Self-Organizing Agents, Brain-Like LLMs, AI Discovery
Three new papers: self-organizing multi-agent systems beat rigid hierarchies by 14%, LLMs spontaneously develop brain-like layer specialization, and AI evolves scientific ideas through literature exploration.

Three papers this week probe a question that keeps coming up in AI research: where does good structure come from? One study ran 25,000 tasks to find out whether you should design your multi-agent system or just let it figure itself out. Another dissected what's actually happening inside LLM layers when they reason - and found something that looks a lot like a brain. A third built a system that learns to produce novel scientific ideas by evolving them like organisms.
TL;DR
- Drop the Hierarchy and Roles - Self-organizing agents with fixed ordering but autonomous role selection outperform designed hierarchies by 14% across 25,000 tasks
- Spontaneous Functional Differentiation in LLMs - LLM middle layers spontaneously develop brain-like synergistic processing cores that are essential for abstract reasoning
- FlowPIE - Coupling literature retrieval with idea generation as a co-evolving process produces more novel, feasible, and diverse scientific ideas than static approaches
Drop the Hierarchy: Self-Organizing Agents Win
The dominant wisdom in multi-agent AI systems is that you need structure - assign roles, define a coordinator, organize the hierarchy. Victoria Dochkina's paper, Drop the Hierarchy and Roles: How Self-Organizing LLM Agents Outperform Designed Structures, runs the largest controlled experiment on this question to date and reaches a different conclusion.
The study covers 25,000 tasks across 8 LLM models, 4 to 256 agents, and 8 coordination protocols. The core finding: a hybrid "Sequential" protocol - where agents process tasks in a fixed order but autonomously choose their own roles based on what the previous agent did - beats a centralized coordinator by 14% (p<0.001) and fully autonomous systems by 44% (Cohen's d=1.86, p<0.0001).
The emergent behavior is striking. With just 8 agents under the Sequential protocol, the system generated 5,006 unique role names across the experiment - 54% of them used exactly once. Agents aren't slotting into predefined categories; they're inventing whatever specialization the current task needs. In one experiment, 38 of 60 non-participating agents withdrew themselves voluntarily rather than being excluded by a coordinator.
 The honeycomb is a classic example of emergent structure without a central designer - each bee follows local rules, and complex order appears. The new research shows LLM agents can do the same.
Source: unsplash.com
The honeycomb is a classic example of emergent structure without a central designer - each bee follows local rules, and complex order appears. The new research shows LLM agents can do the same.
Source: unsplash.com
What you need for self-organization to work
The caveat is important: self-organization only helps strong models. Claude Sonnet 4.6 gained 3.5% from free-form role assignment. GLM-5 lost 9.6%. The paper identifies three capabilities a model needs to benefit from self-organization: self-reflection, deep reasoning, and reliable instruction-following. Without all three, rigid structure is better.
Scalability held up. Running from 64 to 256 agents, quality showed no statistically significant degradation (Kruskal-Wallis test: H=1.84, p=0.61). And open-source models aren't far behind: DeepSeek v3.2 hit 95% of Claude's quality at 24x lower cost on complex tasks.
Protocol choice accounts for 44% of quality differences across the experiment. Model choice accounts for ~14%. Most teams are optimizing the wrong variable.
This connects to earlier research on multi-agent coordination failures - there it was constitutional rules that shaped agent behavior, here it's protocol choice. The consistent thread: what you leave unspecified matters as much as what you define.
For practitioners building multi-agent pipelines, the practical takeaway is to define the mission and values clearly, then pick a protocol that allows capable models to self-organize. Don't spend time designing role taxonomies.
LLMs Have a Brain. Sort Of.
The interpretability finding in Spontaneous Functional Differentiation in Large Language Models: A Brain-Like Intelligence Economy from Junjie Zhang, Zhen Shen, Gang Xiong, and Xisong Dong is one worth pausing on. The paper was accepted at AAAI-MAKE 2026.
Using Integrated Information Decomposition across multiple LLM architectures, the researchers mapped how information flows differently through each layer. Middle layers turn out to handle synergistic processing - combining inputs in ways where the integrated result carries more information than any of the individual inputs would suggest. Early and late layers, by contrast, rely on redundant processing.
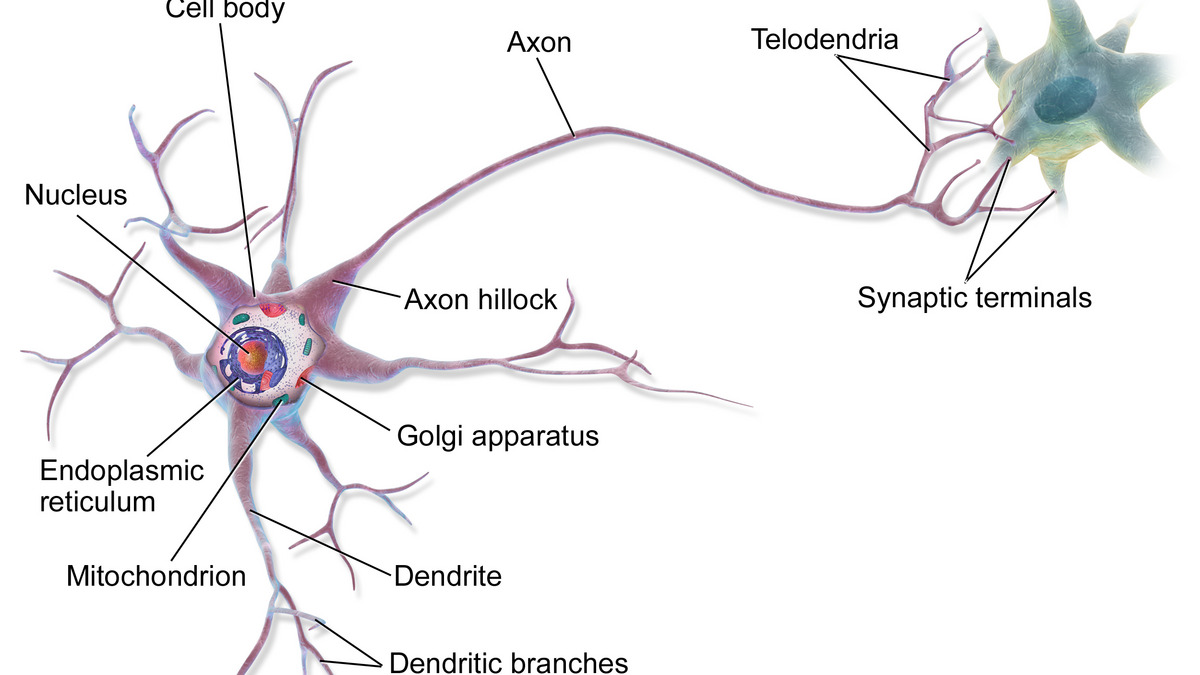 Biological neurons integrate signals from many sources before firing - the new paper finds LLM middle layers do something structurally similar with information.
Source: commons.wikimedia.org
Biological neurons integrate signals from many sources before firing - the new paper finds LLM middle layers do something structurally similar with information.
Source: commons.wikimedia.org
That's not a loose analogy to biology - it's the same organizational pattern you see in the human brain, where specialized regions integrate information non-redundantly while other regions handle more straightforward signal relay.
Why this matters for reasoning
The ablation results make the case. Remove the synergistic middle-layer components and performance collapses. These aren't unnecessary processing nodes that the network can route around - they're the substrate for abstract reasoning. The paper describes the specialization as emerging through "a physical phase transition as task complexity increases," meaning simple tasks don't trigger full synergistic processing, but harder tasks do.
This has direct implications for how we interpret interpretability research on LLM internals. Prior work has struggled to explain why some interventions on internal representations work and others don't. If middle layers handle qualitatively different information processing than outer layers, you'd expect any uniform analysis to produce inconsistent results.
The practical upshot is modest but real: if you're doing mechanistic interpretability work, or building probes to monitor LLM reasoning, treat middle layers as a distinct zone. Probe design and layer-wise analysis that ignores this structure is working against the model's actual organization.
Teaching AI to Have Research Ideas
FlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration takes on a specific and hard problem - can an AI system produce truly novel scientific ideas, not just recombinations of what it already knows?
The core critique the paper makes is of the standard retrieval-then-generation approach: you search for relevant literature, then produce ideas from it. The problem is that retrieval is static. You get a snapshot of papers and work within it. The system can't change what it looks for based on what ideas are emerging, and it can't pull in cross-domain knowledge that it didn't know to search for at the start.
FlowPIE treats literature exploration and idea generation as a coupled process. A flow-guided Monte Carlo Tree Search, inspired by GFlowNets, expands literature trajectories based on a generative reward model that assesses the quality of current ideas - not just document relevance. If an idea is getting interesting, the search expands in that direction.
 Scientific discovery rarely follows a straight line from literature review to hypothesis. FlowPIE models the back-and-forth more faithfully.
Source: unsplash.com
Scientific discovery rarely follows a straight line from literature review to hypothesis. FlowPIE models the back-and-forth more faithfully.
Source: unsplash.com
The evolutionary layer
On top of the literature search, FlowPIE applies evolutionary operations - selection, crossover, and mutation - to the population of ideas being produced. An "isolation island" approach deliberately pulls in cross-domain literature to prevent the system from converging on variations of the same concept.
Evaluations show FlowPIE produces ideas with higher novelty, feasibility, and diversity compared to both strong standalone LLMs and agent-based frameworks. It also enables reward scaling during test time, meaning you can trade compute for better ideas in a predictable way - a property that most current approaches don't have.
The hyperagents and efficiency research covered here previously showed how metacognitive processes can improve agent performance. FlowPIE applies a similar metacognitive loop at the level of scientific discovery itself: the system assesses what it's creating and reshapes its search accordingly.
The Common Thread
All three papers circle the same underlying question from different angles. Self-organizing agents discover structure without being told what structure to use. LLM layers develop specialized processing without anyone designing them to. FlowPIE's ideas evolve into novelty rather than being retrieved whole.
The constraint that turns out to matter isn't the structure you impose - it's the scaffolding that allows structure to emerge. For agents, that's the coordination protocol. For LLMs, it's the depth of the network and task difficulty. For idea generation, it's the fitness function that steers evolution.
None of these systems needed more design. They needed better conditions.
Sources:

