
OpenAI Open-Sources Privacy Filter: 96% F1 PII Masker
OpenAI released Privacy Filter today, a 1.5B MoE with 50M active parameters that tags eight categories of PII in text. Apache 2.0, 128K context, runs in a browser via WebGPU.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
OpenAI released Privacy Filter today, a 1.5B MoE with 50M active parameters that tags eight categories of PII in text. Apache 2.0, 128K context, runs in a browser via WebGPU.

Qwen3.6-35B-A3B lands with 73.4 on SWE-bench Verified and Apache 2.0 weights, all from 3 billion active parameters routed through a 256-expert MoE. Fits on a single consumer GPU.

Z.ai's GLM-5.1 is an open-weight 754B MoE model that tops SWE-Bench Pro with 58.4, sustains 8-hour autonomous coding sessions, and runs under MIT license at $0.95/M input tokens.
Baidu's ERNIE 5.0 combines 2.4 trillion parameters with native omni-modal design, landing at LMArena's top-10 globally and outpacing GPT-5 High on chart and document benchmarks.

Alibaba's Qwen3.5-Omni takes text, images, audio, and video as input and streams both text and speech output in a single end-to-end model with a 256K context window.

Moonshot AI's Kimi K2.6 is a 1T-parameter MoE with 32B active per token, 256K context, a 300-agent swarm running 4,000 coordinated steps, and the top SWE-Bench Pro score among open-weight models at 58.6%.

Moonshot AI releases Kimi K2.6 under Modified MIT with open weights on HuggingFace, 300-agent swarm execution, and the highest SWE-Bench Pro score among open models.

Three new papers challenge assumptions in MoE routing design, prompt optimization workflows, and LLM reasoning chains - all published this week on arXiv.

Arcee Trinity-Large-Thinking is a 400B sparse MoE open-source reasoning model that ranks #2 on PinchBench at $0.85/M output tokens, 28x cheaper than Claude Opus 4.6.
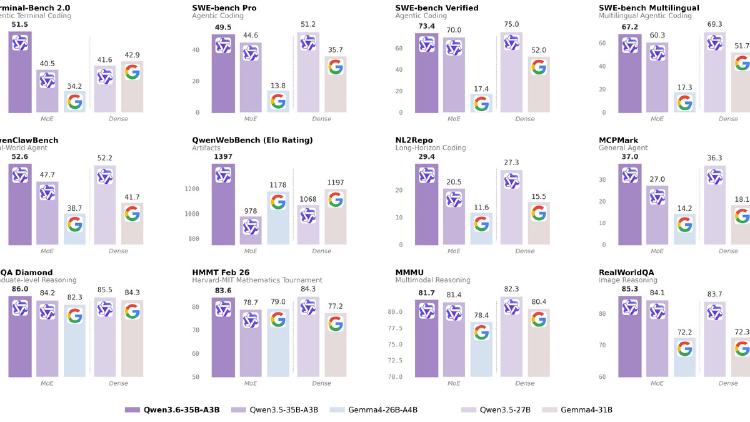
Alibaba's 35B sparse MoE with 3B active parameters delivers 73.4% SWE-bench Verified, multimodal vision and video, 256K context, and DeltaNet hybrid architecture under Apache 2.0.
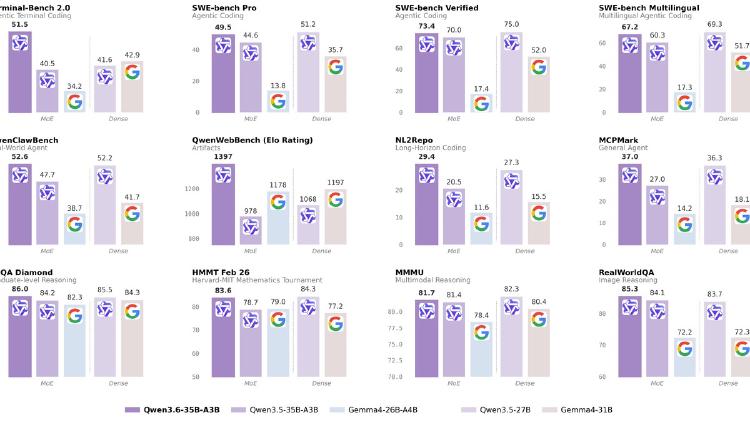
Alibaba's Qwen 3.6-35B-A3B activates only 3B of its 35B parameters per token, scores 73.4% on SWE-bench Verified, handles video and images, and ships under Apache 2.0.

Three papers this week challenge how we think about MoE expert routing, LLM context management, and the limits of activation steering.