
Nemotron 3 Nano Omni Unifies Vision, Audio, Language
NVIDIA's new open omni model activates 3B of 30B parameters, processes video, audio, and documents in one pass, and delivers up to 9.2x higher throughput than other open omni models.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
NVIDIA's new open omni model activates 3B of 30B parameters, processes video, audio, and documents in one pass, and delivers up to 9.2x higher throughput than other open omni models.

Three arXiv papers show AI systems fake alignment in 37% of test cases, reshape human moral values through brief chats, and can cut inference compute while improving performance.

Google splits its next TPU generation across Broadcom, MediaTek, Marvell, and Intel to win inference economics, revealed ahead of Cloud Next 2026.

OpenAI burned $2.5B in cash on $4.3B of revenue in the first half of 2025. Anthropic cut its gross margin forecast from 50% to 40%. Here's the compute subsidy math behind every AI subscription, and who's actually paying for it.

Complete buying guide for AI home workstations in 2026 - pre-built machines and DIY builds for running local LLMs from 3B to 70B+ models, with benchmarks, part lists, and price-tier comparisons.
How much quality do LLMs lose when quantized from BF16 to INT8, Q6, Q5, Q4, Q3, Q2? Per-model delta tables across MMLU, HumanEval, and perplexity, with VRAM and throughput data for every major quantization format.
A benchmark-driven comparison of the top open-source LLM inference servers - vLLM, SGLang, TGI, llama.cpp, TensorRT-LLM, LMDeploy, and more.

The Caveman plugin for Claude Code cuts 65-87% of output tokens by stripping filler words and using terse fragment-based language. Its new Classical Chinese mode pushes compression even further.
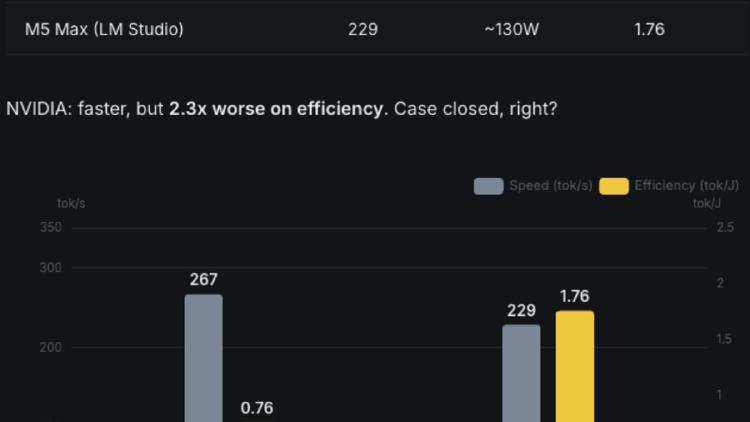
Two researchers fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, making a five-year-old RTX 3090 deliver 1.8x the throughput of an M5 Max at equal or better efficiency. The gap was software, not silicon.

Three papers from today's arXiv: a joint fix for KV cache bloat and attention cost, new evidence that fine-tuning belongs in the middle of a transformer, and why stronger reasoning hurts behavioral simulation.

The NVIDIA Groq 3 LPU is a pure-SRAM inference chip delivering 150 TB/s memory bandwidth and 1.2 PFLOPS FP8 per chip, designed to pair with Vera Rubin GPUs for trillion-parameter model serving.

The Positron Atlas is an 8-card FPGA inference server delivering 4.5x better performance per watt than the NVIDIA DGX H200 at 2000W in a single 1U chassis.