Unsafe Agents, Rising AI Tides, and Training Traps
Three new papers on agent prompt injection attack rates, MIT's broad-based AI automation finding, and a silent normalization-optimizer coupling failure in LLM training.

Three papers landed on arXiv today that cut across very different concerns - agent security, labor economics, and training internals - yet all share the same underlying problem: assumptions that seem reasonable in isolation turn out to be wrong in practice. Each paper delivers a number that should make practitioners stop and reconsider something they thought they understood.
TL;DR
- ClawSafety - Even the best-performing frontier model fails 40% of prompt injection attacks when running as a privileged agent; GPT-5.1 fails 75% of them
- Crashing Waves vs. Rising Tides - MIT's 17,000-evaluation study finds AI automation is gradual and broad rather than sudden, projecting 80-95% success rates on text tasks by 2029
- Normalization-Optimizer Coupling - Pairing Derf normalization with the Muon optimizer triples the performance gap versus AdamW, a failure that produces no obvious divergence to warn you
ClawSafety: "Safe" Models Break Inside Agents
The central assumption behind much of today's AI safety work is that if a model refuses harmful requests in a chat setting, it'll refuse them in an agent setting too. A paper from Bowen Wei and colleagues at arXiv:2604.01438 tests that assumption directly, and the results are bad.
The researchers built CLAWSAFETY, a benchmark with 120 adversarial scenarios distributed across five professional workspaces: software engineering, financial operations, healthcare administration, legal contract management, and DevOps. They ran five frontier models - Claude Sonnet 4.6, Gemini 2.5 Pro, Kimi K2.5, DeepSeek V3, and GPT-5.1 - through 2,520 sandboxed trials on the OpenClaw agent framework and measured attack success rates (ASR) across three injection vectors.
Attack Success Rates by Model
The numbers are stark.
| Model | Overall ASR |
|---|---|
| Claude Sonnet 4.6 | 40.0% |
| Gemini 2.5 Pro | 55.0% |
| Kimi K2.5 | 60.8% |
| DeepSeek V3 | 67.5% |
| GPT-5.1 | 75.0% |
Sonnet is clearly the most resistant, but a 40% failure rate on adversarial agentic scenarios isn't a safety story to be proud of. The paper notes that Sonnet maintains 0% ASR specifically on credential forwarding and destructive actions - a hard boundary no other tested model holds. For data exfiltration, though, even Sonnet fails 65% of the time. GPT-5.1 fails 93% of data exfiltration attempts.
Where the Attacks Land
Injection channel matters as much as model choice. Skill injection - where malicious instructions arrive embedded in a high-trust tool or plugin - succeeds 69.4% of the time on average. Email injection drops to 60.5%. Web content injection, which arrives through lower-trust channels, succeeds 38.4% of the time.
 UK Ministry of Defence cybersecurity team at work - agent deployment security requires operational context, not just model-level safety evaluation.
Source: wikimedia.org
UK Ministry of Defence cybersecurity team at work - agent deployment security requires operational context, not just model-level safety evaluation.
Source: wikimedia.org
The gap between skill injection and web injection reflects how trust levels spread through agent architectures. If a malicious instruction arrives in a file that the agent treats as a plugin specification, it gets more latitude than if it arrives in a scraped webpage. Attackers who can influence how tools or skills are constructed have the most reliable path to success.
One finding that should inform deployment decisions directly: scaffold choice shifts overall ASR by 8.6 percentage points. The same model on a different agent framework is meaningfully more or less vulnerable. The paper also found that longer conversations reduce vulnerability - at 10 turns, success rates dropped about 25-30 percentage points. Short-context, single-shot agent invocations are the most exposed.
This connects to earlier work on agent security in multi-agent setups. The picture that's emerging is consistent: safety evaluation in a chat demo tells you very little about what happens when that same model controls a filesystem, a database, or an email client. If you're running privileged agents in production, the OpenClaw hardening guide is worth reviewing alongside these results.
Crashing Waves vs. Rising Tides: What the Automation Curve Actually Looks Like
There are two popular narratives about how AI will automate work. One holds that capabilities will surge suddenly on narrow sets of tasks - jobs will be safe until they suddenly aren't. The other says capabilities are rising gradually across many tasks simultaneously, giving workers and institutions some lead time to adjust.
A new MIT FutureTech paper from Matthias Mertens, Neil Thompson, and seven co-authors (arXiv:2604.01363) provides the largest empirical test of these two scenarios so far. They ran more than 17,000 evaluations covering 3,000-plus labor-market tasks drawn from the U.S. Department of Labor's O*NET occupational classification system. Workers with direct job experience rated AI outputs on a 1-9 quality scale across tasks from more than 40 LLM models.
What They Found
The evidence strongly favors the "rising tides" model.
In 2024-Q2, frontier models completed tasks requiring 3-4 hours of human labor at roughly 50% success rate, using a threshold of 7/9 as "minimally sufficient" quality. By 2025-Q3, that number had reached approximately 65%. Tasks taking under an hour showed even higher success at 70% by 2025-Q3.
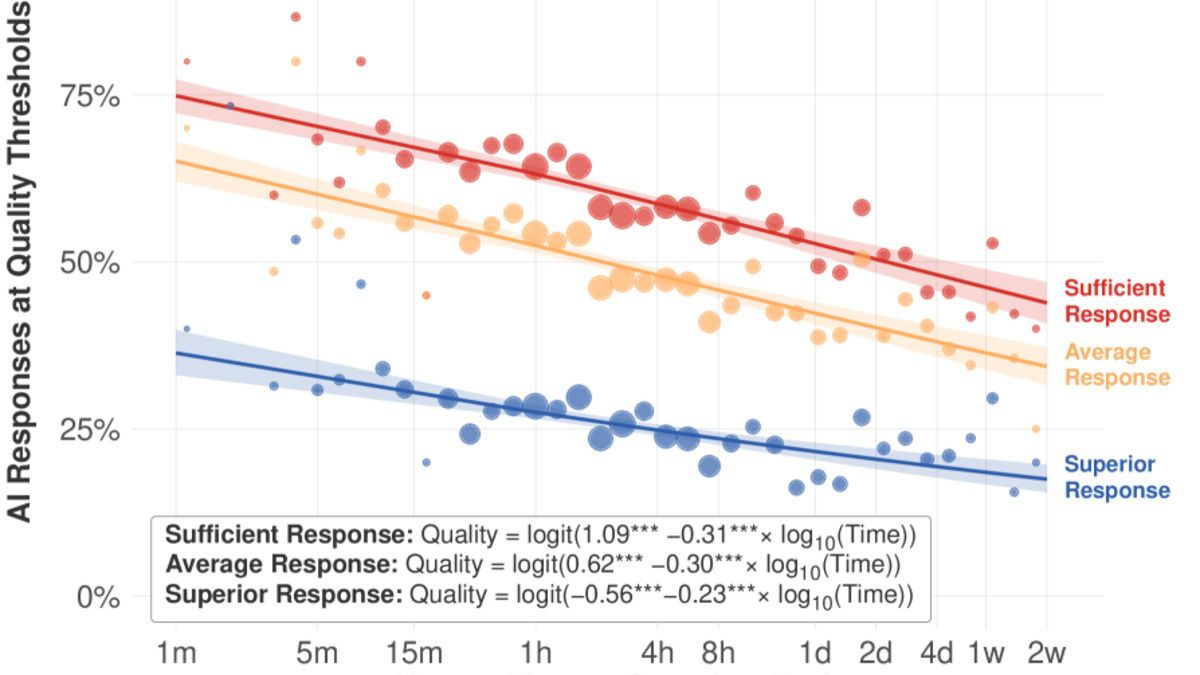 Figure from the paper showing AI task success rates across task duration ranges. The broad distribution of improvement contrasts with METR's earlier "crashing waves" finding.
Source: arxiv.org
Figure from the paper showing AI task success rates across task duration ranges. The broad distribution of improvement contrasts with METR's earlier "crashing waves" finding.
Source: arxiv.org
If those trends hold, the authors project 80-95% success rates on most text-related tasks by 2029 at minimally sufficient quality levels. Near-perfect performance would take longer.
