
Qwen3.6-27B
Qwen3.6-27B is a 27B dense open-weight multimodal model from Alibaba that scores 77.2% on SWE-bench Verified - beating Alibaba's own 397B MoE - under Apache 2.0.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Qwen3.6-27B is a 27B dense open-weight multimodal model from Alibaba that scores 77.2% on SWE-bench Verified - beating Alibaba's own 397B MoE - under Apache 2.0.

Alibaba's Qwen3.5-Omni takes text, images, audio, and video as input and streams both text and speech output in a single end-to-end model with a 256K context window.

Alibaba's first closed-weights flagship Qwen ships with a 256K context window, tops six agentic coding benchmarks, and ranks third on the Artificial Analysis Intelligence Index.

Alibaba released Qwen3.6-Max-Preview on April 20 as its first closed-weights flagship, ranking third globally on the Artificial Analysis Intelligence Index while topping six coding benchmarks.

Rankings of the best audio language models on MMAU, MMAU-Pro, and other benchmarks covering speech reasoning, music understanding, and environmental sound identification.

Rankings of AI models on OCR and document understanding benchmarks - OCRBench, DocVQA, InfographicVQA, ChartQA, TextVQA, and MMMU-Pro. Covers GPT-4.1 Vision, Claude 4 Sonnet/Opus, Gemini 2.5 Pro, Qwen2.5-VL, InternVL3, Mistral OCR, and more.

Rankings of AI models on the key visual reasoning benchmarks - MMMU, MathVista, ChartQA, DocVQA, OCRBench, AI2D, CharXiv, and more - focused on image and document understanding.
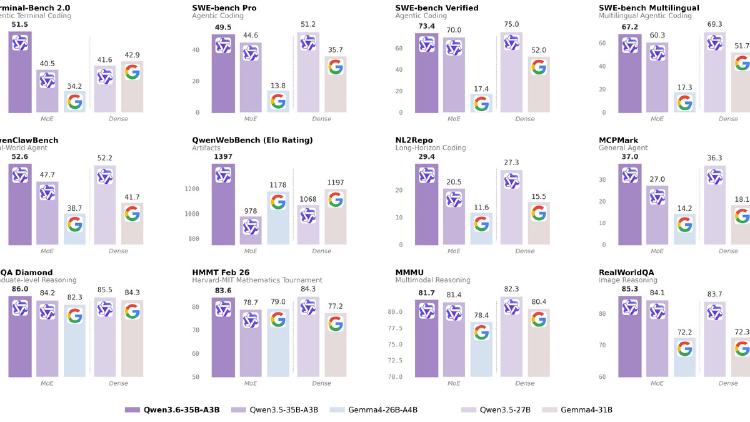
Alibaba's 35B sparse MoE with 3B active parameters delivers 73.4% SWE-bench Verified, multimodal vision and video, 256K context, and DeltaNet hybrid architecture under Apache 2.0.
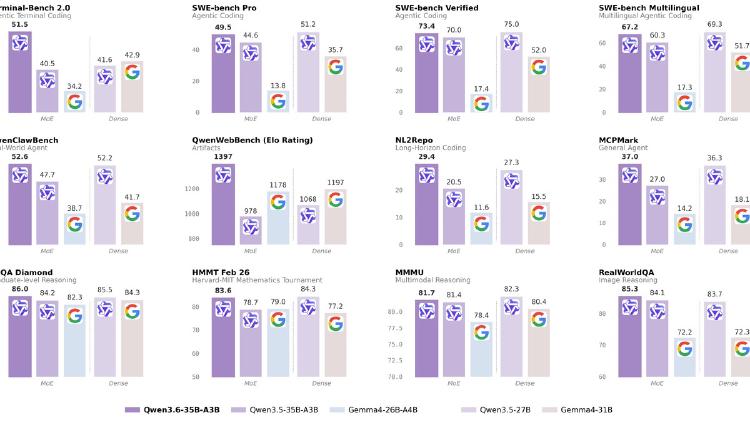
Alibaba's Qwen 3.6-35B-A3B activates only 3B of its 35B parameters per token, scores 73.4% on SWE-bench Verified, handles video and images, and ships under Apache 2.0.

Alibaba's Qwen3.5-Omni handles audio, video, images, and text in a single model pass - and generates speech in real time. The Plus variant hits SOTA on 215 benchmarks and edges out Gemini 3.1 Pro on audio tasks.

Rankings of AI models on IFEval and IFBench, the two main benchmarks for measuring how reliably LLMs follow precise formatting, length, and content constraints.

Alibaba officially launches Qwen3.6-Plus, a 1-million-token context model built for enterprise agentic coding and multimodal reasoning, now free on OpenRouter.