
Grok 4.3
Grok 4.3 Beta adds native video input and document generation to xAI's flagship, with a confirmed 0.5T-parameter checkpoint and 2M-token context window, at $300/month for SuperGrok Heavy subscribers.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Grok 4.3 Beta adds native video input and document generation to xAI's flagship, with a confirmed 0.5T-parameter checkpoint and 2M-token context window, at $300/month for SuperGrok Heavy subscribers.

Gemini 3.1 Pro leads GPQA Diamond at 94.1% and HLE at 44.7% as AIME 2025 saturates; Claude Opus 4.7 and Kimi K2.6 join the top tier in April 2026.

Three new papers show AI scientific agents skip evidence, tool-integrated agents are vulnerable to adversarial poisoning, and reasoning model safety can be fixed with 1,000 examples.

GPT Image 2 (ChatGPT Images 2.0) brings 99%+ text accuracy, 2K resolution, web-search grounding, and a Thinking mode for character-consistent storyboards.

Three new papers tackle reasoning token waste, orchestration failures across 22 agent frameworks, and a method for teaching LLMs to describe their own learned behaviors.

LG AI Research's first open-weight vision-language model packs 33B parameters, 262K context, and STEM scores above GPT-5-mini - but ships under a non-commercial license.
OpenAI's first domain-specific reasoning model for biology and drug discovery, launched April 16 2026 as a US-only research preview with a 0.751 BixBench score.

Three new papers challenge assumptions in MoE routing design, prompt optimization workflows, and LLM reasoning chains - all published this week on arXiv.

Arcee Trinity-Large-Thinking is a 400B sparse MoE open-source reasoning model that ranks #2 on PinchBench at $0.85/M output tokens, 28x cheaper than Claude Opus 4.6.
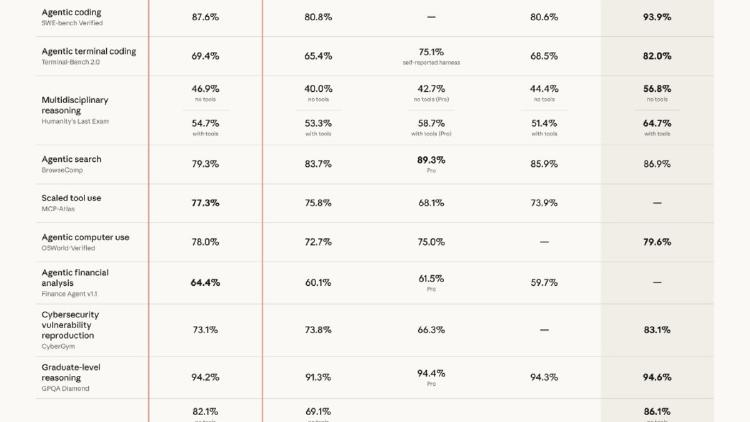
Anthropic's latest flagship model ships with 3x higher resolution vision, a new xhigh effort level, task budgets for cost control, cyber safeguards, and 13% better coding performance at the same $5/$25 pricing.

Three papers from today's arXiv: a joint fix for KV cache bloat and attention cost, new evidence that fine-tuning belongs in the middle of a transformer, and why stronger reasoning hurts behavioral simulation.

Claude Mythos Preview is Anthropic's most capable model - restricted to 50 orgs via Project Glasswing, with 93.9% on SWE-bench Verified and thousands of autonomous zero-day discoveries.