Claude vs Gemini 2026: Full Comparison and Verdict
A benchmark-driven comparison of Claude Opus 4.7 and Gemini 3.1 Pro across coding, reasoning, pricing, and multimodal capabilities in 2026.

The two most credible alternatives to OpenAI's flagship models are Anthropic's Claude and Google's Gemini. Both have overhauled their lineups in 2026 - Gemini 3.1 Pro launched in February, Claude Opus 4.7 followed in April - and they've converged on the same context window (1M tokens), the same ballpark pricing tier, and the same developer-friendly tooling. That makes the comparison harder than it looks on the surface.
TL;DR
- Claude wins on coding (87.6% vs 80.6% SWE-bench Verified) and hallucination rate (36% vs 50%)
- Gemini wins on multimodal tasks, science reasoning (94.3% GPQA Diamond), and API cost (roughly 2x cheaper at flagship tier)
- If you write code or prose for a living, pick Claude; if you process documents, video, or audio at scale, pick Gemini
At a Glance
| Feature | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|
| Release date | April 16, 2026 | February 19, 2026 |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K tokens | 64K tokens |
| API input price | $5.00 / MTok | $2.00 / MTok (≤200k) |
| API output price | $25.00 / MTok | $12.00 / MTok |
| Batch discount | 50% off | 50% off |
| Native video/audio | No | Yes |
| BenchLM overall | 90 | 92 |
| SWE-bench Verified | 87.6% | 80.6% |
| GPQA Diamond | - | 94.3% |
| Hallucination rate | 36% | 50% |
Both have 1M context windows at standard pricing, prompt caching, and asynchronous batch APIs. The architectural differences show up in the category breakdowns below.
Pricing: API and Consumer
API costs
At the flagship tier, Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens. Gemini 3.1 Pro costs $2 per million input tokens (for prompts up to 200k tokens) and $12 per million output tokens - roughly 2.1x cheaper on output alone. Above 200k tokens, Gemini's input price climbs to $4 per million, which partially closes the gap.
Both providers offer a 50% batch API discount for async workloads. Prompt caching is available on both - Claude's cache hit costs 10% of the input rate, Gemini's pricing structure is similar. For most production applications that stay below 200k tokens and cache aggressively, Gemini is meaningfully cheaper.
Below the flagship tier, Google's budget models are more aggressive. Gemini 2.5 Flash runs $0.30 per million input tokens and $2.50 per million output tokens. Gemini 2.5 Flash-Lite drops to $0.10 input and $0.40 output. Claude's equivalent, Claude Haiku 4.5, costs $1 input and $5 output - still capable, but more expensive than the Gemini Flash tier.
| Model | Input ($/MTok) | Output ($/MTok) |
|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Gemini 3.1 Pro | $2.00 | $12.00 |
| Gemini 3.5 Flash | $1.50 | $9.00 |
| Gemini 2.5 Flash | $0.30 | $2.50 |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 |
Consumer subscriptions
Claude Pro costs $20 per month with daily usage caps. Claude Max goes to $100 per month (5x usage) or $200 per month (20x usage). There's a free tier with message limits.
Google restructured its consumer AI offerings in 2025. Google AI Pro, which includes Gemini 3.1 Pro with a 1M token context window, costs $19.99 per month - functionally the same price as Claude Pro. Google AI Ultra at $249.99 per month adds Deep Think, Veo video generation, and 30TB storage. There's also a new Google AI Plus tier at $7.99 per month for lighter usage.
At the standard $20 price point, Gemini Advanced includes Gemini 3.1 Pro with native multimodal capabilities. Claude Pro gives Sonnet 4.6 access with limited Opus 4.7. For power users who need the flagship model, both providers charge a similar premium.
Benchmarks: Where Each Model Leads
Coding
This is Claude's clearest advantage. On SWE-bench Verified, which tests real GitHub issue resolution, Claude Opus 4.7 scores 87.6% versus Gemini 3.1 Pro's 80.6%. On SWE-bench Pro (a harder variant), Claude leads 64.3% to 54.2%.
On agentic tool use - specifically the MCP Atlas benchmark - Claude scores 77.3% against Gemini's 73.9%. Our SWE-bench coding agent leaderboard tracks these scores as models update. That gap compounds in multi-step coding agents where Claude's instruction-following and file-system memory capabilities translate into fewer failed steps.
In practice, Claude produces cleaner, more idiomatic code and handles large codebases more consistently. Gemini is strong on competitive programming tasks but less reliable in the kind of refactoring and debugging work that fills most production sprints.
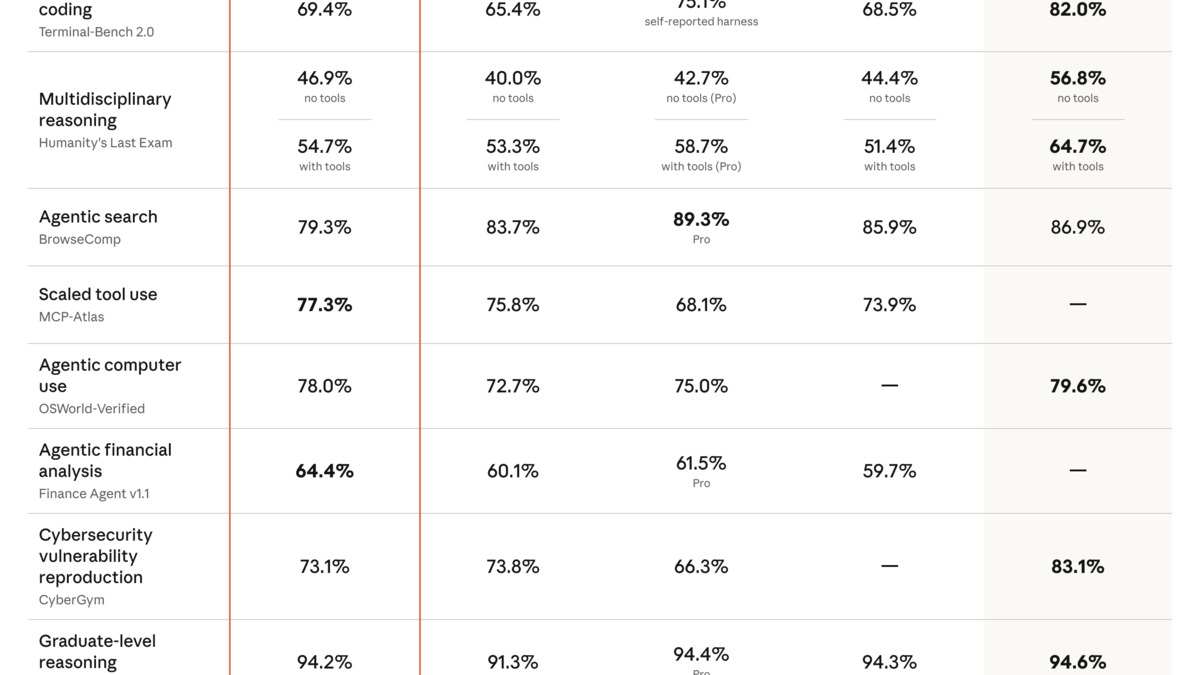 Anthropic's benchmark data for Claude Opus 4.7, showing strong coding performance relative to competing flagship models.
Source: anthropic.com
Anthropic's benchmark data for Claude Opus 4.7, showing strong coding performance relative to competing flagship models.
Source: anthropic.com
Science and Reasoning
Gemini 3.1 Pro leads here. Its GPQA Diamond score - PhD-level questions across biology, chemistry, and physics - is 94.3%, which is the highest of any commercially available model. On the BenchLM reasoning category, Gemini scores 77.1 versus Claude's 75.8.
Claude Opus 4.7 has a hallucination rate of 36% on the AA-Omniscience benchmark. Gemini 3.1 Pro's is 50%, which matters a lot if you're building retrieval pipelines or research workflows where confident wrong answers are more dangerous than uncertain correct ones.
Gemini leads on reasoning benchmarks. Claude leads on reliability - its 36% hallucination rate versus Gemini's 50% is a real difference in production.
Multimodal
Gemini wins, and it isn't close. Gemini 3.1 Pro's BenchLM multimodal and grounded score is 82.8 versus Claude's 64.3. The CharXiv chart-reading benchmark shows an even wider gap: 91% for Gemini versus 80.2% for Claude.
The reason is architectural. Gemini 3.1 Pro is natively multimodal - it processes text, images, video, and audio in a single prompt without transcription intermediaries. It accepts up to 900 images per prompt, up to 8.4 hours of audio, and up to one hour of video. Claude Opus 4.7 handles images and documents well but has no native video or audio understanding. If your pipeline involves media processing, that limits Claude's usefulness.
 Claude's interface on claude.ai, emphasizing its strong instruction-following and long context capabilities.
Source: anthropic.com
Claude's interface on claude.ai, emphasizing its strong instruction-following and long context capabilities.
Source: anthropic.com
Context Window and Long Document Work
Both models support 1M tokens at standard pricing, which is the same story they've told for most of 2026. The difference is in output: Claude Opus 4.7 can produce up to 128K output tokens in a single response - roughly 90,000 words. Gemini 3.1 Pro tops out at 64K output tokens.
For most use cases, neither limit matters. But for long-form document generation or agentic coding tasks that produce extended output, Claude's higher output ceiling is an edge.
Gemini's long-context pricing has a standout quirk: above 200k input tokens, the input price doubles from $2 to $4 per million tokens. Claude charges the same rate across the full context window. For workloads that routinely hit 500k to 1M tokens, that makes Claude's total cost more predictable.
Enterprise and Ecosystem
Gemini has a structural advantage for teams already in Google's stack. Gemini 3.1 Pro integrates natively with Google Workspace, BigQuery, Vertex AI, and Google Cloud Platform. If your organization runs on Google Sheets, Docs, and Drive, the integration surface is already there.
Claude integrates with Amazon Bedrock and Vertex AI, and Anthropic has been expanding its enterprise partnerships. Claude Code - the coding agent tool - has a strong following among developers on both VS Code and JetBrains. Anthropic's Claude Managed Agents API, billed at $0.08 per session-hour plus token costs, provides a structured framework for multi-step agentic tasks.
For pure API reliability and response consistency, both models are production-grade. Claude's safety tuning tends to produce fewer refusals on ambiguous professional content, which matters in legal, medical, and financial applications.
Head-to-Head: Which Should You Choose?
Pick Claude Opus 4.7 if:
- Coding is a primary workload (87.6% vs 80.6% SWE-bench)
- Writing quality and instruction-following precision matter
- Hallucination reduction is critical for your application (36% vs 50%)
- You need long output in a single response (128K vs 64K tokens)
- You're building agentic pipelines with MCP tooling
Pick Gemini 3.1 Pro if:
- You're processing images, video, or audio natively
- Budget matters and you're staying under 200k tokens per request (2x cheaper)
- Your org runs on Google Cloud or Workspace
- Science, math, or multilingual reasoning is a core need
- You want the broadest media type support in a single model
Pick a budget Gemini model if:
- Cost is the top constraint and task complexity is medium
- Gemini 2.5 Flash at $0.30/$2.50 per MTok handles most summarization, classification, and document processing tasks well
For teams that need both capabilities - Gemini for media ingestion, Claude for code generation and analysis - a hybrid approach is worth the routing complexity. Claude Sonnet 4.6 at $3/$15 per MTok sits close to Gemini 3.1 Pro on many benchmarks while bringing Claude's coding strengths, and a three-way comparison that includes ChatGPT is worth reading in our Claude vs ChatGPT 2026 breakdown.
Sources
- Anthropic Claude API Pricing
- Gemini Developer API Pricing
- Claude Opus 4.7 vs Gemini 3.1 Pro - BenchLM
- Gemini 3.1 Pro Model Card - Google DeepMind
- Claude vs Gemini 2026: SWE-bench Tested
- Claude Opus 4.7 Launch Analysis - LLM Stats
- Gemini 3.1 Pro vs Claude Opus 4.7 - LLM Stats
- AI Subscription Pricing Compared 2026
- Claude vs ChatGPT vs Copilot vs Gemini Enterprise - IntuitionLabs
- Gemini vs Claude Multimodal Comparison - Zemith
- Claude Opus 4.7 vs Gemini 3.1 Pro - OpenRouter
✓ Last verified May 19, 2026
