Quantization's Hidden Tax, Cliff Tokens, Smarter Memory
Three new arXiv papers reveal hidden costs in quantized reasoning models, single-token failure triggers, and a new framework that cuts agent memory errors by up to 79%.

Three papers landed on arXiv today that share a common concern: the metrics teams use to judge AI systems in production often hide the real costs. One reveals that quantizing a reasoning model can inflate its token output by enough to wipe out the expected speed gains. Another identifies specific single tokens where mathematical reasoning falls apart. The third shows that agent memory systems silently corrupt themselves, and offers a way to stop it.
TL;DR
- Quantization Inflates Reasoning - INT4/INT3 quantization preserves accuracy but causes reasoning models to produce longer chains of thought, erasing the compute savings you expected
- Cliff Tokens - Single tokens at critical positions trigger complete reasoning failures; removing the first cliff token recovers perfect pass@64 performance, and targeting them with DPO boosts accuracy by up to 6.6 percentage points
- TRUSTMEM - A new memory consolidation framework using preference-guided RL cuts agent omission errors by 40%, corruption errors by 79%, and hallucination errors by 50%
Quantization Inflates Reasoning
Paper: "Quantization Inflates Reasoning: Token Inflation as a Hidden Cost of Low-Bit Reasoning Models" - Xinyu Lian et al.
The standard pitch for INT4 or INT3 quantization is straightforward: compress the weights, keep accuracy, serve more requests per second. A new paper from a team including researchers from Microsoft and the University of Illinois Urbana-Champaign finds a flaw in that pitch.
Quantized reasoning models generate longer chains of thought. The accuracy numbers stay roughly intact, but the models take more intermediate steps to get there, and they repeat themselves more. The paper introduces a metric called the CoT Token Inflation Ratio (CTIR) to measure how much longer reasoning traces grow after quantization. On the AIME25 benchmark, GPTQ-quantized Qwen3-4B shows measurable inflation even when accuracy is maintained.
The inflation isn't random. Quantized models exhibit more intermediate steps and greater semantic repetition - the reasoning traces circle back over ground already covered. In production, where you're paying per token or waiting for a response, this matters.
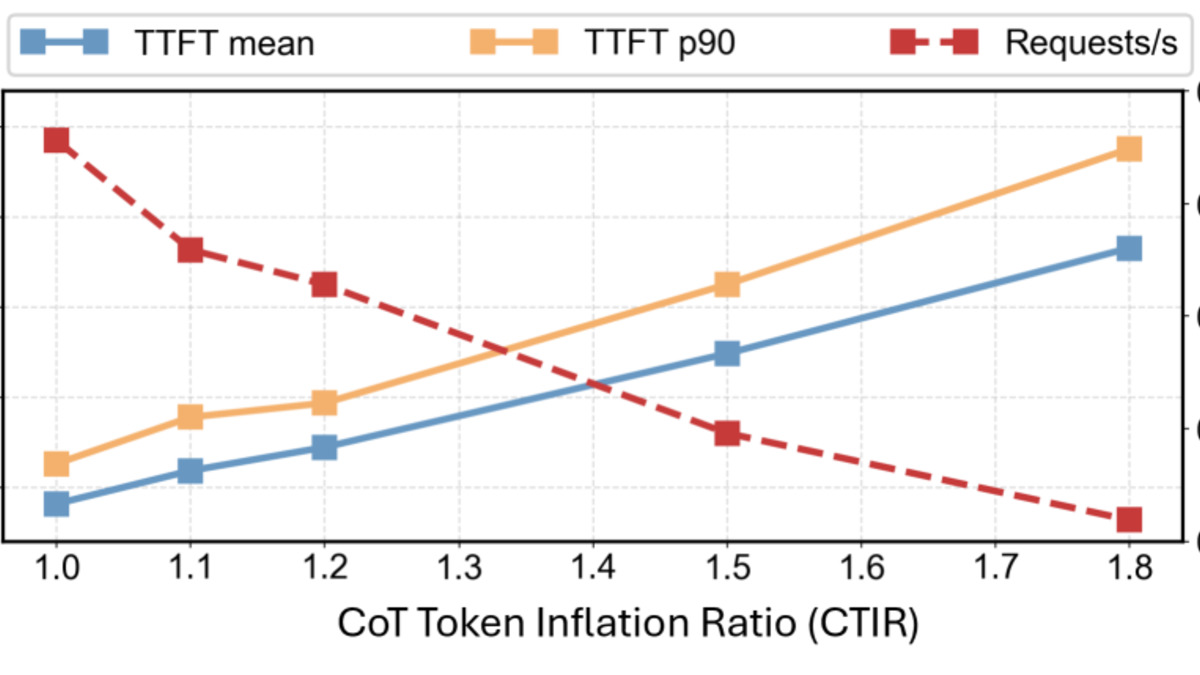 Figure 3 from the paper: Impact of CoT length inflation on serving efficiency. Quantized models recover much of the accuracy but generate substantially more tokens per correct answer.
