AI Agent Memory in 2026: 5 Frameworks Ranked
We compared Mem0, Zep, Letta, LangMem, and Cognee on architecture, benchmarks, pricing, and use cases to find the right memory layer for your agent stack.

Stateless agents forget everything the moment a session ends. That was fine for simple Q&A bots, but modern agent pipelines - the kind that need to track user preferences across weeks, update their reasoning based on new facts, or coordinate across multiple sub-agents - need something more. Memory is now where a lot of production agents break down.
TL;DR
- Mem0 is the best general-purpose pick: largest ecosystem, managed cloud, free tier to start, $249/mo Pro for graph features
- Zep leads on the LongMemEval benchmark (63.8% vs Mem0's 49.0%) and is the right choice when temporal accuracy matters
- The open-source options (Letta, LangMem, Cognee) each solve a distinct problem - Letta for autonomous agents, LangMem for LangChain teams, Cognee for structured knowledge graphs
- No framework handles enterprise governance yet - audit trails and data retention policies remain gaps across all five
The memory problem in AI agents isn't simple storage. It's about retrieval: surfacing the right information at the right time, updating stale facts without corrupting what's still true, and doing it fast enough to stay inside response-time budgets. In 2026, a handful of frameworks have become the standard options teams reach for.
We assessed five of them - Mem0, Zep, Letta, LangMem, and Cognee - on architecture, benchmark performance, pricing, and real-world fit. If you're building your first agent or scaling an existing one, this is where to start.
How We Evaluated Them
The main benchmark is LongMemEval (ICLR 2025), 500 questions across six memory categories including temporal reasoning, preference tracking, and multi-session recall. Not every framework has published a score - but the ones that have give a concrete yardstick.
Beyond benchmarks, we looked at: storage architecture (vector vs graph vs hybrid), self-hosting options, API rate limits, and where each tool fits in a typical stack. If you want background on why retrieval architecture matters so much, the what is AI memory guide covers the conceptual layer.
1. Mem0 - The Established Choice
With ~48K GitHub stars, 14 million Python package downloads, and a $24M Series A closed in late 2025, Mem0 is the default choice most teams land on first. It's backed by YC, Basis Set, Peak XV, and angel investors including Dharmesh Shah and the Datadog CEO - the kind of support that signals the managed cloud service isn't going away.
Architecture
Mem0 uses a hybrid store: vector embeddings for semantic similarity, a property graph for entity relationships, and a key-value layer for structured facts. When an agent writes a memory, Mem0 automatically extracts facts, deduplicates against existing entries, and stores the result across all three layers. Retrieval then queries all three and merges results.
The graph layer - which is where relational memory lives, e.g. "User A reports to User B" - is only available on the Pro plan and above. On Hobby and Starter, you get vector and key-value only.
Pricing
| Plan | Monthly | Add requests | Retrieval requests |
|---|---|---|---|
| Hobby | Free | 10,000 | 1,000 |
| Starter | $19 | 50,000 | 5,000 |
| Pro | $249 | 500,000 | 50,000 |
| Enterprise | Custom | Unlimited | Unlimited |
The Pro tier at $249/mo also unlocks private Slack support, advanced analytics, and multiple projects. There's a startup program offering three months free Pro access for companies under $5M in funding.
Best for
Teams that need a managed cloud memory layer with minimal setup, agents that personalize to individual users, and projects where Mem0's Python/Node.js SDK fits naturally. If you don't need graph relationships, the free Hobby tier is genuinely usable for prototyping.
 Mem0 positions itself as a universal memory layer supporting user, agent, and session memory across any AI application.
Source: github.com/mem0ai/mem0
Mem0 positions itself as a universal memory layer supporting user, agent, and session memory across any AI application.
Source: github.com/mem0ai/mem0
2. Zep - The Benchmark Leader
Zep's Graphiti engine scores 63.8% on LongMemEval using GPT-4o, against Mem0's 49.0% on the same sub-task. That 15-point gap isn't a minor difference - it reflects a different architectural approach to how facts are stored.
Architecture
Where most memory systems store a snapshot of what was said, Zep stores what was said and when it was true. Every fact in Graphiti carries validity windows: it became true at this timestamp, and was superseded at this timestamp. An agent can ask "what did I know about user X in March?" and get the correct answer even if something changed in April.
Zep models memory as a temporal knowledge graph - not what was said, but when it was true and when it changed.
This temporal graph architecture is what drives the benchmark advantage. The trade-off is complexity: Zep's pricing model is credit-based rather than seat-based, and the credit consumption model (1 credit per 350 bytes ingested) requires some planning at scale.
 Zep's Graphiti architecture paper shows how the temporal knowledge graph stores validity windows for every fact, enabling accurate recall of what was true at any point in time.
Source: arxiv.org/abs/2501.13956
Zep's Graphiti architecture paper shows how the temporal knowledge graph stores validity windows for every fact, enabling accurate recall of what was true at any point in time.
Source: arxiv.org/abs/2501.13956
Pricing
| Plan | Monthly | Credits included | Rate limit |
|---|---|---|---|
| Free | $0 | 1,000 | Limited |
| Flex | $125 | 50,000 | 600 req/min |
| Flex Plus | $375 | 200,000 | 1,000 req/min |
| Enterprise | Custom | Custom | SLA-backed |
Note that Zep charges for ingestion only, not for storage or retrieval. Overage on Flex is $25 per 10,000 additional credits. Enterprise adds SOC 2 Type II, HIPAA BAA, and flexible deployment (managed, bring-your-own-key, bring-your-own-model, bring-your-own-cloud).
Best for
Agents that need accurate temporal reasoning - anything tracking how facts change over time, like customer account states, competitive intelligence updates, or long-running research projects. Also worth considering for any team where benchmark accuracy is a buying criterion rather than an afterthought.
3. Letta - The OS-Inspired Agent
Letta (originally MemGPT, from UC Berkeley's Sky Computing Lab) takes the most architecturally distinct approach in this comparison. Instead of hiding memory management from the agent, Letta exposes it as a first-class operation: the agent itself decides what to keep in active context, what to archive, and when to retrieve.
Architecture
The model borrows from operating system design. Core memory is the equivalent of RAM - always in context, fast, but limited. Archival memory is disk - searchable, persistent, but requires an explicit retrieve call. Recall memory is the search index over conversation history. The agent can inspect and edit all three layers using built-in tool calls.
This means a Letta agent running for weeks can learn from mistakes, update its own instructions, and compact older memories into summaries - without a human scripting those operations. Letta also ships with Letta Code, a memory-first coding agent built on the same runtime.
Letta has ~21K GitHub stars and is fully open-source, backed by VC but with an Apache 2.0 license for the core runtime. Self-hosted deployment means zero platform costs, though you're responsible for the infrastructure.
Pricing
The self-hosted version is free. Letta also offers a managed cloud service (letta.com) with usage-based pricing - exact rates available on request. There's no gated feature matrix between self-hosted and cloud beyond the operational overhead of running it yourself.
Best for
Long-running autonomous agents that need to evolve over time, teams comfortable with Python and willing to manage infrastructure, and any scenario where the agent should have genuine autonomy over its own memory rather than passively receiving retrieved context. Not a good fit if you need a simple drop-in API.
4. LangMem - The LangChain Native
If your stack already runs on LangGraph or LangChain, LangMem is the lowest-friction path to persistent memory. It's free, MIT-licensed, and ships as a pip package with no required accounts or API keys.
Architecture
LangMem adds three memory types on top of LangGraph's built-in store: episodic (past interactions), semantic (facts and user preferences), and procedural (agents rewriting their own system prompt instructions based on feedback). The background memory manager runs asynchronously, extracting and consolidating memories from conversations without the agent needing to explicitly decide what to remember.
