
TSMC Q1: $35.9B Record as AI Now Powers 61% of Revenue
TSMC posted $35.9B in Q1 2026 revenue, a 40.6% year-over-year jump, with AI and HPC now accounting for 61% of wafer sales - and CoWoS packaging still fully booked.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
TSMC posted $35.9B in Q1 2026 revenue, a 40.6% year-over-year jump, with AI and HPC now accounting for 61% of wafer sales - and CoWoS packaging still fully booked.

Complete buying guide for AI home workstations in 2026 - pre-built machines and DIY builds for running local LLMs from 3B to 70B+ models, with benchmarks, part lists, and price-tier comparisons.
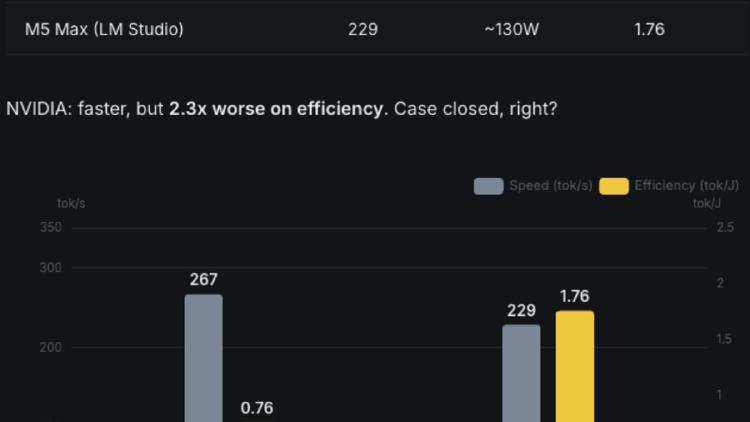
Two researchers fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, making a five-year-old RTX 3090 deliver 1.8x the throughput of an M5 Max at equal or better efficiency. The gap was software, not silicon.

The AMD Instinct MI430X is AMD's CDNA 5 HPC accelerator with 432GB HBM4, full FP64 support, and 19.6 TB/s bandwidth - designed for sovereign AI and scientific supercomputing alongside the MI455X AI GPU.

The Positron Atlas is an 8-card FPGA inference server delivering 4.5x better performance per watt than the NVIDIA DGX H200 at 2000W in a single 1U chassis.

Allbirds sold its entire footwear business for $39 million - roughly 1% of its $4 billion peak valuation - and is rebranding as NewBird AI to buy GPUs and rent compute to AI developers. The stock quadrupled in a day.

NVIDIA releases two open-source AI models for quantum hardware - a 35B vision-language model that cuts calibration time from days to hours, and CNN decoders that outpace the standard by 2.5x.

NVIDIA Ising is the world's first open AI model family for quantum computing - a 35B MoE VLM for quantum processor calibration and 3D CNN decoders for real-time surface code error correction.

Intel will use its 18A process node to manufacture chips for the Tesla-SpaceX-xAI joint venture targeting 1 terawatt of AI compute annually - and claims $2B in CHIPS Act subsidies in the process.

Intel's Arc Pro B70 launched on March 25 with 32GB GDDR6 and 367 TOPS for $949, undercutting NVIDIA's RTX Pro 4000 by $850. The hardware case is strong. The software story is not.

Eclipse Ventures closed two funds totaling $1.3B to build and back physical AI companies in robotics, defense, and manufacturing as investor conviction shifts from software to machines.

Meta's KernelEvolve AI agent autonomously generates and optimizes hardware kernels across NVIDIA, AMD, and MTIA chips, delivering over 60% inference gains in production.