Claude Fable 5 vs Gemini 3.5 Flash: Power vs Speed
A benchmark-driven comparison of Claude Fable 5 and Gemini 3.5 Flash across coding, agents, pricing, and speed - two models built for opposite priorities.

Claude Fable 5 and Gemini 3.5 Flash launched within three weeks of each other in mid-2026 and promptly became the most-discussed pairing in AI infrastructure discussions. They're priced 5-7x apart, run at very different speeds, and excel in different benchmark categories. Choosing between them isn't a question of which model is "better" - it's a question of what your workload actually looks like. This comparison walks through the numbers, the tradeoffs, and when each model makes sense.
TL;DR
- Choose Fable 5 if your work centers on complex, multi-file software engineering or long-horizon analytical tasks where a single high-quality output is worth $50/M output tokens
- Choose Gemini 3.5 Flash if you're running high-volume agentic pipelines, need multimodal inputs (audio, video, PDF), or can't afford 4x the latency at 6x the cost
- Fable 5 scores 80.3% on SWE-bench Pro vs Flash's 55.1%; Flash responds at 289 tok/s vs Fable 5's ~73 tok/s and costs $9/M output vs $50/M
Quick Comparison Table
| Feature | Claude Fable 5 | Gemini 3.5 Flash |
|---|---|---|
| Provider | Anthropic | Google DeepMind |
| Released | June 9, 2026 | May 19, 2026 |
| Context Window | 1M tokens | 1M tokens (1,048,576) |
| Max Output | 128K tokens | 64K tokens |
| Input Price | $10.00/M | $1.50/M |
| Output Price | $50.00/M | $9.00/M |
| Cached Input | $1.00/M (90% off) | $0.15/M (90% off) |
| Output Speed | ~73 tok/s | ~289 tok/s |
| SWE-bench Pro | 80.3% | 55.1% |
| MCP Atlas | Not published | 83.6% |
| Free Tier | No | Yes (AI Studio) |
| Input Modalities | Text, image, PDF | Text, image, audio, video, PDF |
| Best For | Complex coding, long tasks | High-volume agents, multimodal |
Claude Fable 5
Claude Fable 5 is the first Mythos-class model Anthropic made publicly available, launched on June 9, 2026. It's a heavy model designed for tasks where quality is the binding constraint - complex software engineering, dense analytical work, and long-horizon agentic sessions where cheaper models lose coherence or make critical errors.
The headline benchmark number is SWE-bench Pro at 80.3%. That's an 11-point jump over Claude Opus 4.8's 69.2%, and a 25-point lead over Gemini 3.5 Flash at 55.1%. On FrontierCode - Cognition's hardest public coding evaluation - Fable 5 scores 29.3%, more than double the nearest published competitor. Per DataCamp testing, it also reaches 88.0% on Terminal-Bench 2.1, a full 12 points above Flash's 76.2%.
The safety architecture shapes what you can actually do with the model. Classifiers monitor requests in three domains - cybersecurity, biology/chemistry, and model distillation - and can reroute flagged sessions to Claude Opus 4.8 rather than answering with full Mythos-class capability. Anthropic says fewer than 5% of sessions trigger any fallback. When a reroute does happen, you pay Opus 4.8 rates for that specific request. The 30-day mandatory data retention requirement is a harder constraint for some organizations: it can block deployment in regulated industries, especially on Amazon Bedrock where opting into retention moves data outside AWS's standard security boundary.
One context point that matters right now: Fable 5 was suspended from June 12 to June 30, 2026, after the US government applied export controls requiring Anthropic to restrict access to foreign nationals. The controls were lifted June 30, and Anthropic redeployed the model on July 1 with an improved safety classifier that blocks the previously reported bypass technique in over 99% of cases. If you were testing Fable 5 in mid-June and hit the suspension, the model you're accessing now is both updated and more reliably available.
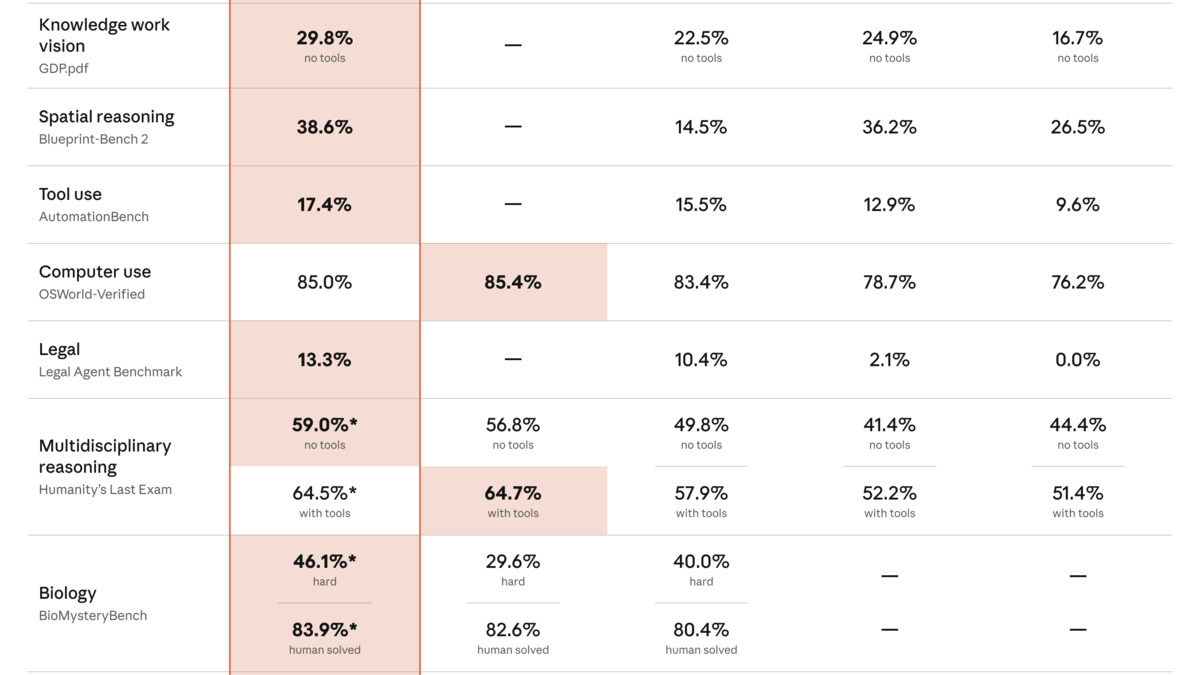 Anthropic's benchmark comparison at the Fable 5 launch on June 9, 2026, showing results against Claude Opus 4.8 and GPT-5.5.
Source: anthropic.com
Anthropic's benchmark comparison at the Fable 5 launch on June 9, 2026, showing results against Claude Opus 4.8 and GPT-5.5.
Source: anthropic.com
Pricing is $10/M input, $50/M output. Batch pricing halves that. Prompt caching drops cached input to $1/M - a 90% reduction that makes repeated long-context calls significantly cheaper for workflows that reuse large system prompts or document contexts. Available on the Claude API, GitHub Copilot, Amazon Bedrock, Google Cloud, and Microsoft Foundry.
Gemini 3.5 Flash
Gemini 3.5 Flash launched May 19 at Google I/O 2026 as Google DeepMind's fastest frontier model. Its position in the market is different from Fable 5's in almost every dimension: cheaper, faster, weaker on complex coding but stronger on tool orchestration, and designed to run efficiently at scale rather than to achieve maximum depth on a single hard problem.
The 289 tokens-per-second output speed is real and it matters operationally. Frontier models like Fable 5 and GPT-5.5 typically run at 70-80 tok/s. Flash's 4x speed advantage means agentic pipelines that spawn many parallel subagents can complete in a quarter of the wall-clock time. For interactive products where latency determines user experience, or for pipelines where hundreds of model calls happen per task, that gap builds up.
On agentic benchmarks, Flash leads the field in categories where parallel tool execution and multi-service coordination are the core skill. MCP Atlas - which tests reliable tool-use across hundreds of tasks - comes in at 83.6%, above Claude Opus 4.7's 79.1% and GPT-5.5's reported figures. Finance Agent v2 at 57.9% and CharXiv Reasoning at 84.2% (competing charts and scientific figures) are further signals of where the model performs.
The configurable thinking parameter is worth understanding: Flash ships with four thinking levels (minimal, low, medium, high), and defaults to medium. That default handles multi-step agent tasks without ballooning latency. Dialing down to minimal gives you the fastest, cheapest inference for high-volume triage tasks. Dialing up to high brings more reasoning depth for harder problems, at the cost of speed and tokens. Fable 5 doesn't expose this dial - its thinking depth is fixed, and you pay full price whether the task needs all of it or not.
Multimodal input is broader than Fable 5 across text, image, audio, video, and PDF. Output is text only. The 64K maximum output token limit (vs Fable 5's 128K) can be a constraint for tasks that create large code files or long reports in a single response.
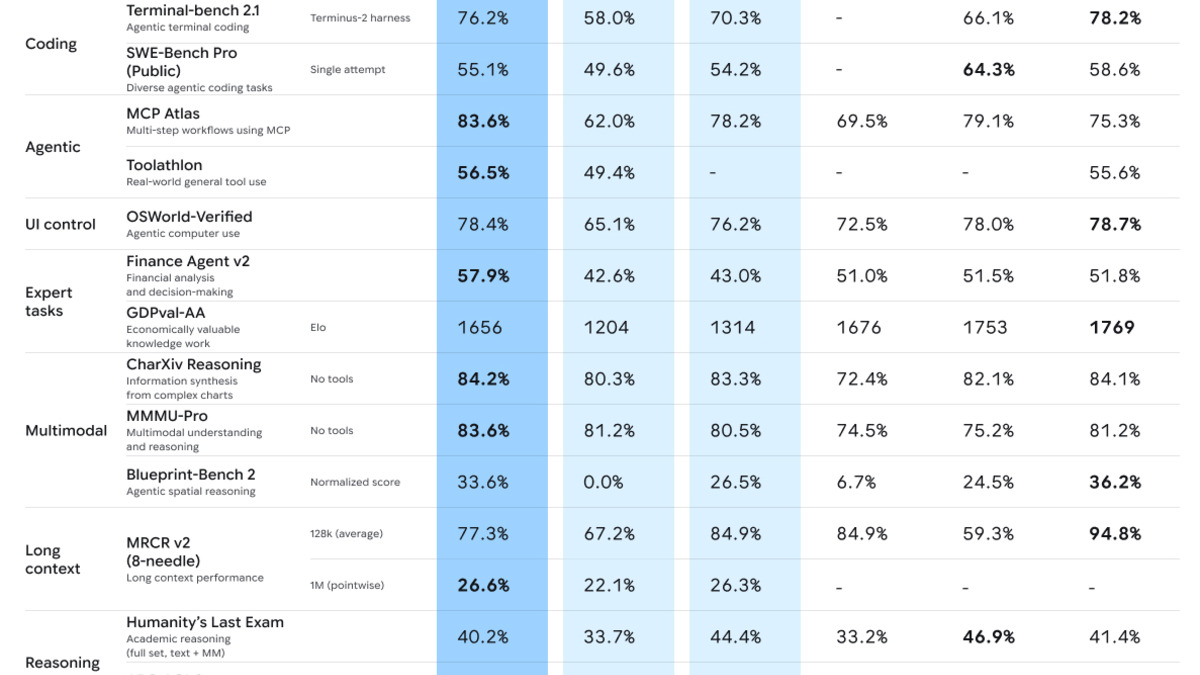 Google's published benchmark results for Gemini 3.5 Flash from the I/O 2026 launch, comparing against Gemini 3.1 Pro and prior Flash models.
Source: blog.google
Google's published benchmark results for Gemini 3.5 Flash from the I/O 2026 launch, comparing against Gemini 3.1 Pro and prior Flash models.
Source: blog.google
Benchmark Comparison
The benchmark picture splits clearly along a depth-versus-throughput line.
| Benchmark | Claude Fable 5 | Gemini 3.5 Flash |
|---|---|---|
| SWE-bench Pro | 80.3% | 55.1% |
| FrontierCode | 29.3% | n/a |
| Terminal-Bench 2.1 | 88.0% (DataCamp) | 76.2% |
| MCP Atlas | n/a | 83.6% |
| ARC-AGI-2 | n/a | 72.1% |
| CharXiv Reasoning | n/a | 84.2% |
| MMMU-Pro | n/a | 83.6% |
| Finance Agent v2 | n/a | 57.9% |
| GDPval-AA (Elo) | n/a | 1,656 |
| Humanity's Last Exam | 64.5% (with tools) | 40.2% |
Fable 5 dominates the coding benchmarks. The 25-point gap on SWE-bench Pro is large, and FrontierCode is the most demanding public coding evaluation available - that 29.3% score isn't matched by any other published model. Terminal-Bench 2.1 at 88.0% (per DataCamp's independent testing) is 12 points above Flash.
Flash leads on the agentic coordination benchmarks. MCP Atlas at 83.6% reflects genuine strength in multi-tool deployment, and that score beats Claude Opus 4.7's 79.1% on the same evaluation. CharXiv and MMMU-Pro show strong multimodal reasoning.
The Humanity's Last Exam row needs a caveat: the numbers aren't directly comparable. Fable 5's 64.5% is a "with tools" result (agents can call external tools during the exam); Flash's 40.2% is the published score from Google's model card under standard evaluation conditions. With tools enabled, Flash would score higher than 40.2% too. I've included both because they're the published figures - just don't read the gap as a raw capability comparison.
Check the coding benchmarks leaderboard and agentic AI benchmarks leaderboard for updated standings as more independent evaluations come in.
Pricing Analysis
The cost difference between these two models is sizable. Here's how it breaks down across different workload types.
| Pricing Tier | Claude Fable 5 | Gemini 3.5 Flash |
|---|---|---|
| Input (standard) | $10.00/M | $1.50/M |
| Output (standard) | $50.00/M | $9.00/M |
| Input (batch) | $5.00/M | $0.75/M |
| Output (batch) | $25.00/M | $4.50/M |
| Cached input | $1.00/M | $0.15/M |
| Context storage | Not published | $1.00/M token-hours |
For a workload producing 1M output tokens at standard rates:
- Fable 5: $50.00
- Gemini 3.5 Flash: $9.00
The 5.6x output cost difference is what most production decisions come down to. Input is usually not the binding cost - for tasks with heavy prompting and short responses, the gap narrows to the 6.7x input difference ($10 vs $1.50).
Caching changes the math for both. If your system prompt is 100K tokens and you're running 1,000 requests per day against the same context, the cached input cost per million tokens is $1.00 for Fable 5 and $0.15 for Flash. The ratio stays the same; Flash's absolute advantage is just as large.
The free tier is only on Flash's side. Google AI Studio gives access to Gemini 3.5 Flash with daily request limits and no credit card required. Fable 5 has no free tier; access requires an Anthropic account and API credits, or a Claude subscription plan with usage credits after June 23.
Fable 5 costs 5.6x more per output token than Gemini 3.5 Flash at standard pricing. For high-volume pipelines, that gap outweighs any benchmark advantage.
Pros and Cons
Claude Fable 5: Strengths
- SWE-bench Pro at 80.3% is the highest published score on complex software engineering tasks
- FrontierCode at 29.3% is more than 2x any other published competitor
- 128K output token limit handles large single-response code generation
- Available on GitHub Copilot, Bedrock, Google Cloud, and Microsoft Foundry from day one
- Improved safety classifier after June 30 redeployment blocks reported bypass in 99%+ of cases
Claude Fable 5: Weaknesses
- $50/M output is 5.6x more expensive than Flash - cost-prohibitive for high-volume pipelines
- ~73 tok/s output speed makes it unsuitable for latency-sensitive interactive products
- Safety classifier can reroute requests to Opus 4.8 without notice in cybersecurity and bio/chem domains
- 30-day mandatory data retention blocks some regulated industry deployments
- Export control suspension (June 12-30) showed the model's availability isn't guaranteed
Gemini 3.5 Flash: Strengths
- 289 tok/s output speed is 4x faster than typical frontier models
- $9/M output enables high-volume pipelines that would be cost-prohibitive with Fable 5
- 83.6% on MCP Atlas leads the field in multi-tool agentic coordination
- Native audio, video, and PDF input - broadest multimodal input range of the two models
- Configurable thinking levels let you trade quality for speed per call
- Free tier on Google AI Studio with no credit card required
Gemini 3.5 Flash: Weaknesses
- SWE-bench Pro at 55.1% is 25 points behind Fable 5 on complex multi-file code changes
- Long-context retrieval degrades at 1M tokens (26.6% on MRCR v2 vs 77.3% at 128K)
- 64K max output can be a ceiling for tasks that generate large code outputs in one pass
- No Computer Use support - this requires the separate gemini-3-flash-preview variant
Verdict
If your workload is mainly software engineering - refactoring large codebases, completing long agentic coding sessions, or handling complex multi-file changes - Fable 5 is the right choice. The 25-point SWE-bench Pro gap is too large to attribute to evaluation noise, and FrontierCode's results are consistent with a model that reasons through difficult code problems at a different level than Flash does. The cost is real, but for tasks where one wrong output means hours of debugging, paying $50/M output makes economic sense.
If you're building pipelines that need to run many calls in parallel, process varied media types, or operate at scale where $9/M output vs $50/M output directly determines whether a product is viable - Flash is the right choice. Its 4x speed advantage compounds in multi-agent architectures. Enterprise workloads with strict zero-retention requirements can only use Flash (Fable 5's 30-day retention is a hard constraint in those environments).
Choose Fable 5 if you're doing repository-scale coding work, deep analytical tasks across long contexts, or any task where maximum output quality justifies premium pricing.
Choose Flash if you're running high-volume agentic pipelines, need audio or video inputs, care about latency in user-facing products, or need a free tier to prototype.
Choose either if your workload falls in the middle - moderate-length coding tasks, standard document processing, general-purpose AI assistants. Both models are more than capable for everyday tasks. At that point, the decision probably comes down to your existing infrastructure (Google Cloud vs AWS/Anthropic API) and pricing tolerance.
Sources:
- Claude Fable 5 and Mythos 5 - Anthropic
- Redeploying Claude Fable 5 - Anthropic
- Gemini 3.5: frontier intelligence with action - Google Blog
- Claude Fable 5 vs Gemini 3.5 Flash: AI Benchmark Comparison - BenchLM
- Claude Fable 5 - OpenRouter
- Gemini 3.5 Flash - OpenRouter
- Claude Fable 5 Performance Analysis - Artificial Analysis
- Anthropic Claude Fable 5 on AWS - Amazon Web Services Blog
- Gemini 3.5 Flash Model Card - Google DeepMind
- Google says Gemini 3.5 Flash rivals flagship models for coding and agentic tasks - Engadget
✓ Last verified July 2, 2026
