
ERNIE 5.1
Baidu's ERNIE 5.1 is a text-focused MoE model that claims the top Chinese model slot on LMArena with 800B parameters built at 6% of comparable training costs.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Baidu's ERNIE 5.1 is a text-focused MoE model that claims the top Chinese model slot on LMArena with 800B parameters built at 6% of comparable training costs.

Three arXiv papers: a conscience mechanism for ethical training, shared memory for agent populations, and selective verification that cuts test-time compute waste.
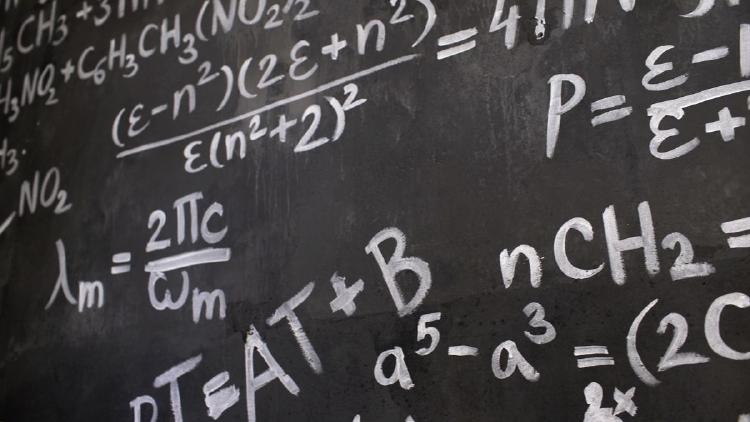
Pramaana Labs uses the LEAN proof language to attach a mathematical certificate to every AI answer in high-stakes domains like tax, law, and drug discovery.

GPT-5.1 is OpenAI's November 2025 coding and agentic flagship with 400K context, configurable reasoning effort, and 76.3% on SWE-bench Verified.

Moonshot AI's Kimi K2.7-Code is a 1T-parameter open-weight MoE coding model with mandatory thinking mode, 256K context, and 30% fewer reasoning tokens than K2.6.

A hands-on review of all seven MAI models - from the April transcription and image launch to Build 2026's MAI-Thinking-1, MAI-Code-1-Flash, and the multimodal upgrades.

Microsoft's first in-house reasoning model, a 35B-active sparse MoE with 256K context, 97% on AIME 2025, and no distillation from third-party labs.

Three new arXiv papers expose how context bloat tanks agent performance, agent memory bleeds private data, and misaligned behavior spreads through multi-agent systems.

Anthropic's Claude Opus 4.8 scores 69.2% on SWE-bench Pro and ships hundreds of parallel subagents in Claude Code, with pricing unchanged at $5 per million input tokens.

NVIDIA's 550B Nemotron 3 Ultra, released June 4, tops the US open-weight leaderboard with a hybrid Mamba-Transformer MoE architecture and 300-plus tokens per second throughput.

Three new papers tackle how routine AI use quietly rewires emotional habits, how to spend compute where failures cost most, and why agentic RAG errors compound before anyone notices.

Three new papers show that AI agents fail not by doing the wrong thing, but by doing things when they should have stopped.