Tandem Training, World Models, and Efficient Agents
Three new arXiv papers on making RL reasoning legible across models, fixing broken world model latent states, and training small agents to beat their teachers.

Three papers from today's arXiv submissions caught my attention. One tackles a quiet problem with RLVR - the reasoning it produces often isn't usable by anyone except the model that produced it. Another fixes a structural flaw in LLM-based world models that silently breaks planning. The third shows a smarter way to train small agents, one that manages to beat both the distillation baseline and the RL baseline, and even beat the teacher.
TL;DR
- Tandem RL - Senior models trained with frozen junior models produce reasoning that weaker models (and humans) can actually follow, without losing solo performance
- Textual Belief States - Forcing world models to route predictions through a discrete latent state yields 57% better representation quality and 98% better rollouts
- ATOD - Annealed scheduling between imitation and RL lets small agents beat GRPO by 23.62 percentage points across three benchmarks
When Your Reasoning Is Only Legible to Yourself
Reinforcement learning with verifiable rewards (RLVR) has become one of the dominant training approaches for pushing LLM reasoning performance. The problem isn't whether it works - on competition math, it clearly does. The problem is what it produces: chains of thought that drift toward idiosyncratic patterns, poor readability, and language mixing that makes the reasoning hard to follow for any model other than the one that produced it.
A new paper from Difan Jiao, Raghav Singhal, Robert West, and Ashton Anderson introduces Tandem Reinforcement Learning (TRL) as a direct fix for this compatibility problem. The setup pairs a trained "senior" model with a frozen "junior" model. During rollout generation, the two alternate stochastically - the senior creates some tokens, the junior creates others, and the resulting output is treated as a team product. Both are rewarded together, so the senior is implicitly pushed to reason in ways the junior can follow.
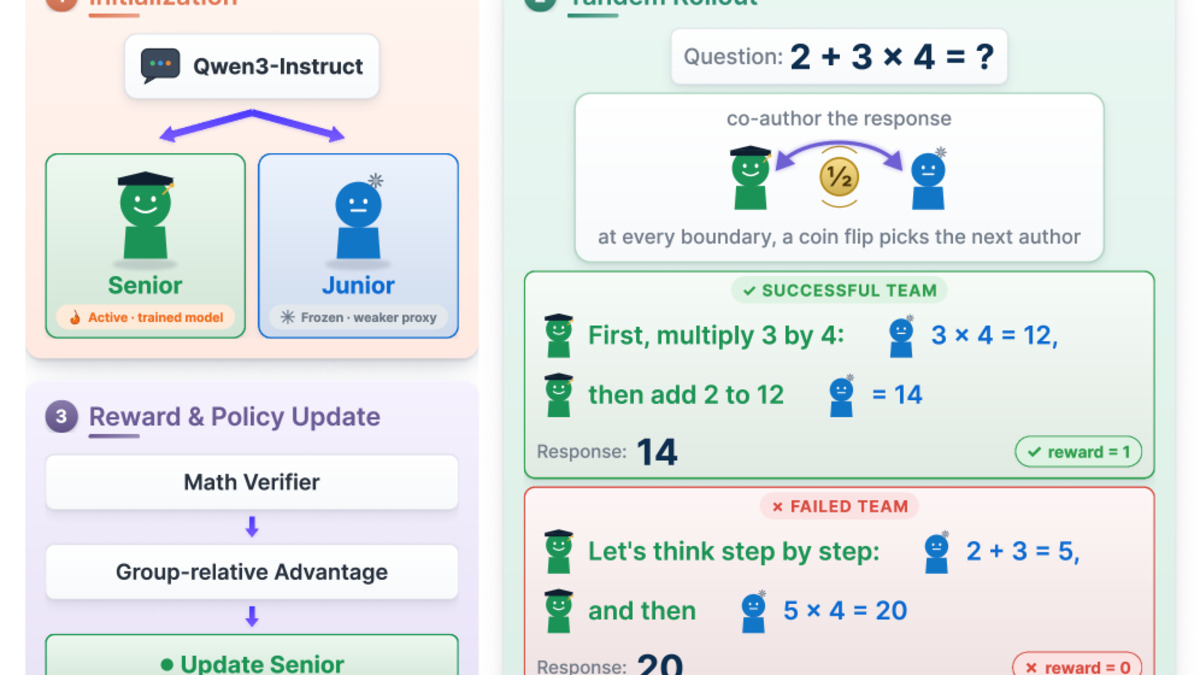 The TRL training loop: senior and junior models alternate token generation; the team reward incentivizes the senior to produce legible reasoning chains.
Source: arxiv.org
The TRL training loop: senior and junior models alternate token generation; the team reward incentivizes the senior to produce legible reasoning chains.
Source: arxiv.org
The core insight is that handoff robustness and legibility aren't separate objectives you optimize for - they emerge from the shared rollout structure when you reward the pair rather than the individual.
The researchers trained Qwen3-4B-Instruct on competition mathematics and found that TRL matched vanilla GRPO on solo reasoning capability while producing three additional properties: stronger handoff robustness with the junior, reduced distributional drift from the junior's perspective, and chains of thought that are more legible to the junior. All three came from the same rollout structure, without separate objectives.
This has real effects for multi-agent pipelines where models hand off reasoning between steps. If the senior was trained in isolation, its reasoning may be technically correct but practically opaque to whatever smaller model processes it next.
Fixing the Hidden Flaw in LLM World Models
World models for partially observed environments need a latent representation that summarizes interaction history. In theory, if your latent state is good, your predictions should be good. In practice, with LLM-based architectures, there's a structural bypass: predictions can leak around the latent state completely, drawing directly from the raw interaction history. When that happens, prediction accuracy stops reflecting representation quality. You can have a model that predicts correctly while its latent state contains nothing useful.
Xiang Gao, Kaiwen Dong, Yuguang Yao, Padmaja Jonnalagedda, and Kamalika Das formalize this problem and propose a fix in their paper on Textual Belief States. The key requirement is strict latent state mediation: predictions must depend only on the latent state and the current action, never on the full history. Enforcing this makes the latent state identifiable - you can actually measure whether it's good.
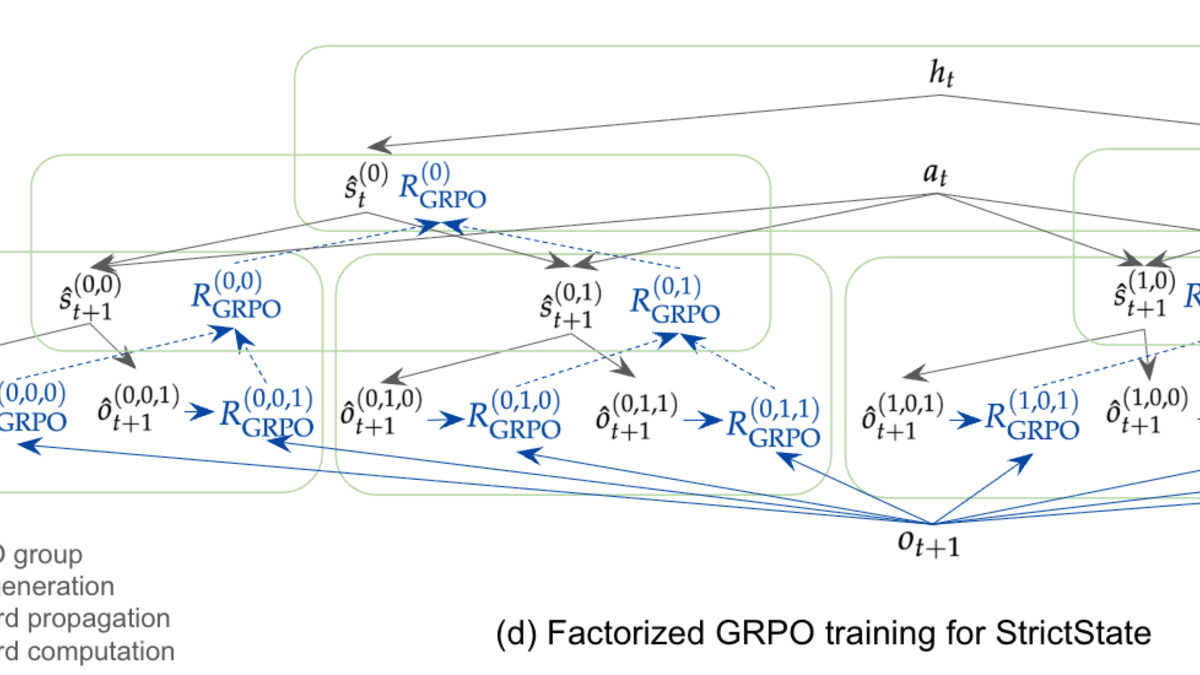 Three world model formulations: stateless, leaky-state, and strict-state. The strict-state variant, trained with fGRPO, forces all prediction signal to pass through a discrete textual latent.
Source: arxiv.org
Three world model formulations: stateless, leaky-state, and strict-state. The strict-state variant, trained with fGRPO, forces all prediction signal to pass through a discrete textual latent.
Source: arxiv.org
The paper introduces two concrete contributions. First, discrete textual latent states: variable-length, interpretable representations suited to text-based environments. Second, a training method called factorized GRPO (fGRPO), a tree-structured reinforcement learning approach that enforces strict mediation during optimization.
Results on TextWorld and ScienceWorld show up to 57% gains in representation quality and 98% improvements in rollout performance over baselines. The gains grew with task complexity and planning horizon, which is where better latent representations matter most.
We covered a similar world model efficiency problem last April when LeCun's group showed JEPA world models could plan roughly 47x faster by stripping down to two loss terms. This paper attacks a different failure mode - not speed, but the silent disconnect between prediction accuracy and representation quality.
