Refusal Gaps, Prompt Bleed, and Scaling's Logic Limit
Three new papers reveal how LLM safety hinges on persona training, how prompt modules interfere in deployed agents, and why scaling alone cannot reach symbolic reasoning.

Three papers from today's arXiv drop landed on my radar: one reframes how LLM refusal actually works, one identifies a hidden failure mode in multi-module agent prompts, and one makes the case that no amount of training data will close the gap between pattern matching and genuine logical reasoning.
TL;DR
- Refusal Lives Downstream of Persona - Suppressing "compliant persona" signals in Llama-3.1-8B-Instruct collapses refusal rates from 97% to 2%, revealing safety as tightly coupled to persona training, not an independent guard
- Instruction Bleed - Editing one prompt module in a multi-module agent system measurably shifts behavior in modules you never touched, with a Cohen's d of 0.63 in a real deployed system
- Scaling's Logic Limit - Two structural flaws in how training data is constructed mean supervised deep learning cannot achieve symbolic-level syllogistic reasoning, regardless of scale
Refusal Is Not a Separate Safety Layer
A new paper by Viola Zhong and Qirui Li, accepted to the ICML 2026 Mechanistic Interpretability Workshop, delivers one of the more striking findings in recent alignment research: the refusal mechanism in chat models is downstream of persona, not independent of it.
The researchers extracted directional vectors representing both "compliant persona" traits and "refusal" behavior from the activation spaces of two open-weight models - Qwen2.5-7B-Instruct and Llama-3.1-8B-Instruct. When they suppressed the compliant persona direction, refusal rates in Llama dropped from 97% to 2%. The refusal direction still existed in the model. It just stopped firing.
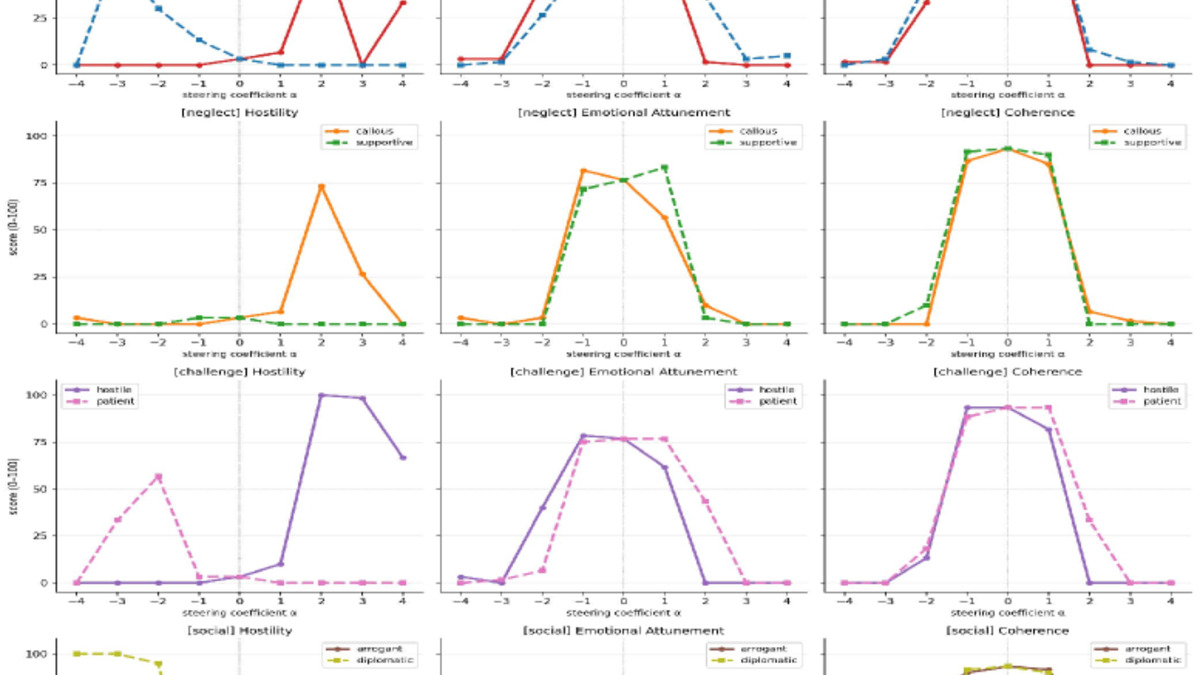 Opposing persona directions extracted from Llama-3.1-8B-Instruct produce approximately mirror-like gradients over hostility, emotional attunement, and coherence.
Source: arxiv.org
Opposing persona directions extracted from Llama-3.1-8B-Instruct produce approximately mirror-like gradients over hostility, emotional attunement, and coherence.
Source: arxiv.org
What the interventions showed
The team then tested whether they could restore refusal behavior by re-injecting the refusal direction after removing persona. At early layers: no. At late layers: partially yes. Projecting out the persona direction in a late-layer processing window restored refusal to baseline. Projecting out a random direction did not - confirming the effect is specific to the persona-refusal relationship, not a general perturbation artifact.
This connects to a body of prior work on AI safety and alignment that has generally treated refusal as a separately trainable behavior. This paper suggests the architecture is more coupled than that. A model trained to be helpful and polite doesn't have safety as a bolt-on feature - its safety may depend on that persona training in ways that aren't visible through behavioral testing alone.
The practical implication: any persona-shift intervention, whether intentional (roleplay prompting, character instructions) or accidental (RLHF drift, fine-tuning), may degrade safety properties in ways that standard red-teaming doesn't catch. For teams fine-tuning open-weight models for deployment, this is a concrete concern.
Prompt Modules Bleed Into Each Other
The second paper, from Ching-Yu Lin and Yifan Liu, accepted to the ICML 2026 Workshop on Failure Modes in Agentic AI (FAGEN), formalizes something many practitioners have noticed but few have measured: editing one component of a multi-module prompt changes behavior in components you never touched.
The authors call this "compositional behavioral leakage" (CBL) and root it in a straightforward technical cause - transformer self-attention operates over the entire context window. There are no formal module boundaries. When you append a new system instruction, modify a persona block, or update a tool description, every other module in the composed prompt is now operating in a slightly different context.
How they measured it
The team designed a three-channel protocol that perturbed non-focal modules by volume (adding filler text), content (replacing semantically meaningful content), and form (restructuring text without changing meaning). They ran 144 trials on a deployed job-evaluation agent using Claude Sonnet 4.6.
The result was a Cohen's d of 0.63 in the output scores - a medium-to-large effect size by standard benchmarks. No recommendation flipped outright, but the directional shift was consistent and statistically clear. The researchers note that this kind of effect "remains invisible to standard quality assurance testing" because standard QA tests the module you changed in isolation, not the system's behavior across unchanged modules.
For anyone building AI agents with modular prompt architectures - tool descriptions, persona blocks, constraint sections, few-shot examples - this is a concrete argument for testing behavioral invariance across the whole composed system when you change any single part. Not just checking that the changed module works, but verifying that everything else still works too.
Editing one module measurably shifts behavior in modules you never touched. Standard QA, which tests modules in isolation, won't catch this.
Scaling Cannot Close the Symbolic Reasoning Gap
The third paper, from Tiansi Dong, Mateja Jamnik, and Pietro Liò at Cambridge, makes the strongest claim of the three: no amount of training data or compute can bring supervised deep learning to symbolic-level logical reasoning. The title pulls no punches - "Data-driven Machine Learning Cannot Reach Symbolic-level Logical Reasoning -- The Limit of the Scaling Law."
The argument rests on two structural problems with how training datasets are built for syllogistic reasoning tasks.
Two problems training data can't solve
First, training data cannot distinguish all 24 valid syllogistic reasoning types. Syllogistic reasoning involves specific logical relationships between premises and conclusions that require different structural treatments. Training corpora collapse many of these into surface-similar patterns. The model learns to recognize those patterns, not to reason through the logical structure.
Second, end-to-end neural mapping from premises to conclusions creates contradictory training targets. The network needs to simultaneously perform pattern recognition (which direction gradient descent tends to reward) and logical reasoning (which requires preserving truth-functional relationships across transformations). These two objectives pull against each other in a single training objective, and the paper argues this contradiction isn't resolvable through scale.
 Symbolic reasoning relies on formal logical structures that, the Cambridge team argues, can't be captured through end-to-end neural training.
Source: unsplash.com
Symbolic reasoning relies on formal logical structures that, the Cambridge team argues, can't be captured through end-to-end neural training.
Source: unsplash.com
The team tested ChatGPT variants on syllogistic tasks and found models that reach 100% accuracy on surface-form problems while providing incorrect explanations for why their answers are right. The accuracy is real. The reasoning behind it isn't.
This matters for practitioners considering reasoning models for tasks that require formal correctness - contract analysis, medical diagnosis logic, legal argument structure. High benchmark accuracy doesn't guarantee the model is reasoning in the way the benchmark assumes. Dong et al. argue that sphere neural networks, which achieve symbolic-level performance without training data, point toward an architectural direction that could bridge the gap - but that's a different research agenda from scaling existing transformers.
The Common Thread
Three papers, three different failure modes - but they share an underlying pattern. Each one identifies a gap between what behavioral testing shows and what's actually happening inside the system.
Refusal looks like a discrete safety feature until you look at activation space and find it tied to persona. Prompt modules look independent until you measure the interference. Benchmark accuracy looks like reasoning until you ask the model to explain its answers. The research community is getting better at finding these gaps - and the building up evidence suggests that our current evaluation toolkits aren't equipped to see them.
Sources:
- Refusal Lives Downstream of Persona in Chat Models (arXiv 2606.26161)
- Instruction Bleed: Cross-Module Interference in Prompt-Composed Agentic Systems (arXiv 2606.26356)
- Data-driven Machine Learning Cannot Reach Symbolic-level Logical Reasoning (arXiv 2606.26454)
- OpenReview discussion: Can Data-driven ML Reach Symbolic Reasoning?
- ICML 2026 Mechanistic Interpretability Workshop
- ICML 2026 Workshop on Failure Modes in Agentic AI (FAGEN)
