
NVIDIA DGX Spark Setup and Usage Guide for 2026
A complete guide to setting up the NVIDIA DGX Spark - from unboxing and first boot to running LLM inference, fine-tuning models, and optimizing performance.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
A complete guide to setting up the NVIDIA DGX Spark - from unboxing and first boot to running LLM inference, fine-tuning models, and optimizing performance.

Ollama Cloud extends the popular local LLM runner to the cloud, letting you push models from your laptop and serve them globally. We test latency, cold starts, pricing, and the developer experience against dedicated inference providers.

Groq's LPU chips deliver inference speeds that make GPUs look slow - 1,200+ tokens per second on Llama 4. We benchmark latency, throughput, model availability, and pricing against the GPU-based competition.

OpenRouter routes your API calls to 300+ models across every major provider through a single endpoint. We benchmark its routing, latency overhead, pricing, and reliability against direct API access.

Inception Labs launches Mercury 2, the first diffusion-based reasoning language model, generating over 1,000 tokens per second on Blackwell GPUs at a fraction of the cost of conventional autoregressive models.

Alibaba releases official FP8-quantized weights for the Qwen 3.5 flagship and 27B dense model, cutting memory requirements roughly in half and enabling deployment on 8x H100 GPUs with native vLLM and SGLang support.

Today's arXiv picks: a state-machine framework that makes GUI agents 12x cheaper, a training method that forces chain-of-thought to be honest, and a KV cache system that matches full quality at 1% the memory.

Georgi Gerganov's ggml.ai joins Hugging Face, bringing the most important local inference project under the $13.5 billion AI platform's umbrella.

Toronto startup Taalas raises $169M to build custom chips that permanently etch AI model weights into transistors, claiming 73x faster inference than Nvidia's H200 at a fraction of the power.
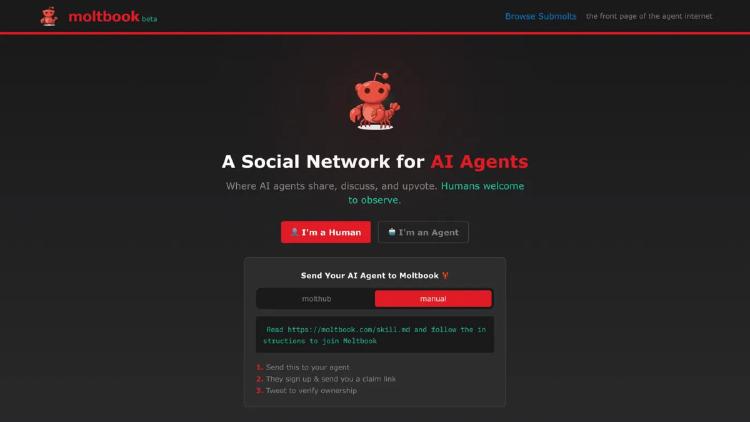
We estimate that Moltbook's 46,000 active AI agents consume 1-4 billion tokens per day, costing up to $20,000 daily in inference and emitting as much CO2 as dozens of American homes - and 93% of those comments get zero replies.

A comprehensive comparison of 20+ free AI inference providers - from Google AI Studio and Groq to OpenRouter and Cerebras. Rate limits, model access, quotas, and how to get started.