Source: arxiv.org
Figure 3 from the paper: Impact of CoT length inflation on serving efficiency. Quantized models recover much of the accuracy but generate substantially more tokens per correct answer.
Source: arxiv.org
The team tested mitigation strategies including prompting interventions, decoding-time sampling changes, and quantization-aware training (QAT). Of these, QAT showed the most consistent results - reducing both accuracy degradation and token inflation simultaneously. Prompting and sampling changes helped somewhat but didn't fully close the gap.
For anyone running quantized reasoning models in production, the practical takeaway is direct: accuracy benchmarks aren't enough. You need to measure token output length on your actual workload. The speedup you modeled during capacity planning may not appear if your queries involve complex reasoning.
This connects to a broader question about what reasoning models actually do differently - their extended thinking process is a feature that quantization disrupts in ways the loss function doesn't capture.
Cliff Tokens
Paper: "Cliff Tokens: Identifying Single-Token Failure Triggers in LLM Mathematical Reasoning" - Jaeyong Ko, Pilsung Kang, Yukyung Lee
A model solves the same math problem correctly nine times, then fails on the tenth with identical input and a slightly different sampling path. The failure doesn't look like a slow degradation - it's abrupt, as if the model stepped off a ledge. Researchers at Korea University found that this is exactly what happens, and that a specific token is usually responsible.
The paper defines a cliff token as a token position where the model's probability mass shifts sharply toward failure. Depending on how that shift happens, cliff tokens fall into three categories:
- Deterministic cliffs: the model picks the wrong token consistently under greedy decoding
- Uncertain cliffs: high-entropy positions where the outcome is unpredictable across samples
- Sampled-off cliffs: positions where the bad token is only occasionally selected
The team developed an adaptive threshold detection method based on measuring "potential" at each token position. They verified the approach across seven models and three benchmarks: GSM1K, MATH500, and AIME 2025.
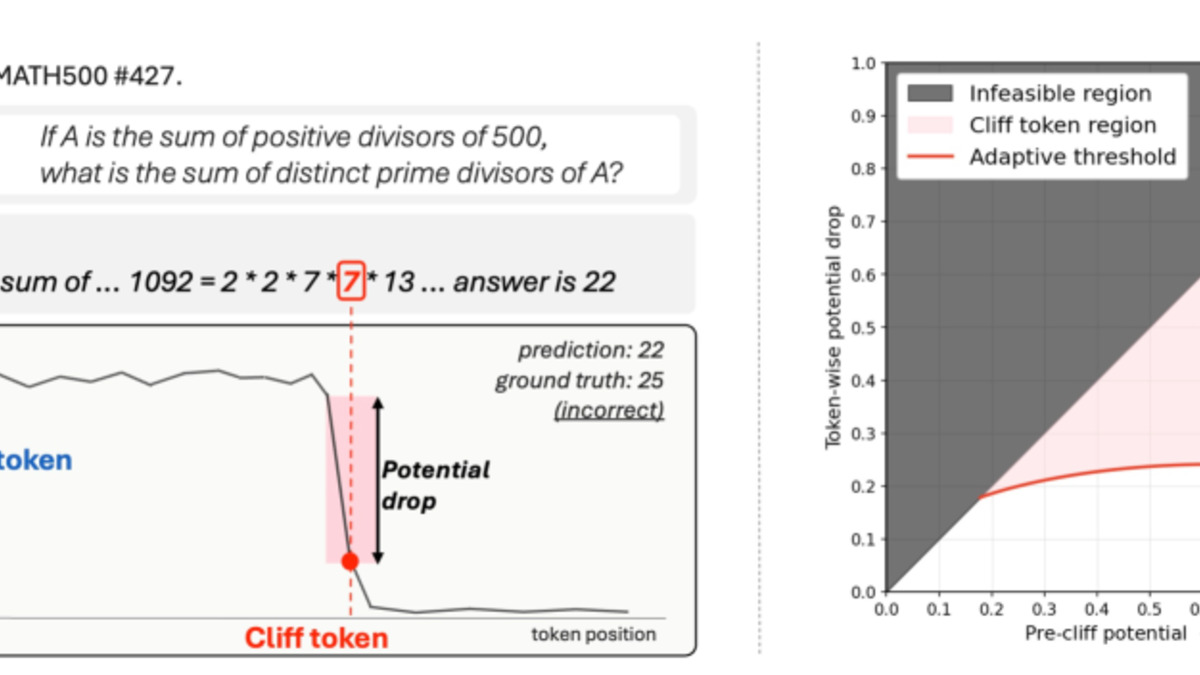 Figure 1 from the paper: Cliff token identification in reasoning trajectories. The sharp probability shift at the cliff position is visible in both deterministic and uncertain variants.
Source: arxiv.org
Figure 1 from the paper: Cliff token identification in reasoning trajectories. The sharp probability shift at the cliff position is visible in both deterministic and uncertain variants.
Source: arxiv.org
The deletion experiment is striking. When the researchers removed just the first cliff token from a reasoning trace, pass@64 performance recovered to 1.0 on the tested problems. Leaving it in place capped recovery at 0.71 to 1.0 depending on the problem. One token makes or breaks the solution.
They also trained a model using Cliff-DPO - Direct Preference Optimization applied specifically to cliff token positions - and measured a 6.6 percentage point accuracy improvement across benchmarks when training on GSM8K. Targeting uncertain and sampled-off cliffs drove the gains; deterministic cliffs showed no improvement from DPO, which makes sense since the model already commits to the wrong path regardless of preference signal.
For anyone fine-tuning reasoning models, this suggests that standard DPO datasets may be leaving accuracy on the table by not weighting cliff positions specifically. The paper gives a principled way to identify and prioritize those positions.
TRUSTMEM: Stopping Memory Corruption Before It Spreads
Paper: "TRUSTMEM: Learning Trustworthy Memory Consolidation for LLM Agents with Long-Term Memory" - Tianyu Yang et al.
Long-term memory is one of the things that makes AI agents genuinely useful over multiple sessions. It's also where a lot of silent failures happen. When an agent updates its memory incorrectly - dropping a key detail, overwriting a fact with a wrong one, or hallucinating a connection that wasn't there - the error persists. Every following action that draws on that memory inherits the corruption.
The TRUSTMEM paper from a team that includes researchers from Walmart Global Tech and Virginia Tech frames this as a verification problem. Current memory consolidation systems optimize for coverage and fluency; they don't explicitly check whether updates are trustworthy. The result is that agents gradually build up errors that standard evaluations don't catch until something visibly breaks.
The proposed framework adds a Memory Transition Verifier that assesses each candidate memory update across three dimensions:
| Dimension | What it checks |
|---|---|
| Coverage | Does the update retain necessary information? |
| Preservation | Does it avoid overwriting or corrupting existing facts? |
| Faithfulness | Does it introduce any unsupported content? |
The verifier creates preference rankings across candidate updates, which feed into a preference-guided reinforcement learning step that trains the agent to produce better consolidations over time. It's not a filter applied at inference - it shapes the model's consolidation behavior through training.
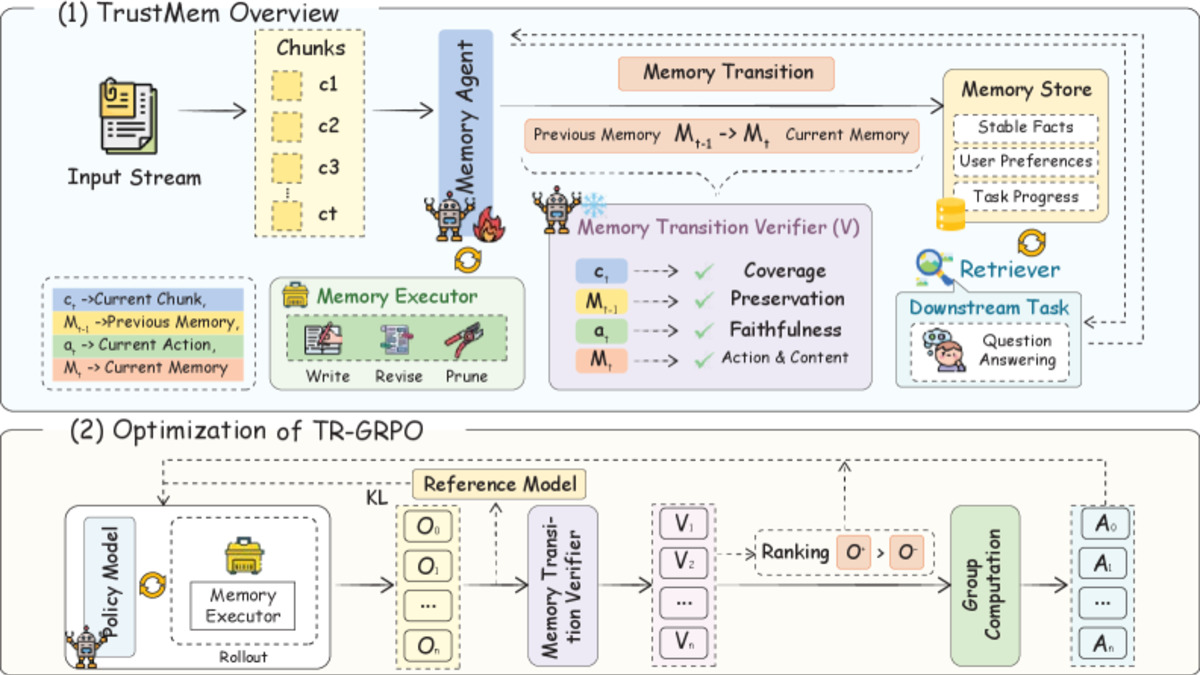 Figure 3 from the paper: The TrustMem framework overview. The Memory Transition Verifier assesses candidate updates before the RL step adjusts consolidation behavior.
Source: arxiv.org
Figure 3 from the paper: The TrustMem framework overview. The Memory Transition Verifier assesses candidate updates before the RL step adjusts consolidation behavior.
Source: arxiv.org
The results are substantial. On the HaluMem benchmark for memory extraction:
- 12.14 F1 point improvement overall
- 40.1% reduction in omission errors
- 79.1% reduction in corruption errors
- 50.0% reduction in hallucination errors
Omissions are hard to detect because the agent doesn't know what it forgot. Corruptions are harder still because the agent confidently acts on wrong information. The 79% reduction in corruptions is the number that matters most for production systems.
This builds on a line of agent memory research that has been establishing why naive memory architectures fail at scale. TRUSTMEM gives practitioners a concrete training recipe rather than just a diagnostic.
The Thread Connecting All Three
What links quantization inflation, cliff tokens, and memory corruption is the gap between what evaluation metrics show and what happens in rolled out systems.
Accuracy alone doesn't tell you that your quantized model is burning twice the expected tokens. Pass rate alone doesn't reveal the single token positions where reasoning collapses. Memory correctness scores don't detect the slow accumulation of corrupted facts across sessions.
All three papers are pushing toward richer evaluation frameworks - ones that measure what production deployments actually care about. For teams shipping reasoning systems today, each paper offers a metric worth adding to your eval suite before the next deployment goes out.
Sources:
