
vLLM 0.17 Ships FlashAttention 4 and Live MoE Scaling
vLLM v0.17.0 adds FlashAttention 4, elastic expert parallelism for live MoE rescaling, full Qwen3.5 support, and a performance-mode flag, all in 699 commits from 272 contributors.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
vLLM v0.17.0 adds FlashAttention 4, elastic expert parallelism for live MoE rescaling, full Qwen3.5 support, and a performance-mode flag, all in 699 commits from 272 contributors.

Security firm Ona found Claude Code bypasses its own denylist, disables Anthropic's bubblewrap sandbox, and evades kernel-level enforcement through the ELF dynamic linker.

Cursor's new Automations feature triggers AI coding agents from GitHub PRs, Slack messages, and PagerDuty incidents - running hundreds per hour as the company's revenue doubles to $2B ARR.

OpenAI is developing an internal code repository to replace GitHub, putting the company on a collision course with its biggest backer.
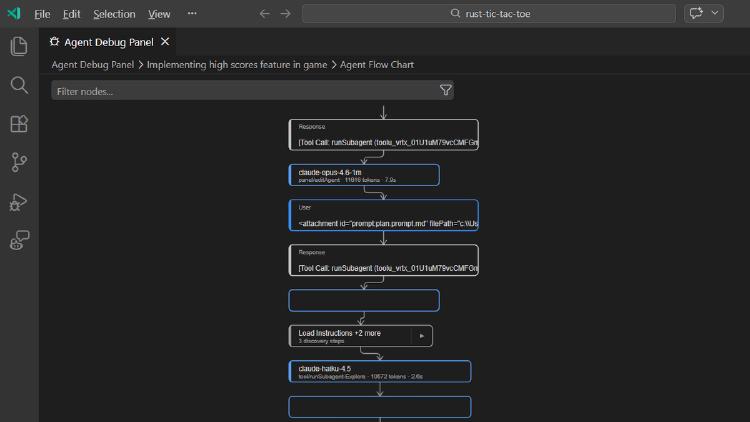
VS Code 1.110 ships native browser control for AI agents, installable agent plugins with MCP support, persistent session memory, and a new Agent Debug panel.
Luma AI's new Agents platform, powered by the Uni-1 Unified Intelligence model, lets creative teams go from a written brief to finished video, images, and audio in one workflow.

Claude Code 2.1.68 restores the ultrathink keyword after community backlash over quality degradation, while setting Opus 4.6 to medium effort by default for speed on daily tasks.
OpenAI's Codex desktop app hits the Microsoft Store with native Windows sandboxing, PowerShell agents, WinUI skills, and multi-agent parallel execution - no WSL required.
A data-driven comparison of Langfuse, LangSmith, Helicone, Braintrust, Phoenix, and Portkey - the top LLM observability platforms for teams building AI in production.

A new 501(c)(3) nonprofit backed by the creators of curl, Vue.js, and HashiCorp is building the world's first permanent endowment for open source as AI-generated junk submissions push maintainers to the breaking point.

Mercury 2 by Inception Labs is the fastest reasoning LLM available, built on diffusion architecture. We tested the speed, quality, and real-world trade-offs.

Inception Labs' Mercury 2 hits 1,196 tokens per second in independent testing - a diffusion architecture that rewires how inference works.