Self-Correcting Models, Smarter Monitors, AI Designs Itself
Three new papers tackle critique dependency in LLMs, ensemble monitoring for AI control, and agents that autonomously discover better neural architectures.

Three papers from Monday's arXiv drop orbit the same underlying question: how much does current AI depend on scaffolding it can't sustain at scale? Researchers this week tackle that gap from different angles - by training critique out of the inference loop, by building monitoring systems tuned for real deployment, and by putting agents in charge of designing the models themselves.
TL;DR
- ICRL - Training solvers to internalize critique guidance yields 6.4-point gains over standard RL on agentic tasks, with an 8B critic matching 32B models
- Ensemble Monitoring - A varied 3-monitor setup detects misaligned agent behavior 2.4x better than three identical monitors at the same compute cost
- AIRA - AI agents at Meta autonomously discover neural architectures that outscale Llama 3.2 by up to 71% in compute efficiency
ICRL: When Models Actually Learn to Self-Correct
Most self-refining LLMs share an uncomfortable fact: they don't actually improve. They perform better when critique is present in the prompt, but strip away the feedback and they revert. The guidance never made it into the weights.
A team led by Jianbo Lin addresses this directly with ICRL (Learning to Internalize Self-Critique with Reinforcement Learning, arXiv:2605.15224). The core idea is deceptively clean: rather than training a model to respond well to critique, train it to absorb what critique shows and fold that into unassisted capability.
How the Joint Training Works
The framework trains a solver and critic from a shared backbone - the paper uses Qwen3-4B and Qwen3-8B. The critic is rewarded based on the solver's subsequent performance gain after receiving feedback, not the immediate quality of its response. This pushes the critic toward actionable signals rather than plausible-sounding commentary that sounds useful but isn't.
Distribution shift is the hard problem here. A solver trained with critique in context starts expecting that context. ICRL introduces a distribution-calibration reweighting ratio that selectively transfers only the critique-guided improvements compatible with the solver's own prompt distribution - so the solver truly builds capability rather than adapting to a new conditional.
A role-wise group advantage estimation stabilizes the joint optimization across both roles.
Results: Average gains of 6.4 points over GRPO on agentic tasks, and 7.0 points on mathematical reasoning. The standout finding: the trained 8B critic matches 32B critics while using substantially fewer tokens. That has direct effects for deployment costs - you don't need a massive external reviewer to get the benefit.
The learned 8B critic is comparable to 32B critics while using substantially fewer tokens.
This connects to earlier work we covered on self-correction traps in language models - the pattern of models improving during critique-conditioned inference but failing without it is well-documented. ICRL's contribution is a concrete training procedure that breaks the dependency rather than just diagnosing it.
For practitioners building self-refining pipelines, the paper is a direct challenge to the reflexion-style paradigm. Systems that require a critique oracle at inference time carry a fragility that costs money and limits deployment scope. Code is available at github.com/brick-pid/ICRL.
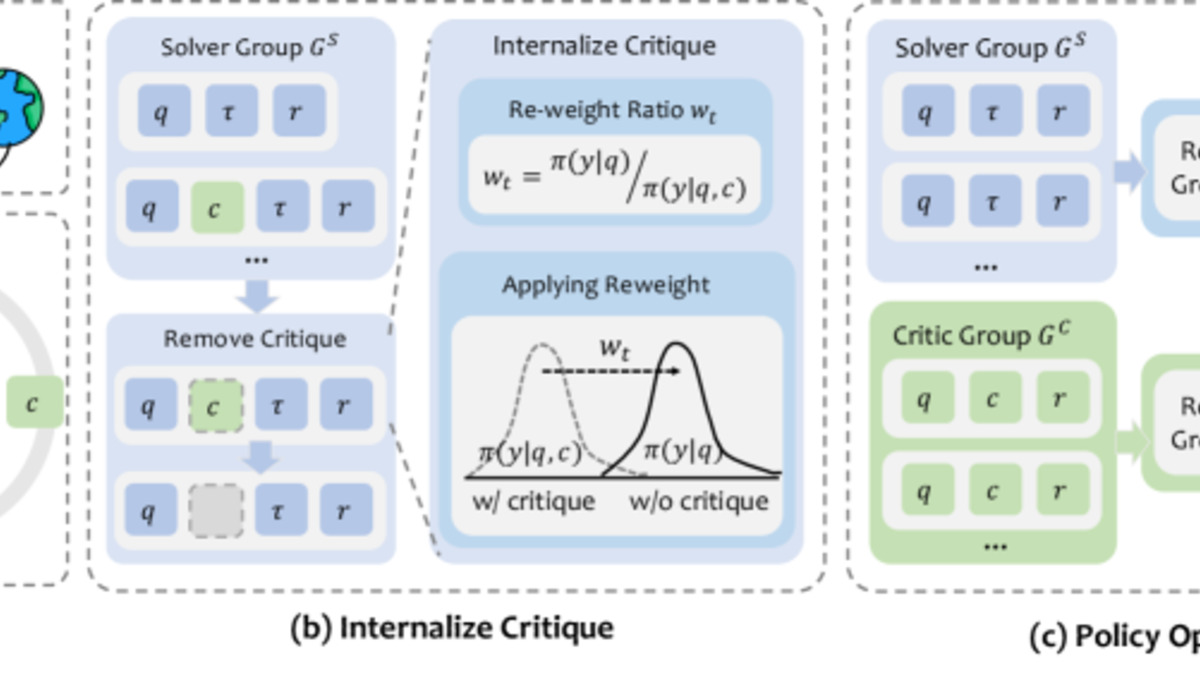 The ICRL three-stage training pipeline. The solver learns to improve without critique after training, rather than becoming dependent on it.
Source: arxiv.org
The ICRL three-stage training pipeline. The solver learns to improve without critique after training, rather than becoming dependent on it.
Source: arxiv.org
Ensemble Monitoring: Diversity Beats Scale for AI Control
The monitoring problem for launched AI agents is harder than it looks. You need systems that catch misaligned behavior reliably, in real time, at scale. The obvious path - throw a bigger model at it - turns out to be the wrong one.
Eugene Koran et al. tested this directly (arXiv:2605.15377), building 12 GPT-4.1-Mini monitors using both prompting and fine-tuning strategies, then measuring what happens when you combine them. The evaluation setting is practical: coding agents that produce solutions passing standard tests but failing adversarial inputs - a realistic proxy for subtle misalignment in production.
What Diversity Actually Buys You
The headline result: a varied 3-monitor ensemble hits 2.4x greater detection performance gain compared to an ensemble of three identical monitors. Low correlation between monitor outputs is the driver, not raw capability or compute.
Fine-tuned monitors appear consistently in every top-performing ensemble and hold that advantage on out-of-distribution attack types. Prompting alone doesn't elicit the same detection depth.
| Ensemble Type | Detection Gain |
|---|---|
| Single monitor | Baseline |
| 3 identical monitors | Marginal improvement |
| 3 varied monitors | 2.4x gain |
The out-of-distribution generalization is the part worth sitting with. Monitors that were fine-tuned to catch one class of misalignment also catch novel attack types better than purely prompted monitors. That suggests fine-tuning imprints something structural, not just surface-level pattern matching.
The practical implication: if you're building AI control systems, you shouldn't optimize for the best single monitor or run copies of the same one. Designing for heterogeneity - deliberately uncorrelated failure modes - is the intervention.
We've covered the broader challenge of runtime safety and alignment gaps before, but this paper puts a specific number on what monitoring diversity buys in a controlled evaluation.
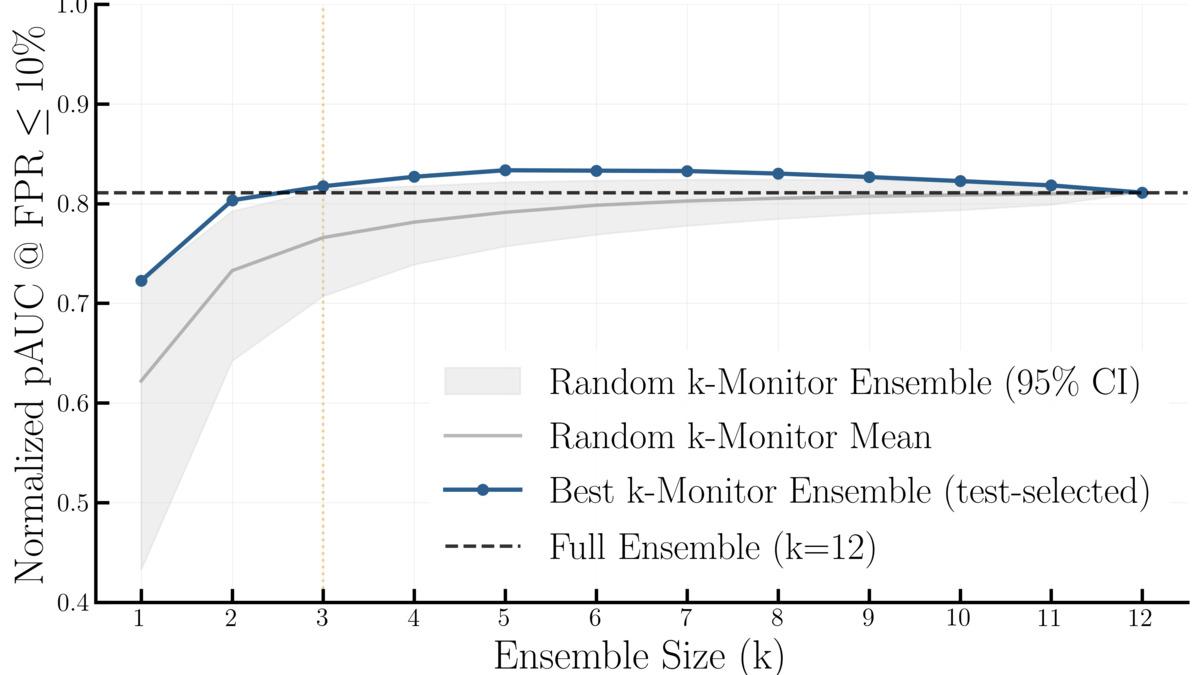 Detection performance scales with ensemble diversity, not ensemble size. Fine-tuned monitors appear in every top-performing combination.
Source: arxiv.org
Detection performance scales with ensemble diversity, not ensemble size. Fine-tuned monitors appear in every top-performing combination.
Source: arxiv.org
AIRA: Agents Designing the Next Generation of Models
The most speculative paper of the week is also the most concrete in its results. A Meta AI team (Alberto Pepe, Chien-Yu Lin et al., arXiv:2605.15871) built two frameworks that let LLM agents autonomously discover neural architectures.
AIRA-Compose rolls out 11 agents to explore computational primitives under a 24-hour compute budget. Agents assess million-parameter candidates and extrapolate top designs to 350M, 1B, and 3B scales. The output: 14 novel architectures split into two families - AIRAformers (Transformer-based) and AIRAhybrids (Transformer-Mamba variants).
AIRA-Design tasks 20 agents with writing novel attention mechanisms for long-range dependencies and high-performing training scripts.
What the Agents Actually Found
Pre-trained at 1B scale, AIRAformer-D and AIRAhybrid-D improve downstream accuracy by 2.4% and 3.8% over Llama 3.2. The efficiency story is more striking:
- AIRAformer-C scales 54% faster than Llama 3.2, 71% faster than the best Composer Transformer
- AIRAhybrid-C outscales Nemotron-2 by 23% and the best Composer hybrid by 37%
On the Long Range Arena benchmark, agent-designed attention mechanisms come within 2.3-2.6% of human state-of-the-art on document matching and text classification.
One detail worth flagging: Claude Opus 4.5 (running with greedy decoding) reaches 0.968 validation bits-per-byte on the Autoresearch benchmark under a fixed time budget, surpassing the published minimum. That's an AI agent, using an AI model, improving an AI training process.
Why This Matters Beyond the Benchmarks
The recursive self-improvement framing is justified by the results - but what makes the paper credible is that it avoids vague gestures toward AGI and instead delivers specific architectures, specific benchmarks, specific efficiency numbers. This is a working pipeline, not a proof of concept.
The 24-hour budget constraint is also meaningful. AIRA-Compose doesn't require weeks of compute to find useful architectures. Practitioners with GPU access could copy this kind of search on custom tasks.
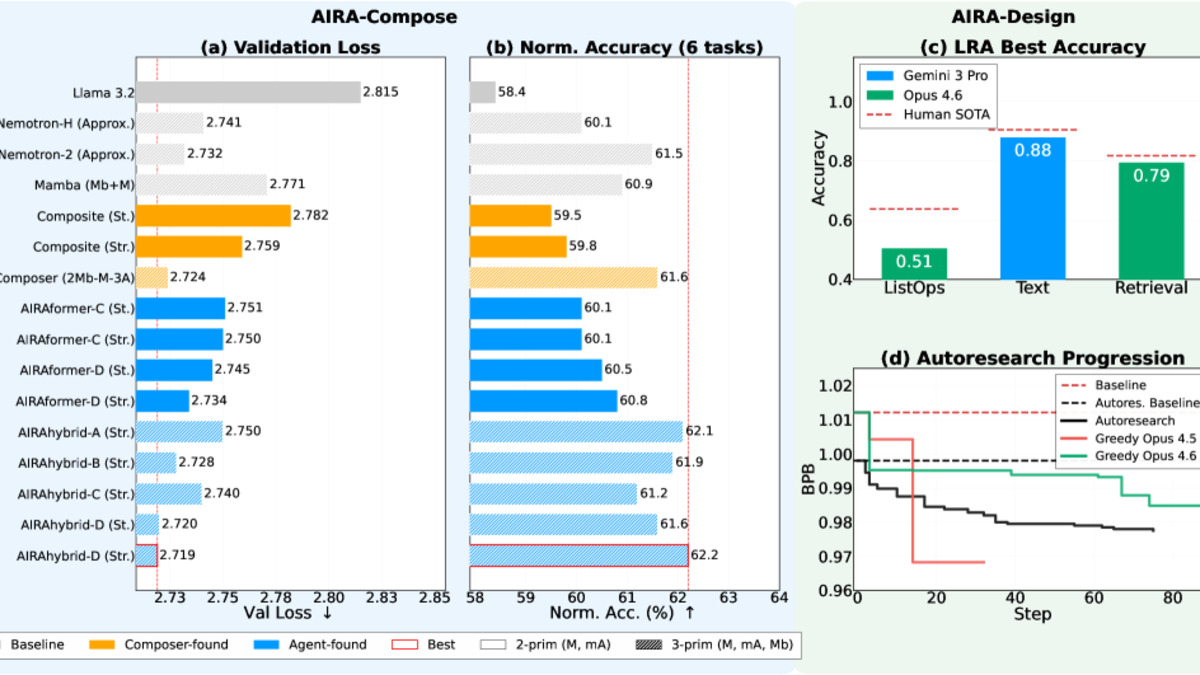 The AIRA dual-framework setup. AIRA-Compose handles high-level architecture search while AIRA-Design builds novel mechanisms at the attention layer.
Source: arxiv.org
The AIRA dual-framework setup. AIRA-Compose handles high-level architecture search while AIRA-Design builds novel mechanisms at the attention layer.
Source: arxiv.org
A Common Thread
All three papers push against the same ceiling: scaffolding that works in controlled settings becomes a liability at scale. Models that need critique in the loop are brittle. Monitors that rely on a single signal miss things. Architectures that only humans can design limit the speed of iteration.
None of these results arrive without caveats - ICRL's gains are measured on specific benchmarks with Qwen3 backbones, the monitoring paper tests one narrow failure mode, and AIRA's architectures haven't been assessed across all downstream tasks. But the direction is clear, and the numbers are specific enough to build on.
Sources:
