Best LLM Eval Tools in 2026: 6 Options Tested
A data-driven comparison of DeepEval, Braintrust, Langfuse, LangSmith, Inspect AI, and RAGAS - the top LLM evaluation frameworks for teams building AI in production.

Shipping a LLM feature without eval tooling is guesswork. You make a prompt change, the output looks good in your test cases, you push to production, and a week later someone catches a regression you didn't know was there. Eval frameworks exist to close that loop: they run structured tests against your model, score outputs automatically, and give you a signal you can act on before users do.
TL;DR
- Best open-source eval framework: DeepEval - 50+ research-backed metrics, pytest integration, completely free under Apache-2.0
- Best managed eval platform: Braintrust - full lifecycle from dataset to CI enforcement, $0 Starter (usage-based) or $249/mo Pro
- Best for RAG evaluation specifically: RAGAS - purpose-built for retrieval pipelines, reference-free scoring, free and open source
In 2026, the space has split into two distinct camps: open-source frameworks you run locally or wire into CI/CD, and managed platforms that add dashboards, human-in-the-loop review, and production monitoring on top. The right choice depends on whether you need a testing library or an ops platform - and several tools now blur that line.
I ran each of these through a multi-step RAG pipeline and a basic agentic setup to see how they hold up. My findings are below.
The Contenders
| Tool | Type | License | Free tier | Paid starts at | Self-host |
|---|---|---|---|---|---|
| DeepEval | Framework | Apache-2.0 | Yes (unlimited local) | $19.99/user/mo (Confident AI platform) | Yes |
| Braintrust | Platform | Proprietary | 10K scores (Starter) | $0 Starter / $249/mo Pro | Enterprise only |
| Langfuse | Platform | MIT (core) | 50K events/mo | $29/mo (Core) | Yes |
| LangSmith | Platform | Proprietary | 5K traces/mo | $39/seat/mo (Plus) | Enterprise only |
| Inspect AI | Framework | MIT | Yes (unlimited) | Free (no paid tier) | N/A - local only |
| RAGAS | Framework | Apache-2.0 | Yes (unlimited) | Free (no paid tier) | N/A - local only |
If you already have an LLM observability setup, eval tooling sits upstream of it - you run evals before pushing changes, not while monitoring production. The two categories overlap but serve different phases of the development cycle.
DeepEval - The Pytest for LLMs
DeepEval is the most complete open-source eval framework available. It ships 50+ research-backed metrics covering accuracy, relevance, faithfulness, coherence, contextual recall, hallucination detection, and more. The API mimics pytest - you write test cases, define assertions, and run deepeval test run in CI. If a metric drops below your threshold, the build fails.
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import HallucinationMetric
def test_no_hallucination():
test_case = LLMTestCase(
input="What is the capital of France?",
actual_output="The capital of France is Paris.",
context=["France is a country in Western Europe. Its capital is Paris."]
)
metric = HallucinationMetric(threshold=0.5)
assert_test(test_case, [metric])
The framework handles single-turn and multi-turn evaluations, works with any LLM provider, and supports multimodal inputs (text, images, audio) as of 2026. Synthetic test dataset generation is built in - you can generate hundreds of test cases from a few seed examples using the built-in evolution techniques, which cuts manual curation clearly.
DeepEval itself is free under Apache-2.0. The commercial layer is the Confident AI platform, which adds dashboards, production tracing, team collaboration, and online evals. Confident AI pricing starts at $19.99/user/month (Starter) and $49.99/user/month (Premium). The free tier is limited to 2 seats, 1 project, and 5 test runs per week - fine for experimenting, not for production.
Trusted by teams at OpenAI, Google, Adobe, and Walmart according to the DeepEval homepage. The framework integrates natively with LangChain, LlamaIndex, LangGraph, OpenAI Agents SDK, CrewAI, and Anthropic.
When to pick it: You want a serious eval framework with strong metrics coverage and you're comfortable running it locally or wiring it into GitHub Actions. You don't need a SaaS platform.