Teaching Small Agents to Beat Their Teachers
Training small language model agents on long-horizon interactive tasks is harder than it looks. On-policy distillation (OPD) gives you dense teacher guidance and fast early gains, but the ceiling is the teacher. Once the student approaches teacher performance, there's nowhere to go. Pure reinforcement learning can theoretically exceed the teacher by exploring beyond imitation, but sparse, delayed rewards make early training slow.
Qitai Tan, Zefang Zong, Yang Li, and Peng Chen describe ATOD (Annealed Turn-aware On-policy Distillation), a method that combines both approaches with a schedule that transitions between them. Early training leans on distillation for dense signal; as performance improves, the weight shifts toward RL for exploratory gain. The annealing is smooth rather than a hard switch.
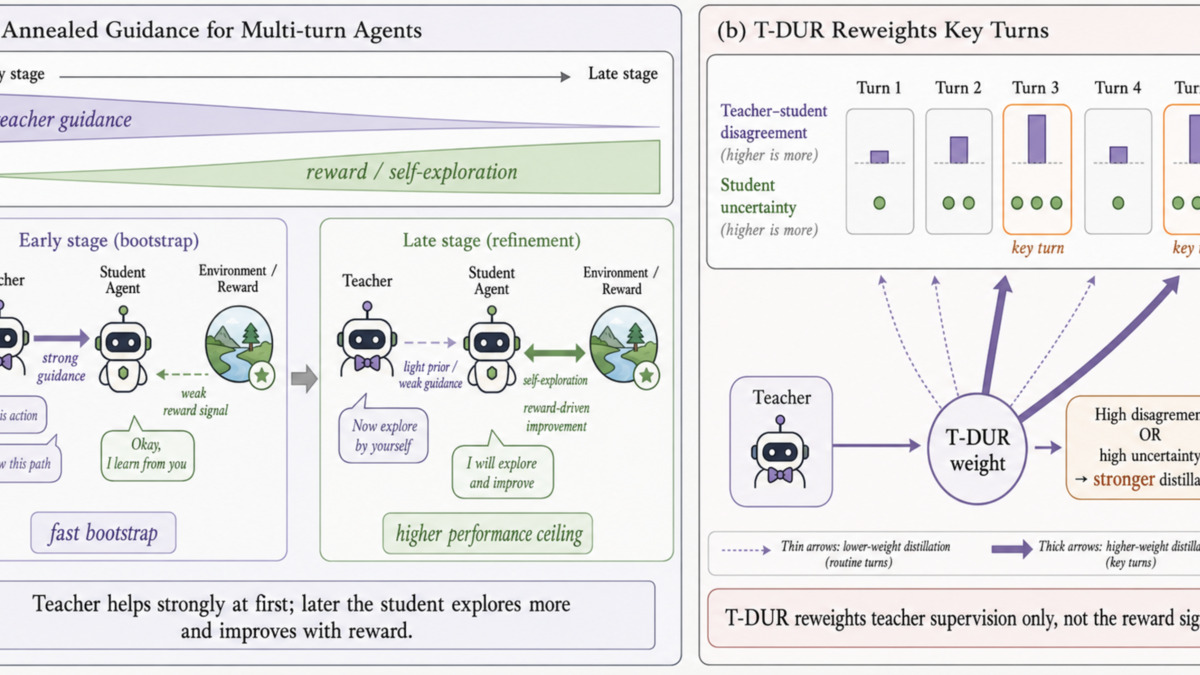 ATOD's training schedule: imitation weight starts high and decays as RL weight grows, letting the agent exploit teacher guidance early and explore independently later.
Source: arxiv.org
ATOD's training schedule: imitation weight starts high and decays as RL weight grows, letting the agent exploit teacher guidance early and explore independently later.
Source: arxiv.org
The second component is T-DUR (Turn-level Disagreement-Uncertainty Reweighting), which selectively upweights high-value turns within multi-turn trajectories. In long interactive tasks, not all turns are equally informative. T-DUR pushes training signal toward the turns where teacher and student diverge most.
Evaluated across ALFWorld, WebShop, and Search-QA, ATOD beats the OPD baseline by 3.03 percentage points in average success rate, GRPO by 23.62 points, and - notably - the teacher model itself by 2.16 points. Surpassing the teacher isn't guaranteed when you mix distillation and RL, since the RL signal can be noisy. That the combination produces consistent gains across three different environments suggests the method is more than benchmark-fitting.
Earlier work showed that distillation can silently transfer unsafe behaviors alongside capabilities - which is worth keeping in mind when building pipelines that mix distillation and RL on the same agent.
What These Papers Share
All three papers address a version of the same structural problem: the gap between what a model produces for itself and what's useful in context. Tandem RL addresses reasoning legibility across model sizes. Textual belief states address the bypass between prediction accuracy and representation quality. ATOD addresses the ceiling imposed by single-method training.
None of these are gradual benchmark improvements. Each identifies a clean failure mode, proposes a targeted fix, and validates it with numbers that are large enough to matter in practice. That's what the better research papers do.
Sources:
