank on price-to-performance.
At Flash's batch rate of $0.15/MTok input, processing 10 million tokens costs $1.50. The same job on Sonnet 4.6 batch costs $15.00. For classification or extraction pipelines running millions of documents, that math drives the decision more than any benchmark.
Subscription Pricing
Neither model is free for API access, but both are available through consumer subscriptions. Gemini 2.5 Flash is accessible via Google AI Studio under the free tier (rate-limited), and through Gemini Advanced ($20/month) for higher throughput. Claude Sonnet 4.6 is included in Claude.ai Pro ($20/month) for chat use, but API access bills separately at the token rates above.
Pros and Cons
Gemini 2.5 Flash: Strengths
- 10x cheaper input pricing than Sonnet 4.6 at standard rates
- Output speed around 192 tokens/sec - roughly 4x faster
- Native audio and video input, enabling multimodal workflows Sonnet can't match
- Free tier via Google AI Studio for development and testing
- Adjustable thinking budget from 0 to 24,576 tokens per request
- Strong science and math benchmarks (82.8% GPQA, 88% AIME)
Gemini 2.5 Flash: Weaknesses
- No published SWE-bench Verified score; coding quality trails Sonnet 4.6 substantially
- Knowledge cutoff of January 2025 versus Sonnet's more recent training data
- Verbosity issue: artificialanalysis.ai flagged Flash as creating unusually high token volumes, which inflates output costs on longer tasks
- No native computer use capability
- Context caching storage costs apply (not just read costs)
Claude Sonnet 4.6: Strengths
- 79.6% SWE-bench Verified - the strongest score in its price tier
- Computer use and agentic tool support built into the API
- Excellent instruction following and consistent structured output
- Prompt caching at $0.30/MTok (cache reads) reduces costs on repeated contexts
- 1M context window priced flat with no tiering penalty above 200K
Claude Sonnet 4.6: Weaknesses
- $3.00/MTok input is 10x more expensive than Flash
- Output speed around 50 tokens/sec, noticeably slower in latency-sensitive applications
- No audio or video input
- No free API tier - development costs start right away
- GPQA Diamond (74.1%) and AIME performance lag behind Flash
Verdict
The fork in the road is fairly clean once you know your workload.
Choose Gemini 2.5 Flash if your application is cost-sensitive or high-volume, your input includes audio or video, or your tasks fall outside software engineering - summarization, document extraction, research assistance, multilingual processing. At $0.30/MTok input with a free development tier, the economics are hard to argue with for anything that doesn't demand top-tier coding performance.
Choose Claude Sonnet 4.6 if the core use case involves code generation, bug fixing, or agentic software tasks. A 79.6% SWE-bench score isn't gradual over Flash - it reflects a different capability level. Teams running coding agents, automated pull request reviewers, or tools that interact with real codebases will hit Flash's ceiling quickly. Sonnet's computer use support and tool call consistency add further separation for agentic pipelines.
Choose either if you need a large context window (both do 1M tokens), solid multi-step reasoning with toggleable thinking, or a general-purpose assistant for knowledge work. The quality gap narrows far outside coding and computer use.
A practical approach many teams use: route classification, summarization, and high-volume classification to Flash, then escalate complex coding and precision tasks to Sonnet. Both models are available on major cloud platforms, so routing between them at the infrastructure level is straightforward.
Sources:
- Gemini 2.5 Flash - Intelligence, Performance & Price Analysis - Artificial Analysis
- Claude Sonnet 4.6 API Provider Performance - Artificial Analysis
- Gemini Developer API Pricing - Google AI for Developers
- Pricing - Claude API Docs - Anthropic
- Gemini 2.5 Flash - Gemini API Thinking Documentation
- Claude Sonnet 4.6: 79.6% SWE-bench at $3/MTok - NxCode
- Gemini 2.5 Flash: Pricing, Context Window, Benchmarks - LLM Stats
- Claude Opus 4.6 vs Gemini 2.5 Pro: Model Comparison - Artificial Analysis
✓ Last verified April 10, 2026