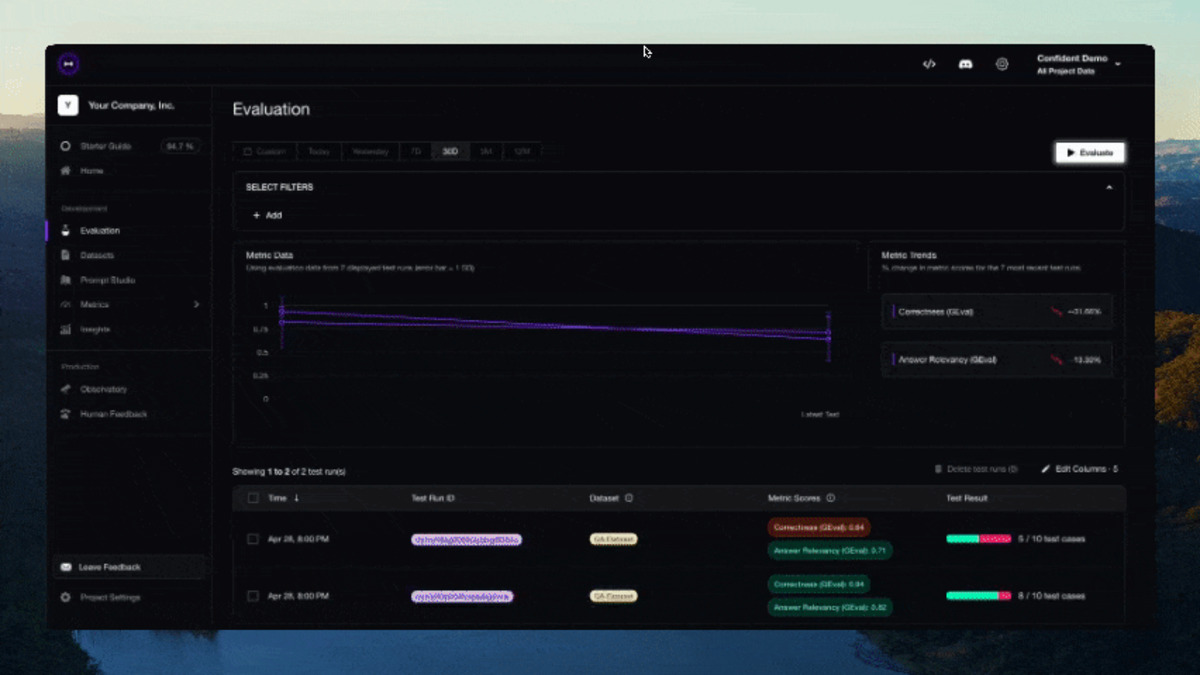 DeepEval's CLI output during a test run - failures surface clearly with metric scores and pass/fail status.
Source: github.com/confident-ai/deepeval
DeepEval's CLI output during a test run - failures surface clearly with metric scores and pass/fail status.
Source: github.com/confident-ai/deepeval
Braintrust - The Full Eval Lifecycle
Braintrust raised $80M in February 2026 at an $800M valuation, and the product justifies the attention. It connects dataset management, evaluation scoring, experiment tracking, and CI-based release enforcement in a single platform. Every eval run links back to the exact prompt version, model, and dataset that produced it - the "traceability" requirement that most teams discover too late.
The Starter plan (new as of March 2026) removes the barrier to entry: $0/month base fee with usage-based pricing - 10K scores and 1 GB storage included, then $2.50 per 1K scores and $4/GB as you grow. Unlimited users, projects, and experiments on every tier. Data retention is 14 days on Starter and 30 days on Pro ($249/month, 50K scores included, overage at $1.50 per 1K).
Braintrust is the only platform in this list that explicitly connects evaluation results to deployment decisions. You can configure release rules that block merges if eval scores fall below a threshold - automated enforcement rather than a post-hoc dashboard you have to remember to check.
The weak spot is self-hosting. It's enterprise-only, meaning most teams are on Braintrust's cloud. If you have data residency requirements, that's a non-starter unless you can negotiate an enterprise contract.
When to pick it: You need a production-grade eval platform with CI integration and experiment tracking. The Starter plan lets you start at $0 and pay for what you use. Best for teams already thinking about eval-driven deployment gates.
Langfuse - Open Source With Real Eval Depth
Langfuse gets covered heavily in the observability space, but its eval capabilities are underappreciated. The platform supports LLM-as-judge evaluations, custom score rubrics, dataset versioning, and human annotation queues - all open source under MIT license, self-hostable via Docker or Kubernetes.
Pricing on the cloud version starts at $0 for Hobby (50K events/mo, 2 users, 30-day retention), $29/month for Core (100K events, unlimited users, 90-day retention), and $199/month for Pro (3-year retention, SOC 2, HIPAA). All paid tiers include unlimited users, which matters if you're an engineering team of 10+ where per-seat pricing starts to hurt.
The Langfuse SDK integrates with OpenAI, Anthropic, LangChain, LlamaIndex, and LiteLLM. OpenTelemetry support was added in a recent release, making it compatible with standard OTLP collectors. The eval interface lets you define scoring functions in Python, attach them to traces, and compare scores across prompt versions.
Self-hosting is truly usable. The Docker Compose setup works out of the box for small deployments. At scale, Langfuse estimates $3,000-4,000/month in infrastructure costs for a medium deployment, compared to $199-300/month on the cloud Pro tier.
When to pick it: You want open-source flexibility with serious eval features, you need to self-host, and you're already building on top of LangChain or OpenTelemetry.
LangSmith - Best If You're Already in LangChain
LangSmith is the natural eval platform if your stack is LangChain or LangGraph. Tracing is zero-config inside those frameworks - you set two environment variables and every chain call gets logged automatically. Outside of LangChain, setup is more manual and the tight coupling starts working against you.
The evaluation system supports four evaluator types: LLM-as-judge, heuristic checks, human annotation queues, and pairwise comparisons. You can write custom Python or TypeScript evaluators for any scoring logic. Offline evals run against curated datasets during development; online evals score production traffic in real time.
Pricing: Developer plan is free at $0/seat but limited to 5K traces/month and 1 seat. Plus is $39/seat/month with 10K base traces and $2.50 per 1K additional (14-day retention) or $5.00 per 1K at extended 400-day retention. Enterprise is custom.
The per-seat, per-trace pricing model scales predictably for small teams but gets expensive fast in production. A team of 5 engineers running 500K traces/month is looking at roughly $1,400/month on Plus - compared to Langfuse Pro at $199/month flat.
When to pick it: Your codebase is built on LangChain and you want the easiest possible tracing setup. If you're not on LangChain, the integration overhead and cost model don't justify it.
Inspect AI - Serious Safety-Focused Evals
Inspect AI is the UK AI Security Institute's open-source evaluation framework, and it's built for a different use case than the others. Where DeepEval and Braintrust focus on application-level quality metrics - is my chatbot answering accurately, is my RAG pipeline retrieving relevant chunks - Inspect targets capability and safety evaluations at the model level.
The framework ships 100+ pre-built evaluation benchmarks covering coding (HumanEval, LiveCodeBench), reasoning (MATH, ARC), cybersecurity (CTF-style challenges), safeguard testing, and multimodal tasks. It uses an opinionated pipeline: Dataset → Task → Solver → Scorer, with built-in Docker sandboxing for agentic evals that execute code. A VS Code extension and web-based Inspect View make results browsable.
Inspect is free and MIT-licensed. There's no cloud platform, no paid tier, no managed service - it's a local framework only.
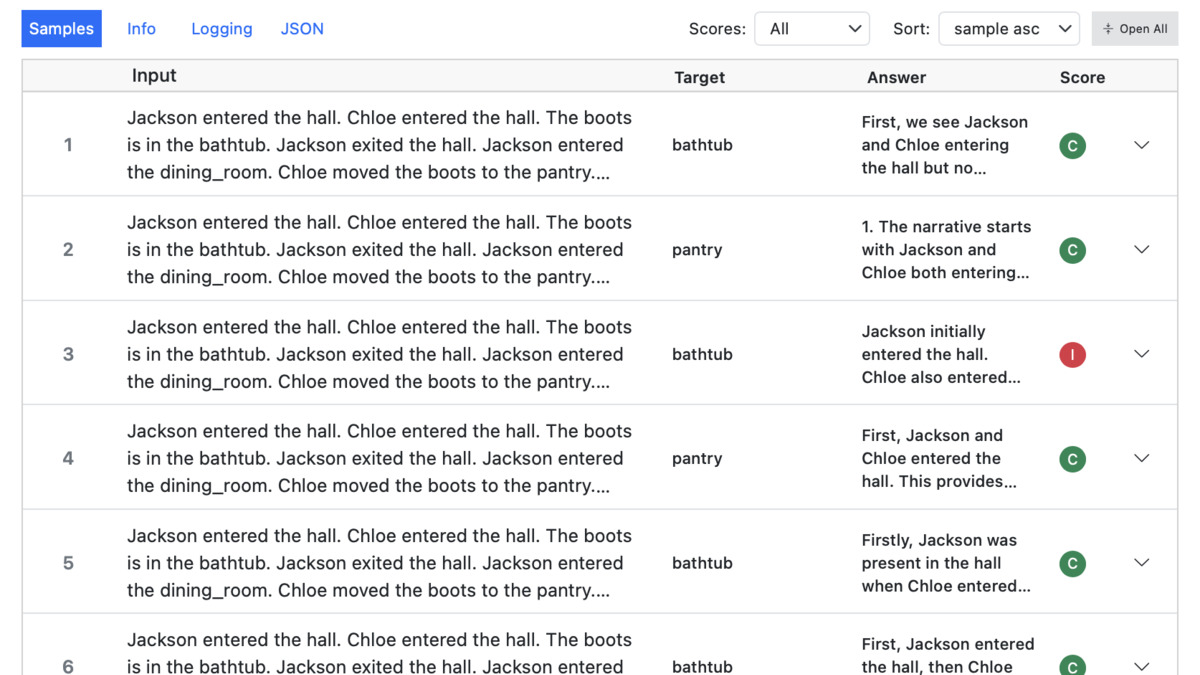 The Inspect log viewer displays per-sample scores and aggregate results across a benchmark run.
Source: inspect.aisi.org.uk
The Inspect log viewer displays per-sample scores and aggregate results across a benchmark run.
Source: inspect.aisi.org.uk
Adoption in safety research is strong - Anthropic, DeepMind, and other frontier labs use it internally. The contributor base includes other national AI safety institutes and independent research organizations.
When to pick it: You're running capability or safety evaluations on models, not application-level quality checks. Also worth adding to any stack that needs formal benchmark tracking.
RAGAS - Built for RAG Pipelines
If your application is a RAG system, RAGAS is worth knowing. It introduced reference-free RAG evaluation in 2023 - the ability to score a RAG pipeline without needing human-written ground truth for every query. The core five metrics are context precision, context recall, faithfulness, answer relevance, and answer correctness.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_recall
result = evaluate(
dataset,
metrics=[faithfulness, answer_relevancy, context_recall]
)
print(result)
RAGAS integrates with LangChain and LlamaIndex and sits inside Langfuse, LangSmith, and Arize Phoenix via their native integration layers. The synthetic test generation pipeline can bootstrap a test dataset from your document corpus with minimal manual work.
The limitation is scope. RAGAS is a pure evaluation library - no dashboards, no experiment tracking, no production monitoring. It's a scoring function, not a platform. For most teams, it makes sense as a component inside a larger eval stack rather than a standalone tool.
When to pick it: You're building a RAG application and need structured evaluation metrics. Use it alongside a platform like Langfuse or Braintrust, not instead of one.
What to Actually Use
The overlap between these tools is intentional - none of them are mutually exclusive, and the most capable setups combine a framework with a platform.
A practical stack for most teams building AI agents:
- DeepEval for unit tests in CI/CD (free, pytest-compatible, strong metric coverage)
- Langfuse for production tracing and eval dashboards (MIT license, self-hostable, generous free tier)
- RAGAS if your app is RAG-based (free, integrates directly into Langfuse)
If you need CI-enforced release gates and want everything in one managed platform, Braintrust is the strongest option. The new Starter plan ($0/month base, usage-based pricing at $2.50 per 1K scores after the first 10K) lets you evaluate the platform without the $249/month Pro commitment. The traceability model - linking every eval score to the exact prompt and dataset version - is truly useful once your team has more than two people pushing changes.
Inspect AI belongs in any stack that evaluates models for safety or capability, not just application quality. It's free, its benchmark library is the most complete available, and using it with a quality-focused framework like DeepEval covers both dimensions.
LangSmith is the easiest recommendation to make for LangChain teams and the hardest for everyone else. The per-trace pricing and ecosystem lock-in make it a poor fit outside its native environment.
Sources
- DeepEval - The LLM Evaluation Framework
- Confident AI Pricing Plans
- Braintrust Pricing
- Braintrust raises $80M Series B at $800M valuation - SiliconANGLE
- Langfuse - Open Source LLM Engineering Platform
- LangSmith Plans and Pricing
- Inspect AI - UK AISI Evaluation Framework
- Inspect Evals - 100+ Pre-built Benchmarks
- RAGAS Documentation
- RAGAS: Automated Evaluation of Retrieval Augmented Generation (arXiv 2309.15217)
- Maxim AI Pricing
✓ Last verified March 20, 2026

