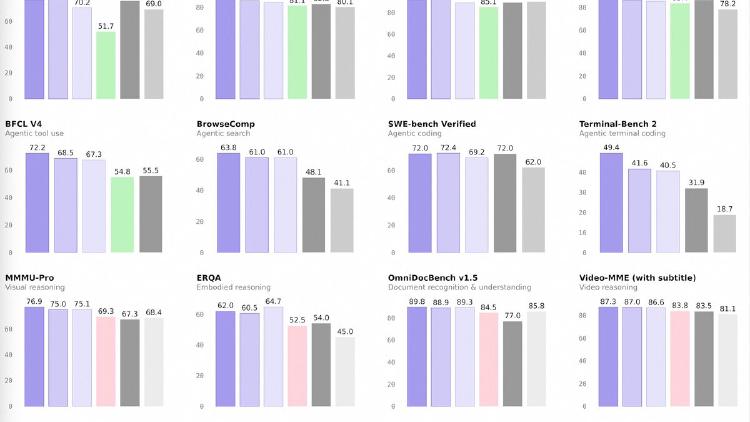
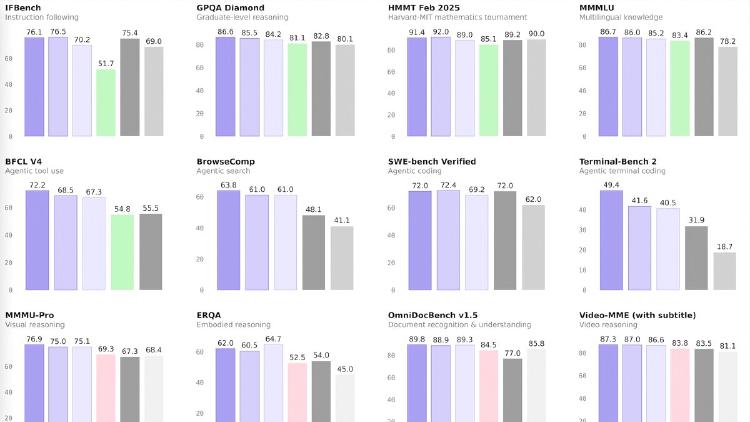
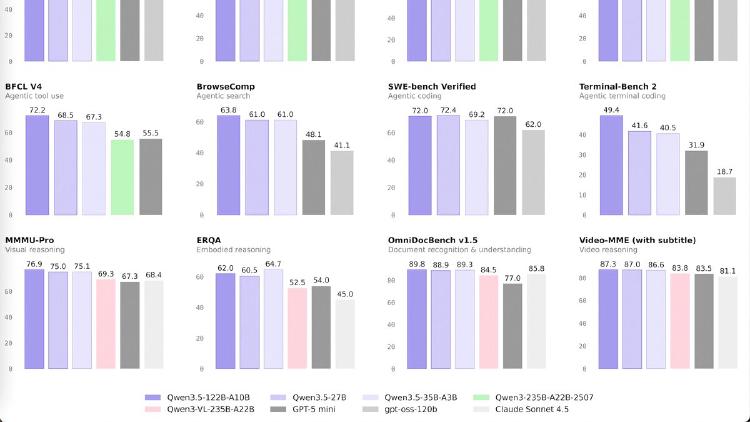
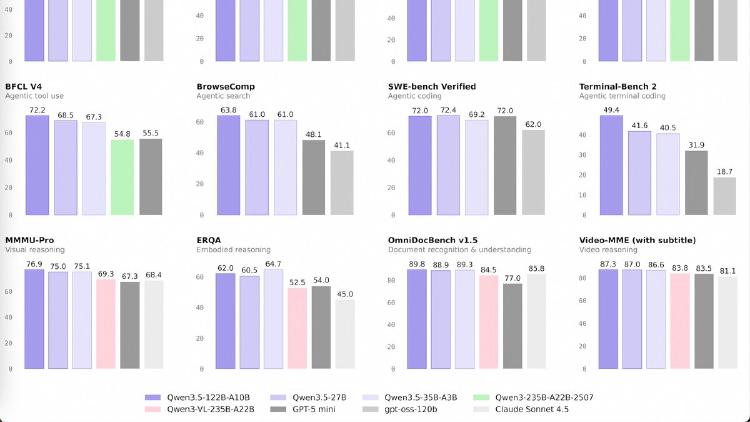
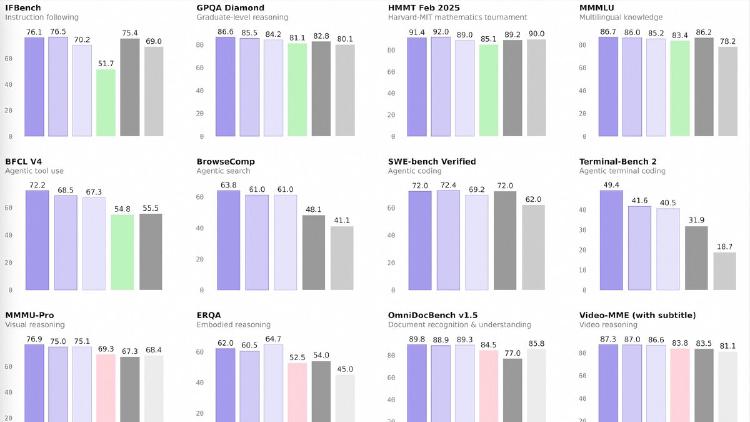
Qwen 3.5 Small Series Ships Four Models From 0.8B to 9B
Alibaba completes the Qwen 3.5 lineup with four small models - 0.8B, 2B, 4B, and 9B - all natively multimodal, 262K context, Apache 2.0. The 9B outperforms last-gen Qwen3-30B and beats GPT-5-Nano on vision benchmarks.