Best Coding Models on OpenRouter - Opus 4.7 Rivals
Claude Opus 4.7 scores 87.6% on SWE-bench Verified but costs $5/$25 per million tokens. These four models match or near-match its coding performance at a fraction of the price on OpenRouter.

Claude Opus 4.7 is the current benchmark leader for complex coding work. On SWE-bench Verified - the most widely cited real-world coding benchmark - it scores 87.6%, higher than every publicly available model except GPT-5.5. The problem is cost: $5 per million input tokens and $25 per million output tokens on OpenRouter. For agentic pipelines that burn thousands of output tokens per task, that adds up fast.
TL;DR
- Gemini 3.1 Pro hits 80.6% SWE-bench Verified at $2/$12 - the strongest value-per-dollar pick for most teams
- Kimi K2.6 matches Gemini at 80.2% for $0.75/$3.50 and is built specifically for long-horizon agentic coding
- DeepSeek V4 Pro runs at $0.435/$0.87 with 80.6% SWE-bench - the cheapest path to near-frontier coding
- GPT-5.5 technically beats Opus 4.7 (88.7% vs 87.6%) but costs more on output tokens, so it isn't a cost-saving swap
- All models in this article are available on OpenRouter as of May 2026
This roundup covers the realistic alternatives. "Realistic" means available on OpenRouter today, with verified benchmark numbers and transparent pricing - not leaked previews or self-reported scores from a vendor blog post.
The Benchmark That Actually Matters
SWE-bench Verified is the metric we're using here. It measures whether a model can resolve real GitHub issues submitted by open-source developers - writing a patch, running tests, getting to green. The "Verified" variant uses a subset of problems that human annotators confirmed are actually solvable, which removes the noise from poorly specified or ambiguous issues.
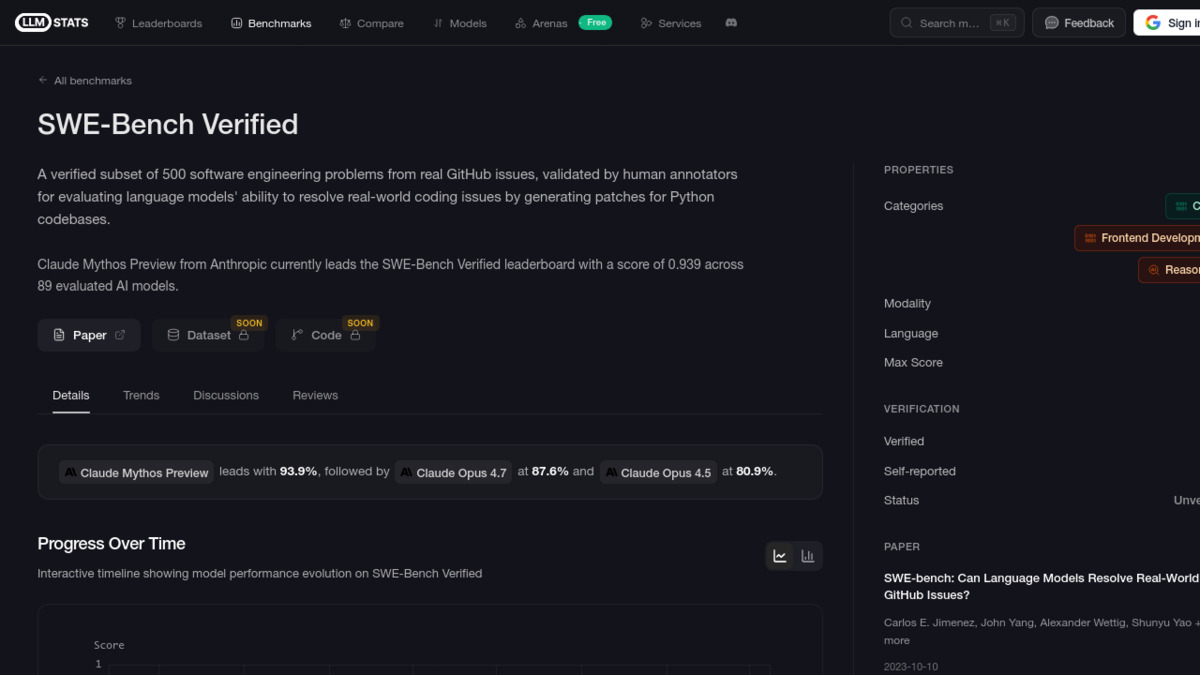 SWE-bench Verified top performers as of May 2026, sorted by score. Claude Opus 4.7 holds the #2 spot behind Claude Mythos Preview, which isn't publicly available.
Source: llm-stats.com
SWE-bench Verified top performers as of May 2026, sorted by score. Claude Opus 4.7 holds the #2 spot behind Claude Mythos Preview, which isn't publicly available.
Source: llm-stats.com
It's not the only benchmark that matters. SWE-bench Pro uses messier, more realistic codebases from multiple languages. TerminalBench measures terminal command execution. LiveCodeBench Pro tests competitive programming. We'll note where models diverge from their SWE-bench Verified ranking on those dimensions.
The key numbers for Claude Opus 4.7:
| Spec | Value |
|---|---|
| SWE-bench Verified | 87.6% |
| SWE-bench Pro | 64.3% |
| Input price | $5.00/M tokens |
| Output price | $25.00/M tokens |
| Context window | 1M tokens |
Every model in this article was benchmarked against those numbers. The goal is to find the crossover point where you're accepting a meaningful but tolerable performance drop in exchange for a significant cost reduction.
Gemini 3.1 Pro - Best Value for Most Teams
Gemini 3.1 Pro ($2/$12 on OpenRouter) scores 80.6% on SWE-bench Verified. That's 7 percentage points below Opus 4.7 and costs 60% less on input tokens. For teams running agent pipelines where output costs dominate, the $12 versus $25 output difference is the number that actually moves the budget.
The model carries a 1M token context window matching Opus 4.7, which matters for long-horizon coding tasks where you're loading full codebases into a single context. It also leads the field on SWE-bench Pro with more realistic, messier codebases - the benchmark that maps most closely to production work rather than clean GitHub issues.
Gemini 3.1 Pro posts a 93.9% coding ranking on LM Council's benchmark weighted score, behind only Opus 4.7 at 95.2%. On SWE-bench Pro with realistic multi-language codebases, it leads at 72 vs GPT-5.4's 57.7.
On LiveCodeBench Pro, Gemini 3.1 Pro posts a 2887 Elo. That's the competitive programming benchmark, and Gemini's edge there matters if your use case leans toward algorithmic work rather than issue resolution.
The current OpenRouter listing is google/gemini-3.1-pro-preview, which means it's still in preview and availability can vary. For teams needing guaranteed uptime, factor that in.
Best for: Coding agent pipelines where output token volume is high and context window size matters. Teams currently on Opus 4.7 for multi-file refactoring will see the smallest regression here.
Kimi K2.6 - Best Open-Weight Option
Kimi K2.6 ($0.75/$3.50 on OpenRouter) scores 80.2% on SWE-bench Verified and 58.6% on SWE-bench Pro, which puts it ahead of GPT-5.4 (57.7%) on the harder benchmark. That's a significant result for a model at this price point.
Moonshot AI designed K2.6 specifically for agentic coding work - the model uses agent traces and multi-step tool use to handle tasks that involve navigating large codebases, running tests, and making iterative fixes. In practice, this shows up as stronger performance on tasks requiring 10-20 sequential actions rather than single-shot code generation.
 Kimi K2.6's multi-agent architecture handles long-horizon coding tasks through coordinated agent traces, rather than single-pass generation.
Source: buildfastwithai.com
Kimi K2.6's multi-agent architecture handles long-horizon coding tasks through coordinated agent traces, rather than single-pass generation.
Source: buildfastwithai.com
The model is open-weight, which means you can self-host it if OpenRouter pricing or availability is a concern. For teams with the infrastructure to run 1T-parameter MoE models, the open-weight option removes vendor dependency completely.
At $0.75/$3.50, the math is aggressive compared to Opus 4.7: you're paying 85% less on input and 86% less on output for 92% of the SWE-bench Verified score.
Best for: Agentic coding workflows. Teams already using Claude Code or similar frameworks for multi-step coding automation will get the most out of K2.6's architecture. The open-weight option is relevant for teams with data residency requirements.
DeepSeek V4 Pro - Lowest Cost Path to Frontier
DeepSeek V4 in its Pro configuration scores 80.6% on SWE-bench Verified - matching Gemini 3.1 Pro exactly - at $0.435 input and $0.87 output per million tokens on OpenRouter. That's the cheapest route to near-frontier coding performance currently available.
The model runs as a 1.6T-parameter MoE with 49B activated parameters and a 1M token context window. The "Pro Max" configuration enables extended reasoning, which pushes SWE-bench Verified to 80.6% and SWE-bench Pro performance matching other frontier models.
DeepSeek V4 Pro costs $3.48 per million output tokens through DeepInfra's hosted version - versus $25 for Claude Opus 4.7. The SWE-bench Verified gap is 7 percentage points.
The OpenRouter listing notes that the 75% promotional pricing (which put it at $0.435/$0.87) expired on May 5, 2026. Current pricing through OpenRouter is through provider routing; check openrouter.ai/deepseek/deepseek-v4-pro for the current rate. Even at full price through DeepInfra, the output cost is roughly one-seventh of Opus 4.7's $25.
DeepSeek V4 Flash is a lighter variant at $0.14/$0.28 with slightly lower benchmark performance. If your tasks are less demanding, it's worth testing - the cost reduction is dramatic and the performance degradation may not matter for simpler issue resolution.
Best for: High-volume coding pipelines where cost is the primary constraint. Research teams, CI/CD automation, and any application where you're running hundreds of coding tasks per day.
GPT-5.5 - When Performance Is the Only Variable
GPT-5.5 scores 88.7% on SWE-bench Verified - 1.1 percentage points above Opus 4.7. On SWE-bench Pro it scores in a comparable range. If raw benchmark performance is the only variable you're optimizing for, this is currently the top publicly available model for coding.
The problem: it costs $5 per million input tokens and $30 per million output tokens. That makes it more expensive than Opus 4.7 on output, which is where most of the cost in agentic pipelines accumulates. It's not a cheaper alternative - it's a marginal improvement at higher cost.
| Metric | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| SWE-bench Verified | 88.7% | 87.6% |
| Input price | $5.00/M | $5.00/M |
| Output price | $30.00/M | $25.00/M |
There are specific cases where the marginal 1.1% SWE-bench advantage matters. If you're building a commercial coding product where success rate directly affects revenue, and you're willing to absorb the cost difference, GPT-5.5 is worth testing. For most internal tooling and development automation, the difference won't be detectable in production.
Best for: Commercial coding products where the highest achievable success rate justifies the cost premium.
Full Comparison Table
| Model | SWE-Bench Verified | Input $/M | Output $/M | Context |
|---|---|---|---|---|
| GPT-5.5 | 88.7% | $5.00 | $30.00 | 200K |
| Claude Opus 4.7 | 87.6% | $5.00 | $25.00 | 1M |
| Claude Opus 4.6 | 80.8% | $5.00 | $25.00 | 1M |
| Gemini 3.1 Pro | 80.6% | $2.00 | $12.00 | 1M |
| DeepSeek V4 Pro (Max) | 80.6% | $0.435 | $0.87 | 1M |
| MiniMax M2.5 | 80.2% | $0.30 | $1.20 | 1M |
| Kimi K2.6 | 80.2% | $0.75 | $3.50 | 128K |
| GPT-5.4 | 78.2% | $2.50 | $15.00 | 200K |
| MiMo-V2-Pro | 78.0% | $1.00 | $3.00 | 1M |
| DeepSeek V4 Flash | ~79% | $0.14 | $0.28 | 1M |
A few notes on this table. Claude Opus 4.6 costs the same as Opus 4.7 ($5/$25) and scores 80.8% - it's on the table to show that simply using the previous generation within the same family doesn't save money. MiniMax M2.5 and MiMo-V2-Pro are both worth testing for budget-constrained teams - M2.5 in particular is a 230B MoE model that hits 80.2% at $0.30/$1.20, making it the cheapest near-frontier option in the table.
How to Choose
The decision comes down to two variables: how close to Opus 4.7's performance you actually need, and whether your cost is driven by input or output tokens.
For multi-file, long-context coding tasks: Gemini 3.1 Pro or Opus 4.7 itself. Both have 1M context windows. K2.6's 128K context window is a real constraint for large codebase tasks.
For agentic workflows that burn output tokens: DeepSeek V4 Pro. The $0.87 output price versus $25 is a roughly 29x difference. If your agent runs 20 tool calls and generates 2K tokens each, that math compounds quickly.
For open-weight and self-hosting: Kimi K2.6. It's the strongest open-weight model at this price point with verified SWE-bench scores.
For teams already on Opus 4.7 with occasional complex tasks: Run A/B tests with Gemini 3.1 Pro first. The 7-point SWE-bench gap may be invisible in your specific use case, or it may matter a lot - you won't know without testing against your actual workload.
Agent scaffolding and tooling matter as much as the raw model. The best AI coding CLI tools comparison covers the agentic layers on top of these models, and how the harness can move benchmark scores by 20+ points on the same underlying model.
FAQ
Is Gemini 3.1 Pro available on OpenRouter?
Yes, as google/gemini-3.1-pro-preview. It's in preview status as of May 2026, which means availability may vary. Check the OpenRouter status page before building on it for production use.
Does DeepSeek V4 Pro still have the 75% discount?
The 75% promotional pricing expired on May 5, 2026. Check openrouter.ai/deepseek/deepseek-v4-pro for current rates through different providers. Through DeepInfra and similar, the output cost is still a fraction of Opus 4.7's $25.
Is Kimi K2.6 context window a real limitation?
Yes. Kimi K2.6 has a 128K context window compared to the 1M windows on Gemini 3.1 Pro, DeepSeek V4 Pro, and Opus 4.7. For codebases that don't fit in 128K tokens, K2.6 requires chunking or multi-pass strategies, which adds latency and complexity.
Does the 1.1% SWE-bench gap between GPT-5.5 and Opus 4.7 matter in practice?
Probably not for most use cases. SWE-bench Verified differences under 3-4 points tend to be within the noise of real-world variation in task difficulty, prompt quality, and scaffolding. The 20+ point difference between a well-configured agentic harness and a basic API call matters more than the model gap.
Where does Claude Sonnet 4.6 fit?
Claude Sonnet 4.6 scores 79.6% on SWE-bench Verified at $3/$15 on OpenRouter. It's a reasonable step-down from Opus 4.7 for teams that want to stay within the Anthropic family and aren't ready to assess models from other labs.
Sources:
- SWE-bench Verified Leaderboard - LLM Stats
- OpenRouter - AI Models for Coding
- OpenRouter - Gemini 3.1 Pro Preview
- OpenRouter - GPT-5.4 Pricing
- OpenRouter - GPT-5.5 Pricing
- BenchLM - SWE-bench Verified Benchmark
- Kimi K2.6 - Complete Guide 2026
- DeepSeek V4 Pro Pricing Guide 2026
- MorphLLM - Best AI Model for Coding
- Scale SEAL - SWE-Bench Pro Leaderboard
- NxCode - GPT-5.4 Complete Guide: Features, Pricing, Benchmarks
- LM Council - AI Model Benchmarks May 2026
✓ Last verified May 7, 2026
