
AORUS RTX 5090 AI BOX vs NVIDIA DGX Spark for Local AI
Two very different approaches to desktop AI hardware - a 32 GB eGPU with 1,792 GB/s bandwidth versus a 128 GB unified memory mini PC with full CUDA. Which one should you buy?
Two very different approaches to desktop AI hardware - a 32 GB eGPU with 1,792 GB/s bandwidth versus a 128 GB unified memory mini PC with full CUDA. Which one should you buy?

A review of the Gigabyte AORUS RTX 5090 AI BOX - a liquid-cooled eGPU packing a full desktop RTX 5090 with 32 GB GDDR7, connecting to any laptop over Thunderbolt 5 for $2,999.

A hands-on review of the NVIDIA DGX Spark - a 128 GB Grace Blackwell mini PC that promises 1 petaflop of AI performance on your desk for $4,699.

A complete guide to setting up the NVIDIA DGX Spark - from unboxing and first boot to running LLM inference, fine-tuning models, and optimizing performance.

Awni Hannun, the Stanford-trained researcher who co-created Apple's MLX machine learning framework, announced his departure from Apple. His exit is the latest in a devastating exodus of AI talent that has hollowed out Apple's ML research bench over the past year.

LM Studio 0.4.5 introduces LM Link, built on Tailscale's tsnet library, letting users access local AI models on remote hardware through end-to-end encrypted connections with zero port forwarding.

MIT spinoff Liquid AI releases LFM2-24B-A2B, a hybrid mixture-of-experts model that activates only 2.3B parameters per token, fits in 32GB RAM, and hits 112 tokens per second on a consumer CPU.

A comprehensive guide to the best image generation models that run locally on consumer GPUs with 16GB of VRAM, from FLUX and Stable Diffusion to video generation and upscaling.
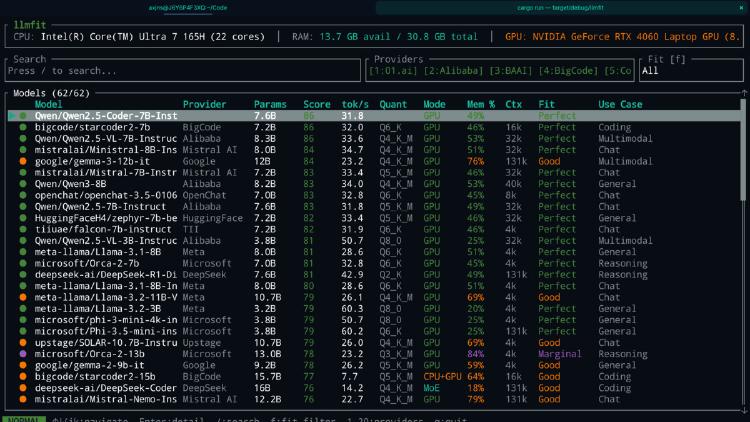
LLMfit is a Rust-based terminal tool that scans your hardware and scores 157 LLMs across 30 providers for compatibility, speed, and quality. Here is why it matters.

Georgi Gerganov's ggml.ai joins Hugging Face, bringing the most important local inference project under the $13.5 billion AI platform's umbrella.

Georgi Gerganov and the ggml.ai team behind llama.cpp are joining Hugging Face. The deal unifies model hosting, model definition, and local inference under one open-source roof.

A viral tweet exposes an uncomfortable pattern in the local LLM community: endless hardware purchases, near-zero shipped products. The data backs it up.
