Reasoning Bias, Behavior Cues, and Tool Interpretability
New research shows reasoning length amplifies position bias, behavior cues cut wasted tokens by 50% while boosting safety, and sparse autoencoders can predict tool failures from model internals.

Three papers from this week's arXiv catch my eye for the same reason: they all dig into things that deployed AI systems do in ways their builders didn't fully anticipate. One maps how reasoning models grow methodically biased as they think longer. Another trains models to signal their own intent before acting, cutting wasted compute in half. The third reads activations to predict tool-call failures before they happen.
TL;DR
- More Thinking, More Bias - Reasoning length positively correlates with position bias in 12 of 13 tested configurations, breaking assumptions about chain-of-thought robustness on multiple-choice tasks
- Behavior Cue Reasoning - Models trained to emit special tokens before specific behaviors jump from 46% to 96% task success while pruning 50% of wasted reasoning tokens
- Beyond the Black Box - Sparse autoencoders applied to GPT-OSS 20B and Gemma 3 27B can predict tool-use necessity and failure from internal states before any action is taken
More Thinking, More Bias
arXiv:2605.06672 | Xiao Wang
The intuition behind chain-of-thought reasoning is that more deliberation reduces errors. Wang's paper complicates that story by showing that extended reasoning chains don't remove position bias in multiple-choice questions - they replace one kind of bias with a different kind that scales with how long the model thinks.
Position bias is the tendency of a model to favor answers in particular positions on the page regardless of content. It's been documented in standard LLMs for years. The assumption was that reasoning models, which work through a problem before committing to an answer, would neutralize it. They don't.
Across 13 reasoning configurations - DeepSeek-R1 at 671B, R1-distilled 7-8B variants, and base models prompted with chain-of-thought - 12 showed positive partial correlations between path length and Position Bias Score (PBS). Values ranged from 0.11 to 0.41, all statistically significant (p < 0.05). MMLU, ARC-Challenge, and GPQA were the test beds.
How the bias accumulates
The causal case comes from truncation experiments. Wang resumed reasoning from later points in the trajectory and measured what happened: models shifted toward their position-preferred option at 16-32% higher rates than when starting fresh. The implication is that the model doesn't stabilize its position preference at the start. It drifts toward it as reasoning continues.
Scale softens the effect without eliminating it. At 671B parameters, the aggregate PBS falls to a modest 0.019. But in the longest reasoning quartile for the same model, PBS climbs back to 0.071. The bias isn't gone - it's deferred to the tail of long generations.
More reasoning isn't a free pass on answer ordering. At scale, the effect shrinks. In the longest generations, it comes back.
What to do about it
If your pipeline uses reasoning models for evaluation, classification, or any scored task with discrete answer sets, option order is now a variable you need to control. Randomizing answer positions across runs, using blind evaluation setups, and treating PBS as a first-class metric in your eval harness aren't optional anymore. The paper ships diagnostic tools for auditing this bias - worth integrating before running reasoning models at production scale.
The deeper issue is that chain-of-thought reasoning and direct-answer bias are distinct phenomena with different causal footprints. Fixing one doesn't fix the other.
Behavior Cue Reasoning
arXiv:2605.07021 | Christopher Z. Cui, Taylor W. Killian, Prithviraj Ammanabrolu
The core idea: train a model to announce what it's about to do, in text, before it does it. Cui, Killian, and Ammanabrolu call these announcements Behavior Cues - special token sequences emitted immediately before specific behaviors in the reasoning chain. External monitors read the cues and decide whether to let the behavior proceed, redirect it, or flag it.
The results are unusually clean. In constrained environments, the approach recovered safe actions from 80% of reasoning traces that would otherwise have produced unsafe outputs. Success rate went from 46% to 96%. In math problem solving, monitors that operated exclusively on Behavior Cue signals pruned up to 50% of otherwise wasted reasoning tokens.
Why this is different from activation probing
The obvious comparison is mechanistic interpretability work that reads internal model states to predict behavior. Behavior Cues operate in the text stream, not in activations. That's a practical difference: text-stream signals are easier to monitor at inference time, work without specialized tooling, and don't require access to model weights. You can build a rule-based monitor on top of them with minimal infrastructure.
The team assessed both rule-based and RL-trained monitors. RL-trained monitors generalized better across task variations. The approach was tested across two model families and three domains, suggesting the gains aren't narrow to a single benchmark.
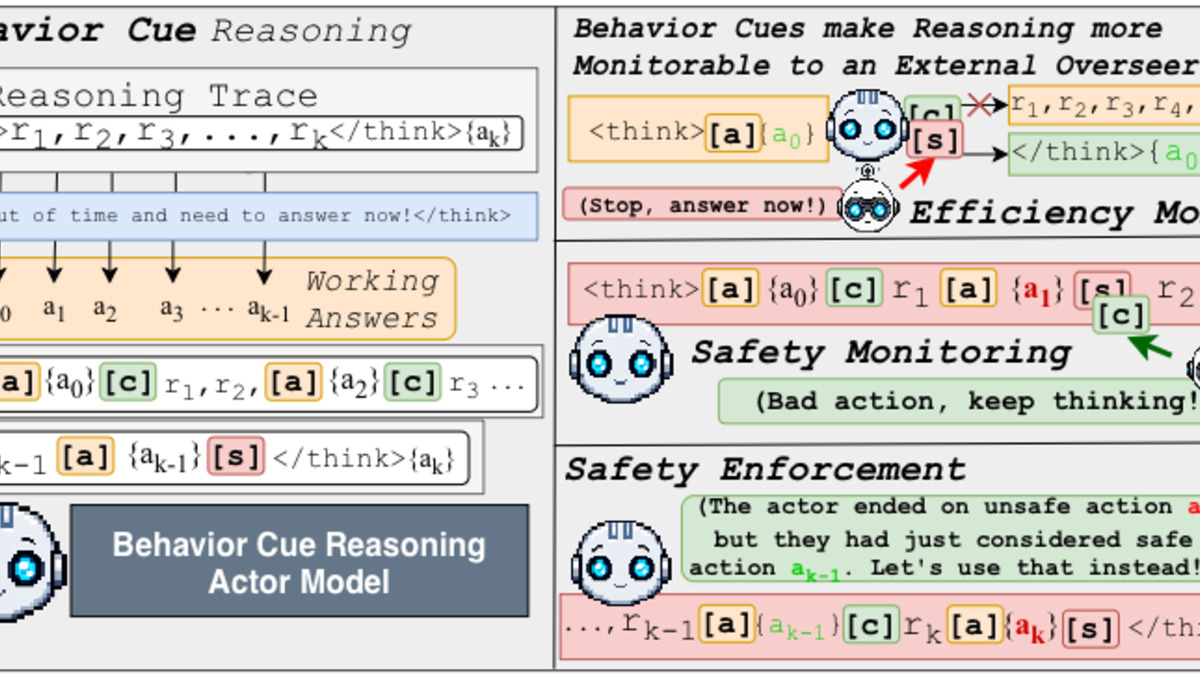 Behavior Cues appear as special tokens immediately before the model takes a specific action, allowing monitors to intercept before commitment.
Source: arxiv.org
Behavior Cues appear as special tokens immediately before the model takes a specific action, allowing monitors to intercept before commitment.
Source: arxiv.org
The cost calculation
This is rare in AI safety work: the safety improvement comes with an efficiency gain. Pruning 50% of wasted reasoning tokens means the safe version costs less to run than the unsafe one. Usually safety and compute trade off against each other. Not here.
The reason, the authors argue, is that the monitored model is modified to "reason more tractably to oversight." Behavior Cues aren't bolted on top of unchanged reasoning - they're part of how the model reasons. That structural difference is what allows monitoring to cut rather than add tokens.
For teams building agentic systems that need human-in-the-loop or automated oversight, this is a concrete architectural choice worth piloting. The training overhead is real, but the deployment arithmetic works in your favor.
Beyond the Black Box - Reading Model State Before Tool Calls
arXiv:2605.06890 | Hariom Tatsat, Ariye Shater
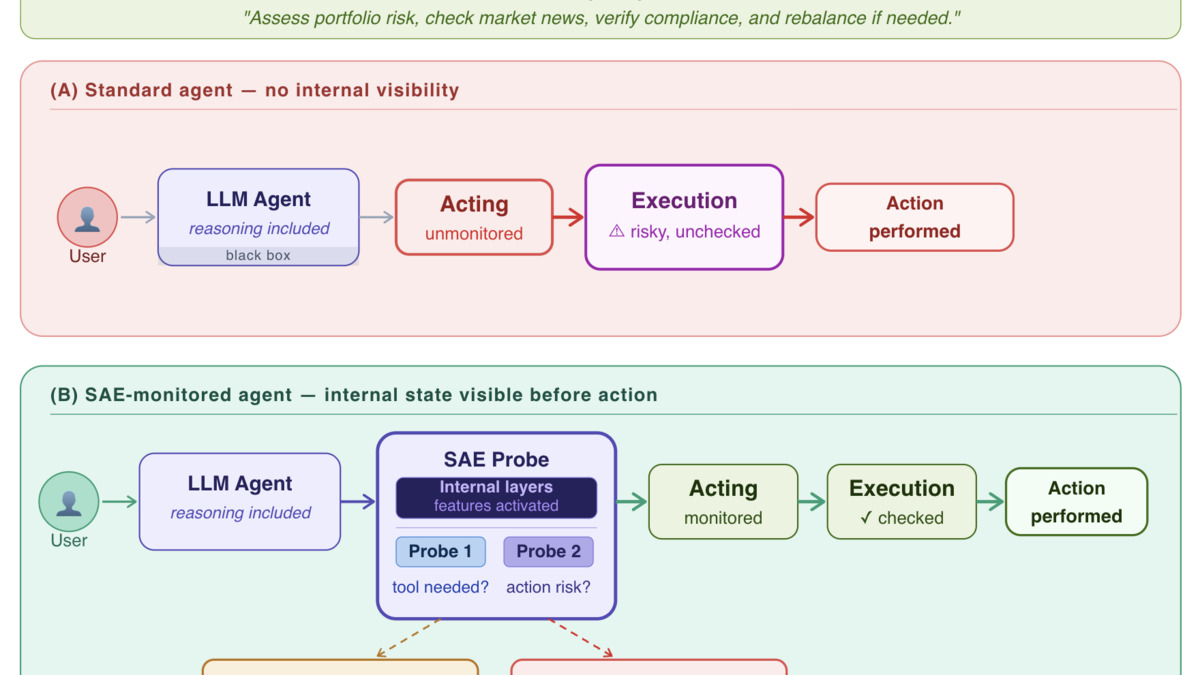
Tool-use failures in long-horizon tasks compound. By the time a wrong tool call is visible in the output, the agent has already spent tokens on downstream steps that assumed the wrong tool was called correctly. Tatsat and Shater went after this with mechanistic interpretability, asking whether internal model states before a tool call carry enough signal to predict whether the call will be necessary or will fail.
The framework uses sparse autoencoders (SAEs) and linear probes trained on multi-step trajectories from the NVIDIA Nemotron function-calling dataset. Applied to GPT-OSS 20B and Gemma 3 27B, the probes can predict - before the tool call is issued - whether tool use is actually required for the current step and what consequence the planned action is likely to produce.
What sparse autoencoders add
SAEs decompose activations into interpretable features. The key property is sparsity: most features are inactive for any given input, so the ones that do activate tend to carry specific meaning. The team identifies features associated with tool decisions at particular layers and tests their functional importance through ablation - removing the features changes tool selection behavior, not just output text.
The distinction matters because it demonstrates the features aren't just correlates. They're causally involved in how the model decides to call tools.
 Sparse autoencoder features active at tool-decision layers - each feature carries specific meaning about what the model is about to do.
Source: arxiv.org
Sparse autoencoder features active at tool-decision layers - each feature carries specific meaning about what the model is about to do.
Source: arxiv.org
This extends work we've seen on tool-use costs in agents - where we covered how noisy prompts increase tool call overhead - by adding a predictive layer before the overhead happens.
Practical deployment angle
Tatsat and Shater frame this as an observability layer, not a replacement for behavioral testing. You add internal state monitoring to catch root causes before they propagate. The paper provides visibility into what the model is signaling internally - the kind of information that's otherwise invisible until you're debugging a failed 50-step agent trajectory.
Enterprise deployments where agent actions have real-world consequences - sending emails, running queries, calling APIs - are the obvious target. For those use cases, catching a bad tool decision at step 3 before it corrupts steps 4 through 25 is worth the integration cost of adding a probe layer.
A Common Thread
All three papers, in different ways, are working on the same problem: AI systems do things that aren't fully visible to their operators. Reasoning models hide a position drift behind extended outputs. Agents commit to unsafe actions without signaling intent. Tool calls go wrong in ways that don't surface until damage is done.
The methodological approaches differ - statistical bias measurement, in-context special tokens, mechanistic feature analysis - but they converge on the same engineering prescription. Build systems where intent and failure modes are legible before they manifest. The work is still narrow and lab-scale, but the direction is increasingly practical.
Sources:
