Tool-Use Tax, Jailbreak Risk, and Robot Vision
Three new papers: tools slow LLM agents under noisy prompts, jailbreaks barely dent frontier model capabilities, and interleaved text-vision traces push robot success to 95.5%.

Three papers out of arXiv this week that deserve attention: one that challenges a core assumption in agent design, one that rewrites how we should think about jailbreak risk, and one that shows robots plan better when they think in both words and pictures.
TL;DR
- Tool-Use Tax - Adding tools to LLM agents can hurt performance under semantic noise; native chain-of-thought often wins
- Jailbroken models retain capabilities - Claude Opus 4.6 loses only 7.7% benchmark performance when jailbroken; frontier safety cases can't assume capability degradation
- IVLR robot manipulation - Interleaving text subgoals with visual keyframes hits 95.5% on LIBERO; neither modality alone gets close
Are Tools All We Need? The Hidden Cost of Tool Calls
The prevailing assumption in agent engineering is straightforward: give LLMs tools, and they perform better. A paper from researchers at the University of Houston, USC, NYU, Texas A&M, and UC San Diego (arXiv:2605.00136) argues this assumption doesn't hold under real-world conditions.
The team introduced a concept they call the "tool-use tax" - performance degradation caused by the overhead of the tool-calling protocol itself, separate from whether the tool actually executes correctly. They built a factorized intervention framework to isolate three distinct cost sources: prompt formatting overhead, protocol interaction costs, and actual tool execution gains. Under clean conditions, tool gains usually outweigh the overhead. When semantic distractors enter the prompt - noise, irrelevant context, ambiguous phrasing - the math flips.
Why This Happens
The protocol layer is doing work the model wasn't trained to handle cleanly. Parsing tool schemas, formatting calls, handling return values - these are non-trivial cognitive tasks that draw on the same attention budget as reasoning. When the surrounding context gets noisy, the model's ability to handle protocol overhead degrades faster than its raw reasoning ability.
The authors tested native chain-of-thought (CoT) against tool-augmented reasoning across multiple noisy prompt configurations. In a sizable share of cases, native CoT won.
Their proposed fix is G-STEP, a lightweight inference-time gate that assesses whether invoking a tool is likely to help or hurt before making the call. They acknowledge it provides only partial improvement - the real fix is training models specifically on tool interaction under noisy inputs, not just clean benchmark scenarios.
Practitioners should read this before defaulting to tool augmentation. An agent with 12 tools and a noisy system prompt may perform worse than a simple CoT pipeline. This connects to earlier work we covered on unnecessary tool call patterns in deployed agents.
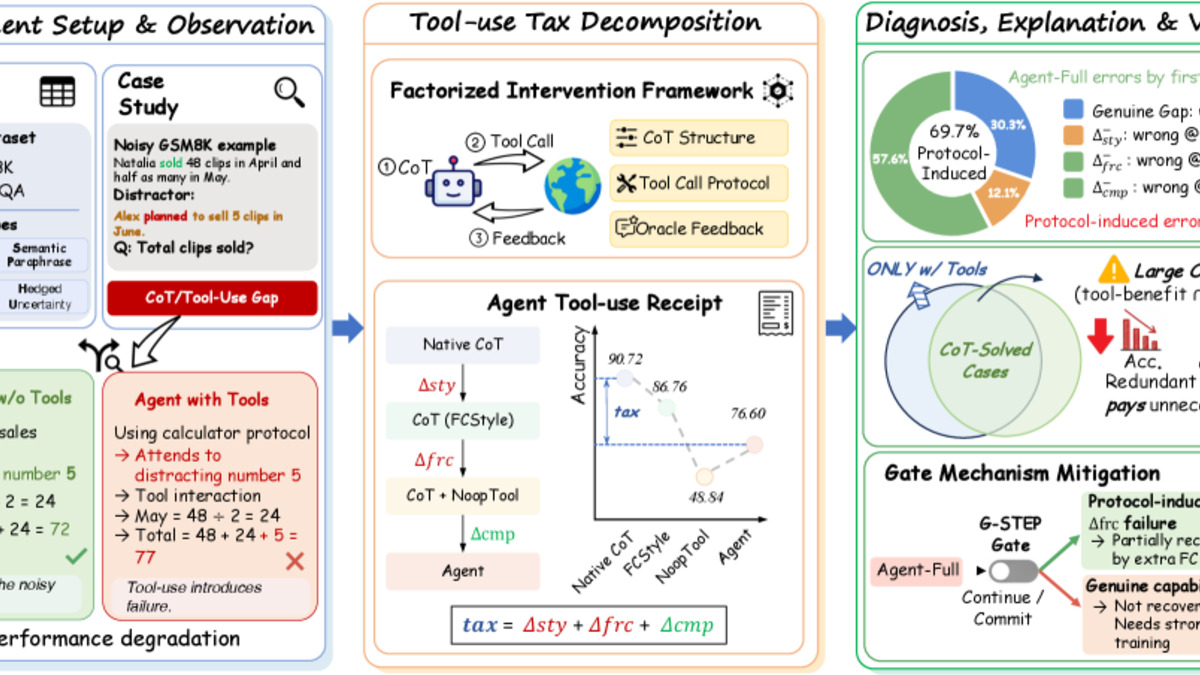 The paper's factorized framework separates formatting costs, protocol overhead, and actual computation gains - showing where the tool-use tax comes from.
Source: arxiv.org
The paper's factorized framework separates formatting costs, protocol overhead, and actual computation gains - showing where the tool-use tax comes from.
Source: arxiv.org
Jailbroken Frontier Models Mostly Still Work
A second paper (arXiv:2605.00267) delivers findings that should reshape how organizations think about frontier model safety. The research tested five Claude models - from Haiku 4.5 to Claude Opus 4.6 at maximum thinking effort - under advanced jailbreak conditions and measured capability retention.
The headline number: Opus 4.6 lost only 7.7% of average benchmark performance when successfully jailbroken. Haiku 4.5 lost 33.1%. The pattern is consistent and inverted from what most safety reasoning assumes.
The Inverse Scaling Problem
More capable models are harder to degrade through jailbreaks. The researchers found that advanced jailbreaks - sophisticated, hard-to-detect attacks - effectively impose near-zero capability reduction on frontier models. The model follows the adversarial instruction and remains almost fully functional for whatever task the attacker needs.
Reasoning-heavy tasks showed more degradation than knowledge-recall tasks across all models, which makes some intuitive sense. Getting a jailbroken model to recite facts it already knows is easier than getting it to reason through a novel problem under the cognitive constraints that a jailbreak imposes. But "more degradation" relative to other tasks still means a capable model doing useful harmful work.
The authors' recommendation is direct: safety cases for frontier models shouldn't assume a jailbreak degrades capability meaningfully. Any safety argument that includes language like "even if the model is jailbroken, it won't be able to..." deserves immediate scrutiny.
The most advanced jailbreaks effectively yield no reduction in model capabilities - stronger models are more resilient to degradation, not less.
This isn't a new observation at a philosophical level, but having it quantified across a capability range is new. It shifts the locus of safety work away from "make jailbreaks harder" and toward "limit what a successfully jailbroken model can access." Sandboxing, capability controls, and output monitoring become more important, not less, as models improve.
For comparison: previous work on safety alignment with small training sets focused on steering model behavior during training. This paper is a reminder that post-deployment, behavioral steering doesn't prevent the most capable models from functioning once a jailbreak succeeds.
Robots That Think in Text and Images Together
 Long-horizon robot manipulation requires maintaining both spatial context and task state across many sequential steps.
Source: unsplash.com
Long-horizon robot manipulation requires maintaining both spatial context and task state across many sequential steps.
Source: unsplash.com
The third paper (arXiv:2605.00438) tackles a concrete problem in robot manipulation: how do you get a robot to plan and execute long sequences of actions - open the drawer, pick up the object, place it in the container - without losing track of where it's in the sequence?
The team's answer is interleaved traces. During planning, the model creates an explicit sequence that alternates between text subgoals ("reach for the drawer handle") and visual keyframes showing the expected scene state at each step. A closed-loop action decoder then guides physical execution against this trace.
Results on LIBERO
On the LIBERO benchmark - a standard test for long-horizon manipulation - interleaved traces hit 95.5% average success across tasks, with 92.4% specifically on long-horizon tasks. For context: text-only traces hit 62.0%, vision-only traces got 68.4%. The combination is not additive; it's substantially better than either alone.
The researchers note that performance degrades when the global plan goes stale - if the environment changes unexpectedly, a plan built on outdated visual keyframes becomes actively misleading. That's a real limitation for deployment outside of controlled settings.
What makes this practically interesting is how they got training data. Robot datasets don't come with interleaved text-vision traces attached. The team produced pseudo-supervision by segmenting existing robot demonstrations, then using a vision-language model to caption each stage. It's a smart use of existing data that doesn't require re-collecting expensive robot trajectories.
On SimplerEnv-WidowX, a more challenging transfer benchmark, the approach achieved 59.4% overall success. Not perfect, but it shows the approach generalizes beyond the benchmark it was tuned on.
The connection to the safety paper above is worth noting. Work on unsafe robots showed medical robots violating safety constraints in over half of tested cases. Solid planning traces that give a system an explicit, checkable representation of its intended sequence are one possible path toward more auditable robotic behavior - not a solution to safety on their own, but a necessary foundation.
Connecting the Threads
All three papers are, in different ways, about the gap between benchmark conditions and real-world deployment. Tool-augmented agents underperform when prompts get messy. Jailbreak safety relies on assumptions that don't hold for the most capable models. Robot planners succeed on known benchmarks but degrade when the environment diverges from their plan.
The common pattern: improvements at evaluation time tend to look cleaner than improvements at deployment time. That's not a reason to distrust the research - it's a reason to design systems assuming the evaluation conditions won't hold.
Sources:
