
Ideogram 3.0
Ideogram 3.0 is Ideogram AI's most capable text-to-image model, leading the field in typography accuracy at ~90-95% and offering production-ready API access at $0.03-$0.09 per image.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Ideogram 3.0 is Ideogram AI's most capable text-to-image model, leading the field in typography accuracy at ~90-95% and offering production-ready API access at $0.03-$0.09 per image.

GPT-5.5 is OpenAI's first completely retrained base model since GPT-4.5, leading the field on agentic coding and computer use - but the doubled per-token pricing and delayed API access require careful evaluation.
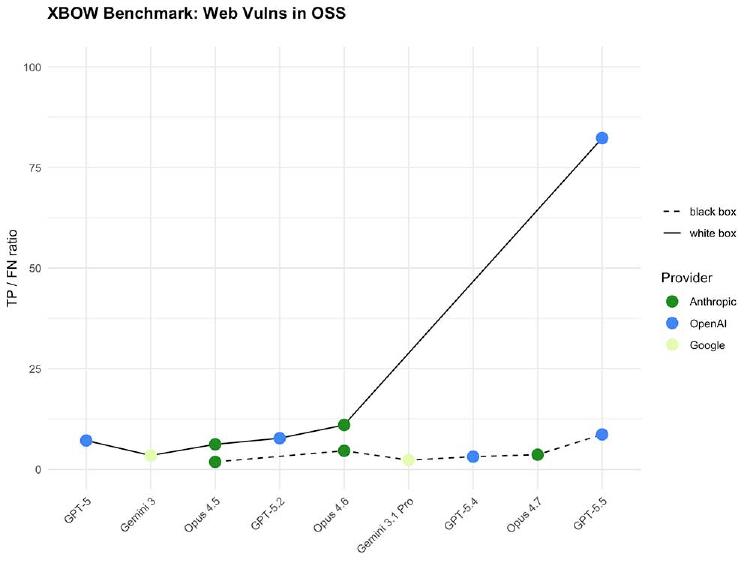
XBOW's benchmarks show GPT-5.5 cuts vulnerability miss rate to 10%, matches Anthropic's restricted Mythos - and is available to all ChatGPT subscribers.

Anthropic's Project Deal experiment found that agents running stronger models consistently closed better transactions - and users represented by weaker agents had no idea.

A hands-on look at the best AI tools for freight brokerage, customs compliance, and supply chain visibility for SMBs in 2026 - with real pricing and honest assessments.

The five AI manufacturing platforms worth evaluating in 2026 - compared on features, pricing, and real-world fit for predictive maintenance, visual quality control, and process optimization.

A hands-on comparison of the top AI tools for logistics in 2026 - covering route optimization, fleet management, demand forecasting, freight visibility, and warehouse automation with real pricing and honest assessments.

A practical comparison of the top AI tools for insurance underwriting, claims processing, fraud detection, and customer service in 2026.

A ranked comparison of the best AI-powered flashcard and study tools in 2026 - Anki, Quizlet, RemNote, Knowt, and Brainscape - with real pricing, feature breakdowns, and honest picks.

Dynatrace, Datadog, Elastic, New Relic, and Anodot compared on anomaly detection accuracy, pricing, and real-world trade-offs for SRE and DevOps teams in 2026.

Five AI tutoring platforms tested and compared by price, subject coverage, pedagogy quality, and who each one actually suits in 2026.

Tableau, Power BI, ThoughtSpot, Julius AI, and Hex compared on pricing, AI features, and real-world limitations for 2026.