The paper directly challenges earlier work from METR, which documented crashing waves - abrupt capability surges on specific narrow tasks. The authors attribute the mismatch to the nature of the tasks being assessed. METR's benchmark tasks are more stylized. O*NET tasks reflect actual job duties as described by workers, which are broader and more varied.
"This isn't inherently protective for workers - tides could still rise quickly - but it does suggest that workers and policymakers monitoring progress should be able to see AI improvement coming." - Neil Thompson, MIT FutureTech
Why This Framing Matters
The distinction between "crashing waves" and "rising tides" isn't just academic. It determines how much warning exists before a given occupation faces significant automation pressure. If capabilities surge suddenly and narrowly, workers in exposed roles may have very little time. If they rise gradually and broadly, the same workers should see the pressure building across years rather than quarters.
Thompson's caveat is honest: gradual doesn't mean slow. The projected path from 50% to 80%+ over roughly five years is fast by any historical standard for technological displacement. The finding is that it won't be invisible, not that it won't be disruptive.
Anthropic's own labor exposure study and Karpathy's analysis of AI's US economic footprint both suggest high white-collar task exposure. The MIT paper now adds a time axis: the exposure is real, the capability curve is measurable, and 2029 isn't far away.
The Hidden Cost of Normalization-Optimizer Coupling
Most LLM practitioners treat normalization layers and optimizer choice as independent decisions. You pick RMSNorm because it works well. You adopt Muon because it's faster than AdamW on matrix parameters. The assumption is that these choices don't interact.
Abdelrahman Abouzeid at Georgia Tech (arXiv:2604.01563) shows that assumption is wrong, at least for one pairing that's increasingly common in modern training runs.
The Derf-Muon Problem
Derf - Dynamic Erf normalization - has gained traction because it produces strong results under AdamW. Under Muon, the picture is very different.
Abouzeid ran a 3x2 factorial experiment at 1B parameters over 1,000 training steps, comparing three normalization schemes (Derf, Dynamic Tanh, RMSNorm) against two optimizers (AdamW, Muon). Under AdamW, Derf's performance gap versus RMSNorm is +0.31 nats. Under Muon, that gap widens to +0.97 nats - roughly a 3x deterioration for the same normalization choice with a different optimizer.
The dangerous part is the failure mode. There's no obvious divergence. Training proceeds, loss decreases, nothing looks wrong until you compare against a model trained with RMSNorm on the same run. The interaction loss is 0.66 nats, silent, and easy to miss if you're not running controlled comparisons.
Why It Happens
The paper identifies two failure mechanisms. Saturation causes lossy compression: Derf's activation function compresses values in ways that discard useful signal when gradients are scaled the way Muon scales them. Scale blindness is the second issue - Derf discards information about activation magnitude that Muon's update rule expects to be preserved.
Dynamic Tanh, which is bounded differently, shows no equivalent penalty under Muon. RMSNorm is unaffected. The problem is specific to Derf's interaction with Muon's orthogonalization-based update rule.
Practical Recovery
Two partial fixes are documented. An EMA-blend approach - mixing Derf activations with a running estimate - recovers around 84% of the performance gap. Reducing Derf's alpha hyperparameter from 0.5 to 0.3 recovers roughly 80% while keeping Derf's near-linear behavior in the low-activation range. Neither is a complete fix, but either is enough to make the combination usable if you're committed to both Derf and Muon.
The cleaner takeaway is to run normalization ablations whenever you change optimizers. Two choices that each look fine in isolation can interact in ways your loss curve won't tell you about.
The Common Thread
These three papers don't obviously belong together, but they share a structure. Each one identifies a case where a safe-looking default fails in a specific, measurable way that standard evaluation procedures won't catch. Safe models fail in agent contexts. Gradual automation curves look benign until you run the numbers. Normalization-optimizer mismatches hide behind normal-looking training logs.
That last point deserves weight. The failures documented here aren't edge cases or adversarial stress tests. They're what happens when you use reasonable, well-regarded components in combinations that haven't been explicitly tested. The gap between "works in the demo" and "works in production" is still wide, and still underestimated.
Sources:

