
GPT-4 to Self-Hosted Llama 4 Migration Guide
Switch from OpenAI's GPT-4 API to self-hosted Llama 4 with near-zero code changes, but plan carefully for hardware, EU licensing, and real context window limits.
Switch from OpenAI's GPT-4 API to self-hosted Llama 4 with near-zero code changes, but plan carefully for hardware, EU licensing, and real context window limits.

Apple's cheapest Mac ever packs the A18 Pro iPhone chip with a 16-core Neural Engine - but its 60 GB/s memory bandwidth puts a hard ceiling on what local models you can actually run.

Ollama Cloud extends the popular local LLM runner to the cloud, letting you push models from your laptop and serve them globally. We test latency, cold starts, pricing, and the developer experience against dedicated inference providers.
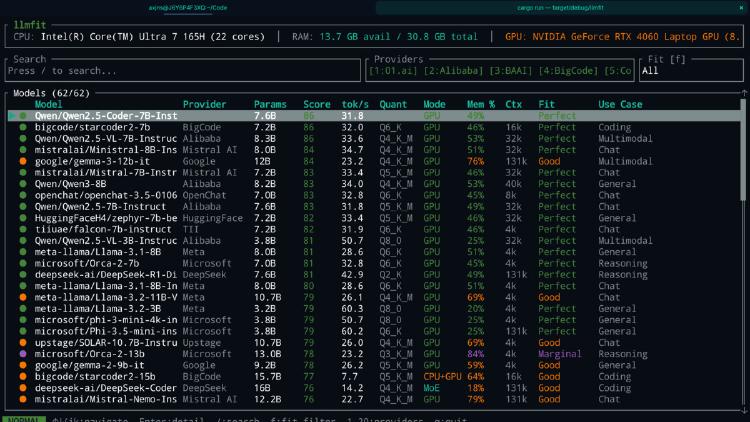
LLMfit is a Rust-based terminal tool that scans your hardware and scores 157 LLMs across 30 providers for compatibility, speed, and quality. Here is why it matters.

Georgi Gerganov's ggml.ai joins Hugging Face, bringing the most important local inference project under the $13.5 billion AI platform's umbrella.

Georgi Gerganov and the ggml.ai team behind llama.cpp are joining Hugging Face. The deal unifies model hosting, model definition, and local inference under one open-source roof.

How to build a professional AI-assisted coding environment that costs nothing - the best free editors, extensions, inference providers, and local models combined into setups that rival $20/month subscriptions.
