Nemotron 3 Nano 30B-A3B
NVIDIA's hybrid Mamba2+MoE model packs 31.6B total parameters but activates only 3.2B per token, delivering frontier-class reasoning with 3.3x the throughput of comparable models on a single H200 GPU.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
NVIDIA's hybrid Mamba2+MoE model packs 31.6B total parameters but activates only 3.2B per token, delivering frontier-class reasoning with 3.3x the throughput of comparable models on a single H200 GPU.
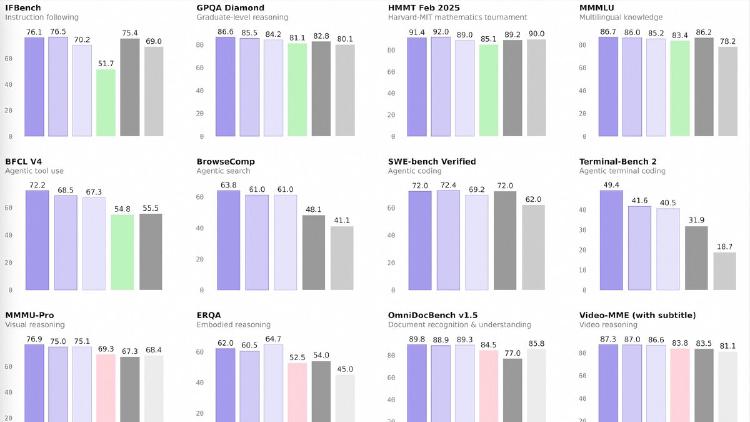
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.

Anthropic's flagship model leads on agentic coding, enterprise knowledge work, and long-context retrieval with a 1M-token window, 128K output, and agent teams at $5/$25 per million tokens.

Google DeepMind's Gemini 3.1 Pro leads on 13 of 16 benchmarks with 77.1% ARC-AGI-2, 94.3% GPQA Diamond, and a 1M-token context window at $2/M input.

A former Scale AI and DeepMind researcher told OpenClaw to only suggest email deletions. It hit a context limit, forgot the rule, and trashed hundreds of messages before she could stop it.
Rankings of the best AI models for long-context tasks, measuring retrieval accuracy, reasoning, and comprehension across massive context windows from 128K to 10M tokens.

Google DeepMind's flagship thinking model with 1M-token context, 84% GPQA Diamond, and native multimodal understanding of text, images, audio, and video.

OpenAI's coding-optimized API model with a 1M token context window, 54.6% SWE-bench Verified score, and $2/$8 per million token pricing.

Anthropic's first hybrid reasoning model with togglable extended thinking, a 200K context window, and state-of-the-art SWE-bench performance at $3/$15 per million tokens.