
Mistral Small 3.2
Mistral Small 3.2 is a 24B dense model with strong function calling, multimodal vision, and 128K context under Apache 2.0 - optimized for production tool-use pipelines and EU-compliant deployments.
Mistral Small 3.2 is a 24B dense model with strong function calling, multimodal vision, and 128K context under Apache 2.0 - optimized for production tool-use pipelines and EU-compliant deployments.

David vs Goliath: Qwen3.5-35B-A3B activates 3B parameters and beats Llama 4 Scout's 17B active on MMLU-Pro, GPQA, and coding benchmarks - but Scout's 10M context window and native multimodal support tell a different story.
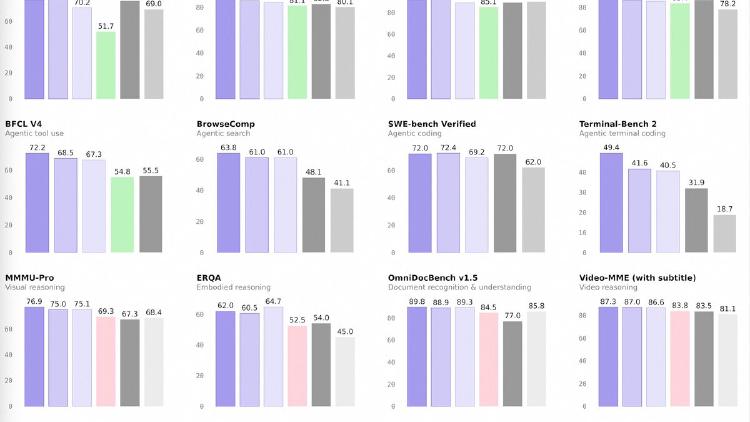
Alibaba releases four Qwen 3.5 medium models - Flash, 35B-A3B, 122B-A10B, and 27B - that match or beat the previous 235B flagship at a fraction of the compute. The 35B model activates just 3 billion parameters and still outperforms Qwen3-235B-A22B.
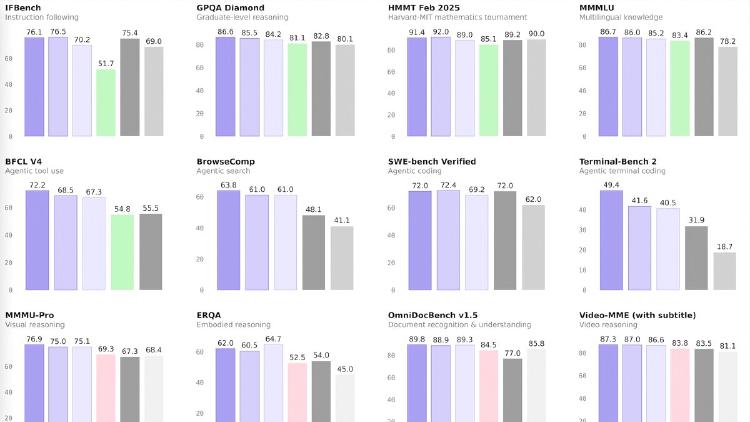
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
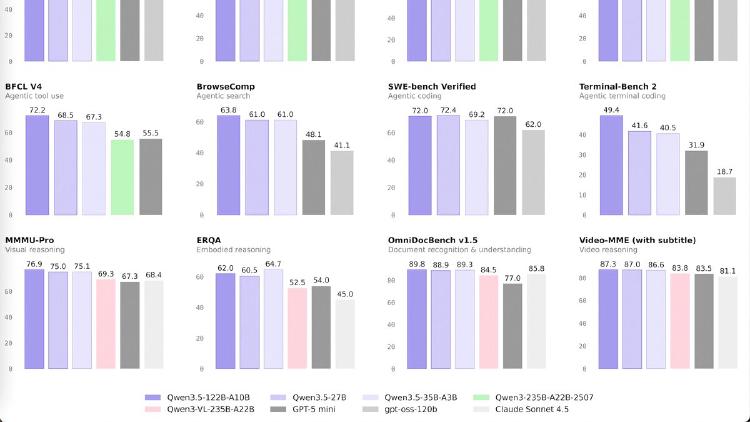
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
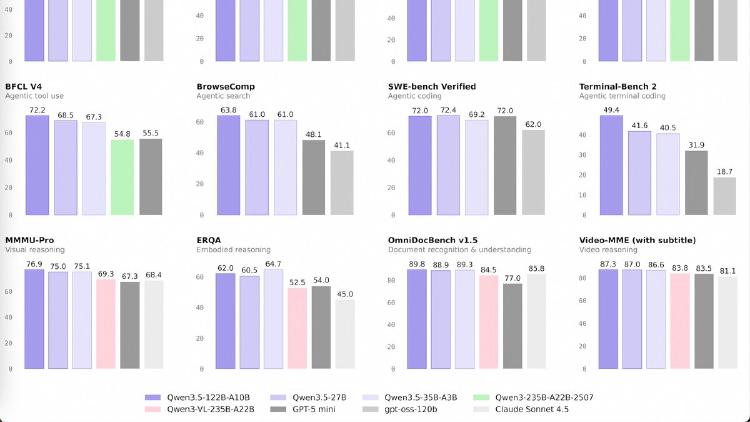
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.