Storage is pluggable - you can point it at any vector database, Postgres via pgvector, or MongoDB. The lack of a managed cloud layer is both a strength (no data leaves your infrastructure) and a limitation (you're fully responsible for storage and scaling).
LangMem has published no LongMemEval score as of May 2026.
Pricing
Free. MIT licensed. pip install langmem, no API keys, no monthly bill.
Best for
Teams already on LangGraph who want persistent memory without adding a new vendor. The procedural memory type - where agents update their own instructions - is genuinely novel and not available in most other frameworks. Avoid if you're not on LangGraph; there's no standalone mode.
5. Cognee - The Knowledge Graph Layer
Cognee positions itself as a memory control plane rather than a memory store. Its ECL pipeline (Extract, Cognify, Load) ingests data from 38+ sources, structures it into a knowledge graph with embeddings and relationships, and makes it queryable. The open-source project has ~12K GitHub stars and raised $7.5M in seed funding.
Architecture
The core differentiator is the knowledge graph at every tier, including the open-source local deployment using Kuzu as the graph backend. Entity extraction and relationship resolution run as part of the standard ingestion pipeline, not as a premium add-on. Cognee also connects to 30+ external data sources - Slack, Notion, Google Drive, databases - making it the strongest option for agents that need to reason over heterogeneous organizational data.
It runs fully offline via Ollama with no cloud dependency, which matters for regulated industries or any environment where data residency is a constraint. For an overview of how retrieval-augmented generation ties in here, see the what is RAG guide.
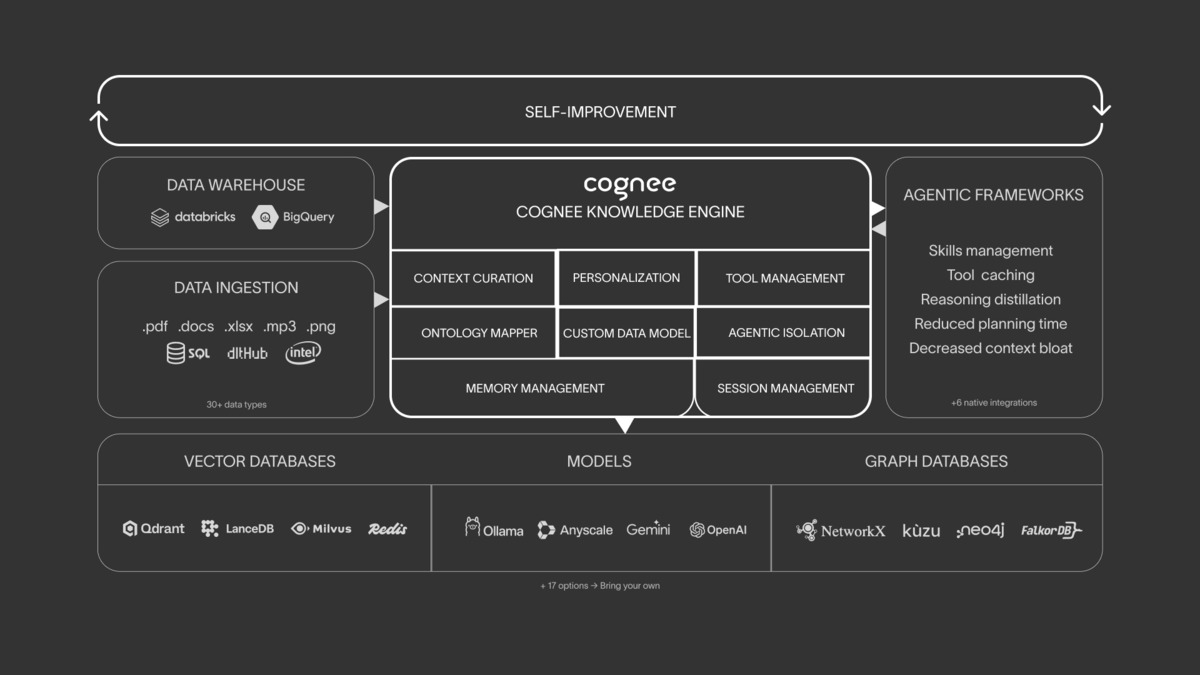 Cognee's ECL pipeline ingests from 30+ sources, builds a structured knowledge graph, and makes it queryable by agents.
Source: github.com/topoteretes/cognee
Cognee's ECL pipeline ingests from 30+ sources, builds a structured knowledge graph, and makes it queryable by agents.
Source: github.com/topoteretes/cognee
Pricing
The open-source core is free for self-hosted use. The managed cloud uses a document top-up model:
| Pack | Documents (~GB) | Cost |
|---|---|---|
| Small | 1,000 (~1 GB) | $35 |
| Medium | 3,000 (~3 GB) | $100 |
| Large | 15,000 (~15 GB) | $750 |
| Enterprise | Custom | $1,970/mo and up |
Best for
Agents that ingest structured organizational data from multiple sources, scenarios where knowledge graph traversal is more useful than vector similarity, and teams that need full local deployment. Cognee's pipeline volume grew from ~2,000 runs to over 1 million in 2025, so the infrastructure is proven at scale.
Framework Comparison
| Framework | LongMemEval | GitHub Stars | Starting Price | Self-hosted | Best for |
|---|---|---|---|---|---|
| Mem0 | 49.0% | ~48K | Free | No | Personalization, general use |
| Zep | 63.8% | ~24K | Free / $125/mo | No | Temporal reasoning, compliance |
| Letta | Not published | ~21K | Free (self-host) | Yes | Long-running autonomous agents |
| LangMem | Not published | ~1.3K | Free | Yes | LangChain/LangGraph teams |
| Cognee | Not published | ~12K | Free (self-host) | Yes | Structured knowledge ingestion |
Two newer entrants worth tracking: Hindsight (91.4% LongMemEval with a four-strategy hybrid retrieval approach) and OMEGA (95.4%, local-first with SQLite and ONNX embeddings, $19/mo Pro). Both scores are self-reported on their own benchmarking infrastructure rather than peer-reviewed independent runs, which is worth noting when comparing to Zep and Mem0's published numbers.
How to Pick One
Start with your retrieval requirement, not the benchmark leaderboard. Benchmark scores measure accuracy on a standardized test - your workload may have very different characteristics.
You need managed cloud, fast setup, and broad integrations: Start with Mem0. The free tier works for prototyping, Starter at $19/mo covers most early production traffic, and the ecosystem is large enough that someone has already solved whatever integration problem you'll hit.
You need temporal accuracy and you're willing to pay: Zep. The 15-point LongMemEval gap over Mem0 isn't noise - it reflects a real architectural advantage for workloads where facts change over time. $125/mo Flex gets you 50,000 ingestion credits, which covers many agent interactions.
You want full autonomy and your team can run infrastructure: Letta for long-horizon agents, LangMem if you're already on LangGraph. Both are free and truly capable; the cost is operational.
Your agents need to reason over organizational data from multiple sources: Cognee. The 30+ connectors and knowledge graph at every tier make it the strongest option for enterprise knowledge work agents.
The memory layer is becoming as important as the model choice for production agents. Picking the wrong one early means rewriting integration code later - these frameworks don't share a common API.
Sources
- Mem0 pricing page
- Mem0 raises $24M Series A - TechCrunch
- Zep pricing page
- Letta GitHub repository
- LangMem documentation
- Cognee GitHub repository
- Cognee $7.5M seed round announcement
- Best AI Agent Memory Frameworks 2026 - Atlan
- Best AI Agent Memory Systems 2026 - Vectorize
- LongMemEval benchmark paper - arXiv
- Zep vs Mem0: LongMemEval comparison
- OMEGA memory framework pricing
✓ Last verified May 6, 2026
