
Rapid-MLX Is 2.6x Faster Than Ollama on Apple Silicon
New open-source inference engine for Apple Silicon benchmarks up to 2.6x faster than Ollama, supports 66 model aliases, and drops in as an OpenAI-compatible server on any Mac.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
New open-source inference engine for Apple Silicon benchmarks up to 2.6x faster than Ollama, supports 66 model aliases, and drops in as an OpenAI-compatible server on any Mac.

NVIDIA RTX Spark is a 20-core ARM + Blackwell GPU superchip delivering 1 petaFLOP FP4 and 128GB unified memory for AI-first Windows laptops and desktops.

Tim Cook becomes executive chairman and John Ternus, the hardware engineer behind Apple Silicon, takes the CEO role on September 1 - a clear bet that chips beat software in the AI race.

Complete buying guide for AI home workstations in 2026 - pre-built machines and DIY builds for running local LLMs from 3B to 70B+ models, with benchmarks, part lists, and price-tier comparisons.
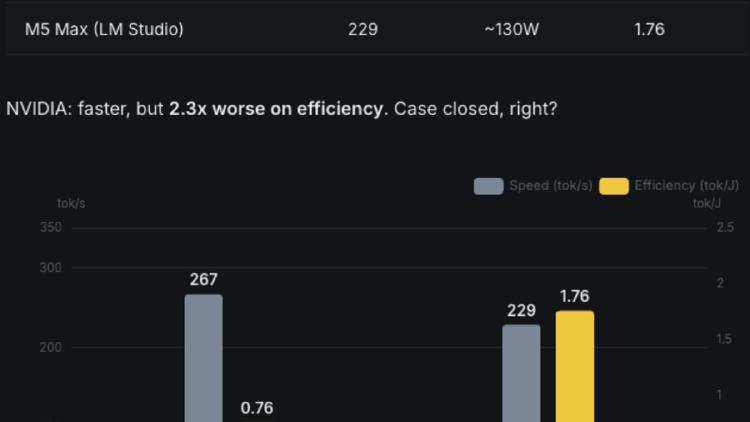
Two researchers fused all 24 layers of Qwen 3.5-0.8B into a single CUDA kernel launch, making a five-year-old RTX 3090 deliver 1.8x the throughput of an M5 Max at equal or better efficiency. The gap was software, not silicon.

Apple's flagship SoC with 40-core GPU, per-core Neural Accelerators, 614 GB/s bandwidth, and 4x AI performance over M4 Max.

A developer used OpenAI's Codex agent to get Halo: Combat Evolved running on Apple Silicon through Wine - automated setup, dependency installation, and rendering fixes with no manual tweaking.

A developer ported NVIDIA's PersonaPlex 7B speech-to-speech model to native Swift using MLX, running full-duplex conversation on Apple Silicon with no cloud, no Python, and faster-than-real-time inference.

Apple's cheapest Mac ever packs the A18 Pro iPhone chip with a 16-core Neural Engine - but its 60 GB/s memory bandwidth puts a hard ceiling on what local models you can actually run.

Apple launches M5 Pro and M5 Max MacBook Pros with Neural Accelerators in every GPU core, 128GB unified memory, and 614GB/s bandwidth - enough to run Llama 70B on a laptop.

A hands-on guide to Metal compute programming on Apple Silicon. Covers architecture, unified memory, real code examples in MSL and Swift, and how Metal compares to CUDA.
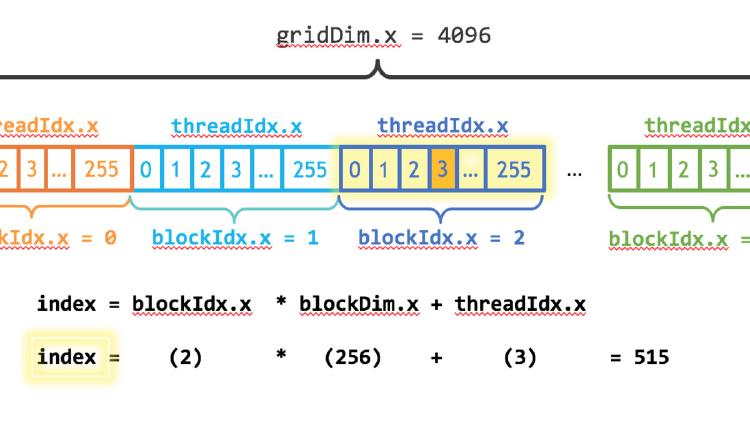
A hands-on guide to CUDA programming for developers who know how to code but have never written a GPU kernel. Covers architecture, memory, real code examples, and Metal comparison.