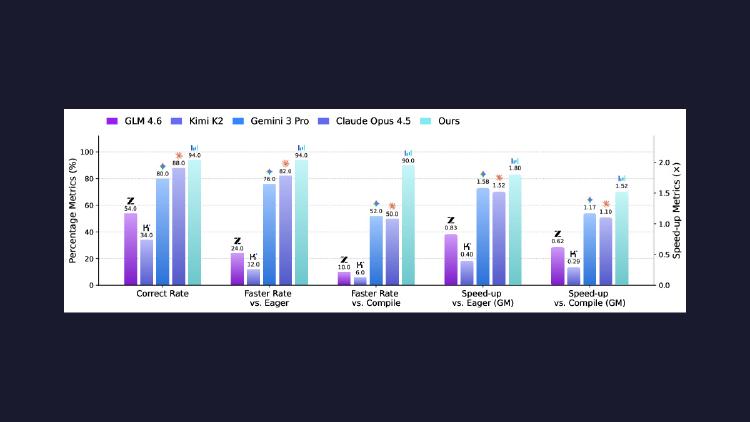
US Weighs 75K-Chip Cap on Nvidia H200 Sales to China
The Trump administration is considering limiting Chinese companies to 75,000 Nvidia H200 GPUs each - less than half what Alibaba and ByteDance want - while zero chips have shipped despite months of export approvals.