Tool Blindness, Tree Search, and the Road to ASI
Three new papers expose a 50-point gap in agent tool knowledge, show tree search tripling inference throughput, and map the research between AGI and superintelligence.

Three papers landed today that operate at very different scales but point toward the same uncomfortable idea: we're building increasingly capable AI systems on foundations we don't fully understand. One diagnoses a hidden failure mode in how agents retrieve tool knowledge. Another offers a structural fix for autonomous agent reasoning. The third asks what happens after the systems we're building right now actually work.
TL;DR
- ToolSense - Agents score 50-64 points lower on realistic tool retrieval than standard benchmarks suggest, a gap almost nobody is measuring
- Arbor - AMD researchers use tree search as explicit shared working memory across agents, reaching 193% inference throughput-latency improvement over vendor-optimized baselines
- From AGI to ASI - A 14-author DeepMind team maps four pathways to superintelligence and argues the transition will be a series of societal disruptions, not a single event
ToolSense: The Tool Knowledge Illusion
If your agent is routing over hundreds of tools, it's probably far less capable than your benchmarks suggest.
That's the core finding from Ashutosh Hathidara, Sai Shruthi Sistla, Sebastian Schreiber, and Sahil Bansal, who introduce ToolSense, an open-source diagnostic framework for measuring what LLMs actually know about their tools versus what they appear to know when given full tool descriptions at inference time. The distinction matters because modern tool-augmented agents often rely on parametric tool retrieval - encoding tool knowledge directly in model weights as virtual tokens, rather than injecting full tool specs into every context window. Standard benchmarks assess agents with fully-specified descriptions available. ToolSense tests whether the model has genuinely internalized the knowledge it needs to work without that scaffolding.
The results are stark. The paper introduces three benchmark types: a Realistic Retrieval Benchmark (RRB) built from real-world, messy tool queries; MCQ probing, which tests factual tool knowledge in multiple-choice format; and QA probing with open-ended questions. When assessed on RRB - the conditions that actually resemble deployment - models collapse by 50 to 64 percentage points compared to their scores on fully-specified benchmarks. Several models score near-random on factual tool probes completely.
The authors call this knowledge-retrieval dissociation: models can retrieve the right tool when given its description on a platter but lack the internalized understanding to do so in realistic conditions. This has direct implications for anyone scaling AI agents over large tool catalogs, where you cannot include full specs for every possible tool in every prompt.
ToolSense is open-source, which means teams can run their own audits rather than trusting aggregate benchmark numbers. That's the practical upshot - a concrete way to find out whether your agent's tool knowledge is real or a benchmark artifact.
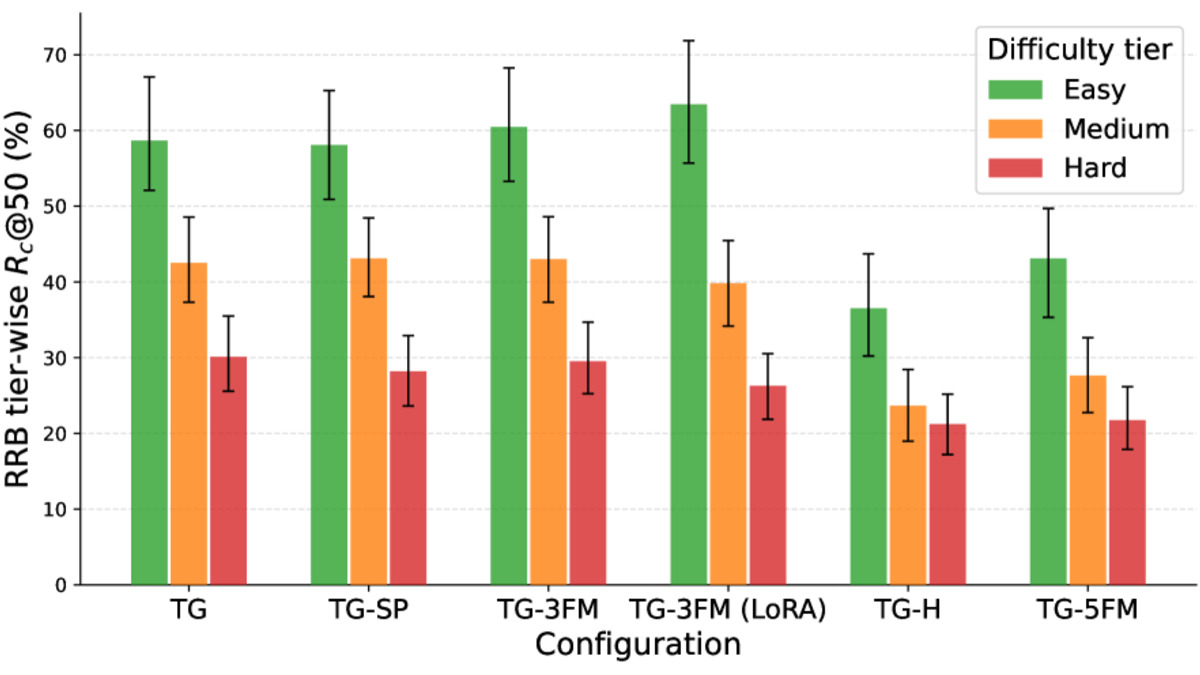 RRB recall scores (R_C@50) by difficulty tier across model configurations. Hard-tier performance sits between 21% and 31% for most setups - far below what standard benchmarks would suggest.
Source: arxiv.org
RRB recall scores (R_C@50) by difficulty tier across model configurations. Hard-tier performance sits between 21% and 31% for most setups - far below what standard benchmarks would suggest.
Source: arxiv.org
Why Benchmarks Lie
The pattern ToolSense identifies isn't unique to tool retrieval. Assessing models under conditions that don't match deployment is a known failure mode across function-calling benchmarks - the metrics that look good in controlled settings often don't survive contact with production workloads. ToolSense at least gives practitioners a principled way to measure the gap before it surfaces as an incident.
Arbor: Tree Search as Working Memory
Researchers at AMD - Neha Prakriya, Chaojun Hou, Zheng Gong, Huasha Zhao, Xi Zhao, Mou Li, Zhenyu Gu, and Emad Barsoum - present Arbor, a multi-agent framework that treats tree search not as an external optimization step but as a cognition layer built directly into agent architecture. The core idea is that autonomous agents working in large, stateful action spaces need structured working memory. Arbor maintains an explicit search tree of scored hypotheses, shared across all agents in a system. Hypotheses branch from parent nodes, each scored by a Critic agent. Failed paths don't disappear - they become diagnostic signals that inform the search direction from now on.
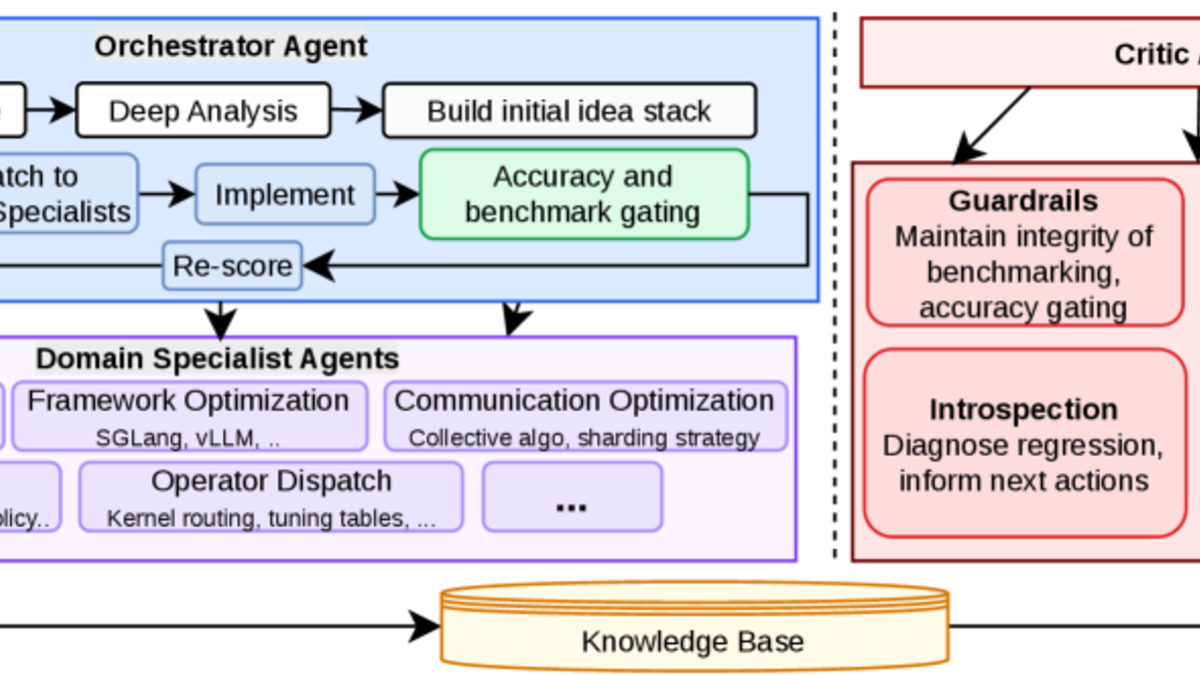 The Arbor architecture: an Orchestrator manages the search tree, Domain Specialist agents execute hypotheses, and a Critic assesses results and drives the next search direction.
Source: arxiv.org
The Arbor architecture: an Orchestrator manages the search tree, Domain Specialist agents execute hypotheses, and a Critic assesses results and drives the next search direction.
Source: arxiv.org
The team validates Arbor on LLM inference optimization, a domain with a large, complex configuration space and verifiable performance metrics. The multi-agent setup uses three roles: an Orchestrator that manages the search tree and coordinates agents, a Domain Specialist that executes specific hypotheses, and a Critic that evaluates results and assigns scores. This maps naturally onto the way expert teams actually work - one person directing, one executing, one reviewing.
The throughput numbers are significant. Arbor achieves up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines, with less than 2% run-to-run variance across multiple hardware generations. The consistency matters as much as the peak number - variance in optimization results is a common failure mode for agents working in complex spaces, where lucky runs can mask unreliable underlying performance.
What Makes This Different
Tree-of-thought and similar approaches have been around for several years. What Arbor adds is the explicit persistence of the search tree as shared working memory between agents, rather than regenerating it per call, and the treatment of failure as structured information rather than noise. The Critic agent closes a feedback loop that most multi-agent frameworks leave open.
The agentic AI benchmarks that currently dominate evaluation mostly test task completion rates on narrow domains. Arbor's contribution is more architectural - showing that how agents represent their search state affects downstream performance substantially.
From AGI to ASI: DeepMind Draws the Map
The third paper is different in kind from the first two. Tim Genewein, Matija Franklin, Alexander Lerchner, Laurent Orseau, Samuel Albanie, and nine co-authors - including Marcus Hutter (AIXI) and Shane Legg (DeepMind co-founder) - aren't reporting experimental results. They're mapping the territory between AGI and artificial superintelligence, identifying four distinct pathways by which current AI systems might evolve into ASI:
- Scaling AGI - extending current systems through more compute, data, and improved training
- Architectural breakthroughs - qualitatively new AI approaches that supersede current architectures
- Recursive improvement - AI systems that improve their own training procedures or architectures
- Multi-agent emergence - superintelligence arising from large collectives of coordinating AGI agents
The fourth pathway is worth pausing on. Most popular thinking about ASI imagines a single powerful system. The DeepMind team explicitly models the possibility of ASI as an emergent property of coordinated AI systems working together - which maps uncomfortably well onto infrastructure being built right now.
The paper's stance on timing is remarkable for its specificity. Rather than treating ASI as a single event - "the moment" - the authors argue that "society will likely experience a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology." That's a more useful framing for AI safety research because it means there's no single intervention point, and bottlenecks along each pathway need to be studied independently.
The Research Agenda
What the paper isn't is a technical solution. It explicitly sets out "concrete research questions" along each pathway - intended as a map for where effort should go, not evidence that the problems are solved. The ask is for "a massively interdisciplinary endeavour of global scope," which is accurate and also, given the current state of AI governance, somewhat optimistic.
But the value of a paper like this from a team like this is precisely its function as a coordination tool. When Hutter and Legg agree on a taxonomy of ASI pathways, it shapes how the field thinks about the problem space. The reasoning capabilities that make recursive self-improvement plausible are the same ones being rapidly scaled today - so the timelines in this paper aren't purely theoretical.
The Thread Connecting All Three
Taken together, these papers circle a shared problem: AI systems that look capable under controlled conditions may not behave as expected in deployment, and we don't have the right tools to measure the gap.
ToolSense finds that measurement gap in tool retrieval. Arbor offers a structural fix for agent reasoning stability. The DeepMind paper asks what happens when those gaps remain unmeasured long enough that the systems in question have become qualitatively more powerful than anything we're assessing today. None of the three offers a clean answer. All three are doing work the field actually needs.
Sources:
- ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs - Hathidara et al., arXiv 2606.12451
- Arbor: Tree Search as a Cognition Layer for Autonomous Agents - Prakriya et al., arXiv 2606.12563
- From AGI to ASI - Genewein et al., arXiv 2606.12683
