
Quantization's Hidden Tax, Cliff Tokens, Smarter Memory
Three new arXiv papers reveal hidden costs in quantized reasoning models, single-token failure triggers, and a new framework that cuts agent memory errors by up to 79%.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Three new arXiv papers reveal hidden costs in quantized reasoning models, single-token failure triggers, and a new framework that cuts agent memory errors by up to 79%.

Google DeepMind's new QAT checkpoints shrink the Gemma 4 E2B model to under 1GB, making serious on-device AI viable for phones and budget laptops.

Top open-weight models for self-hosting in 2026, with verified VRAM requirements, benchmark data, and tools to deploy them on consumer and server hardware.

The definitive guide to open-weights AI models in 2026 - top picks by size tier, use case, benchmark scores, and deployment hardware. From 400B+ MoE giants to 1B edge models.
How much quality do LLMs lose when quantized from BF16 to INT8, Q6, Q5, Q4, Q3, Q2? Per-model delta tables across MMLU, HumanEval, and perplexity, with VRAM and throughput data for every major quantization format.
A benchmark-driven comparison of the top open-source LLM inference servers - vLLM, SGLang, TGI, llama.cpp, TensorRT-LLM, LMDeploy, and more.
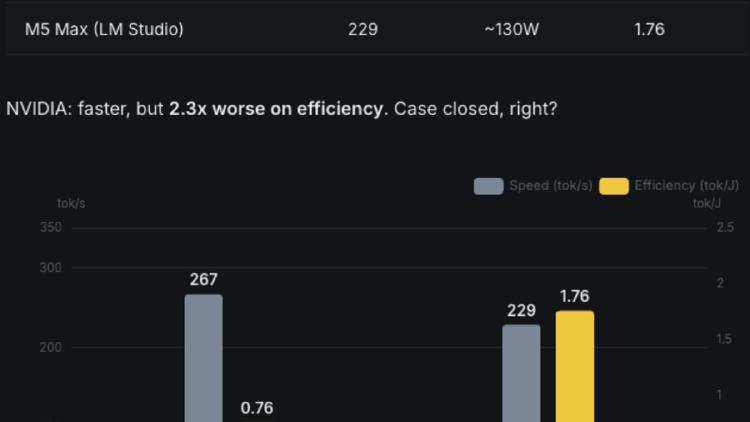
Two researchers fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, making a five-year-old RTX 3090 deliver 1.8x the throughput of an M5 Max at equal or better efficiency. The gap was software, not silicon.

Google Research's TurboQuant compresses LLM key-value cache by 6x and delivers 8x speedup on H100 GPUs with zero accuracy loss - no fine-tuning required.

Full specs, benchmarks, and analysis of the NVIDIA Rubin CPX - a purpose-built inference GPU with 128GB GDDR7, 30 PFLOPS NVFP4, and 3x faster attention versus Blackwell, targeting million-token context workloads.

Complete specs, benchmarks, and analysis of the NVIDIA Rubin R200 GPU - the post-Blackwell flagship with 288GB HBM4, 22 TB/s bandwidth, and 50 PFLOPS FP4.

Complete specs, benchmarks, and analysis of the NVIDIA B200 - the Blackwell-architecture flagship GPU with 192GB HBM3e, 8 TB/s bandwidth, and up to 9,000 TFLOPS FP8.

Complete specs, benchmarks, and analysis of the NVIDIA H100 SXM - the Hopper-architecture GPU that defined the standard for AI training and inference performance.