
IBM Granite 4.0 1B Speech Tops OpenASR Leaderboard
IBM's new 1B-parameter speech model claims the top spot on the Open ASR Leaderboard while running on consumer hardware, beating Whisper Large V3 by 25% on word error rate.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
IBM's new 1B-parameter speech model claims the top spot on the Open ASR Leaderboard while running on consumer hardware, beating Whisper Large V3 by 25% on word error rate.

Community fine-tune that distills Claude Opus 4.6 reasoning into Qwen3.5-27B via LoRA. 28B parameters, Apache 2.0, no published benchmarks.

Alibaba completes the Qwen 3.5 lineup with four small models - 0.8B, 2B, 4B, and 9B - all natively multimodal, 262K context, Apache 2.0. The 9B outperforms last-gen Qwen3-30B and beats GPT-5-Nano on vision benchmarks.
Qwen3.5-0.8B is the smallest natively multimodal model in the Qwen 3.5 family - 0.8B parameters handling text, images, and video with 262K context. MathVista 62.2, OCRBench 74.5. Apache 2.0.
Qwen3.5-2B is a 2B dense multimodal model with 262K context, thinking mode, and native vision including video understanding. OCRBench 84.5, VideoMME 75.6. Apache 2.0 licensed.

Qwen3.5-4B is a 4B dense multimodal model that matches Qwen3-30B on MMLU-Pro and beats GPT-5-Nano on vision benchmarks. Runs on 8GB VRAM, Apache 2.0 licensed, 262K-1M context.

Qwen3.5-9B is a 9B dense model that outperforms Qwen3-30B on most benchmarks and beats GPT-5-Nano on vision tasks. Natively multimodal with 262K-1M context, Apache 2.0 licensed.

Mistral Large 3 is a 675B-parameter MoE model activating 41B per token with native multimodal support, a 256K context window, and Apache 2.0 licensing - Europe's first frontier-class open-weight model.

Mistral Small 3.2 is a 24B dense model with strong function calling, multimodal vision, and 128K context under Apache 2.0 - optimized for production tool-use pipelines and EU-compliant deployments.

A data-driven comparison of Alibaba's Qwen3.5-27B and Mistral's Small 3.2 - two Apache 2.0 dense models in the 24-27B range with very different benchmark profiles and deployment strengths.
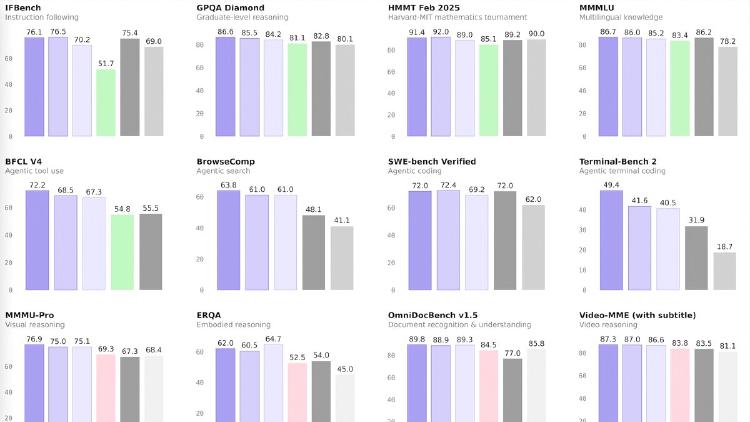
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
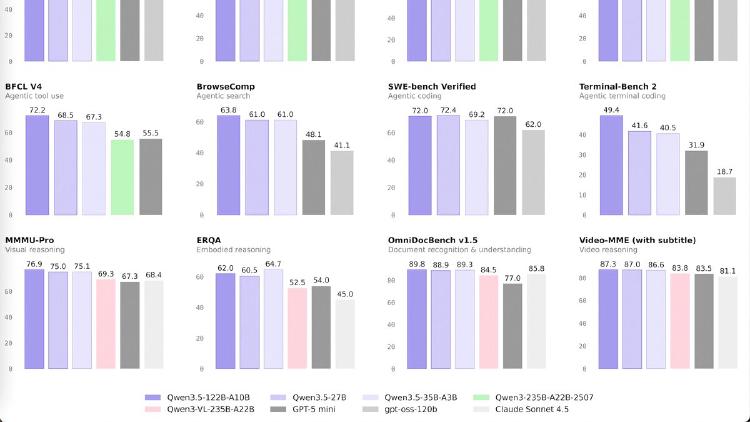
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.