AI Research: Orchestration Beats Scale, Small Models Win
Sakana Fugu tops SWE-Bench Pro by routing tasks across rival LLMs, Microsoft's 9B browser agent beats OpenAI Operator, and a 3B model from Weibo matches DeepSeek V3.2 on math.

Three papers this week each challenge a different assumption the AI industry treats as settled. One shows a trained coordinator outperforming the individual models it coordinates. Another shows a 9B browser agent beating proprietary frontier systems from OpenAI and Google. The third - the one with 356 upvotes on Hacker News - proves a 3B model can match systems 200 times its size on hard math, if you accept some constraints on what you ask it to do.
TL;DR
- Sakana Fugu - Orchestrator tops SWE-Bench Pro at 73.7%, beating Claude Opus 4.8 (69.2%) and GPT-5.5 (58.6%) by routing tasks across a pool of rival LLMs
- Microsoft Fara-1.5 - 9B browser agent hits 63.4% on Online-Mind2Web, above OpenAI Operator (58.3%) and Gemini 2.5 Computer Use (57.3%), trained on 2M synthetic samples
- VibeThinker-3B - 3B model from Weibo scores 94.3 on AIME 2026, matching DeepSeek V3.2 (671B) on math using curriculum RL at a training cost orders of magnitude lower
Sakana Fugu: The Orchestrator That Outranked Its Own Pool
Sakana AI, the Tokyo lab founded in 2023, released Fugu on June 22. The design is straightforward in principle: train a coordinator to decompose tasks and route sub-problems to whichever model in its pool handles each one best. The execution is more interesting.
The agent pool includes Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, and recursive Fugu instances. Conspicuously missing: Fable 5 and Mythos Preview, which both became unavailable outside the US following export restrictions that took effect June 12. Sakana built around this constraint rather than waiting for it to resolve.
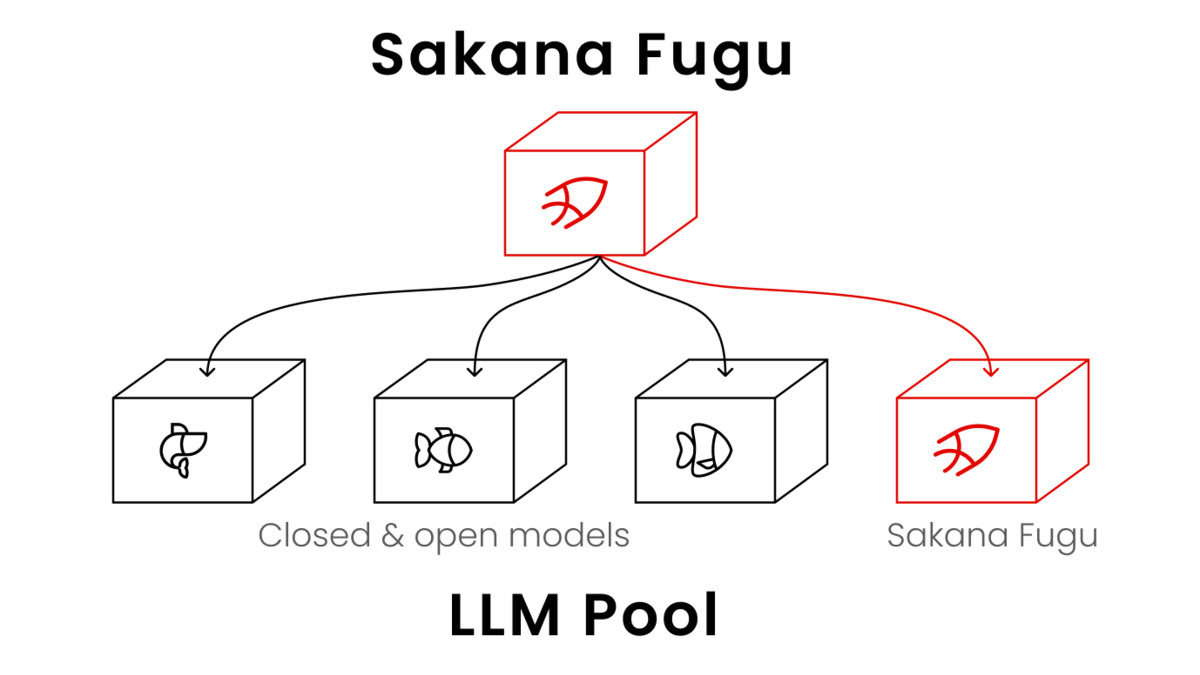 Fugu assigns Thinker, Worker, and Verifier roles dynamically per task, routing to the best available model in its pool.
Source: sakana.ai
Fugu assigns Thinker, Worker, and Verifier roles dynamically per task, routing to the best available model in its pool.
Source: sakana.ai
The technical foundation comes from two ICLR 2026 papers. Trinity formalizes how agents take on distinct Thinker, Worker, and Verifier roles. Conductor uses reinforcement learning to discover coordination strategies in natural language, so the system doesn't rely on hard-coded routing rules. The coordinator itself is estimated at around 7B parameters.
Benchmark Numbers
Fugu Ultra leads 10 of 11 published benchmarks. On SWE-Bench Pro it scores 73.7% against Opus 4.8's 69.2% and GPT-5.5's 58.6%. TerminalBench 2.1: 82.1% (GPT-5.5 at 78.2%). GPQA-Diamond: 95.5%. Humanity's Last Exam: 50.0%, compared to Opus 4.8's 49.8%.
These numbers make Fugu Ultra competitive with the most capable individual models on the market. What's technically remarkable isn't just the results - it's that a system coordinating Opus 4.8 can beat Opus 4.8 running alone.
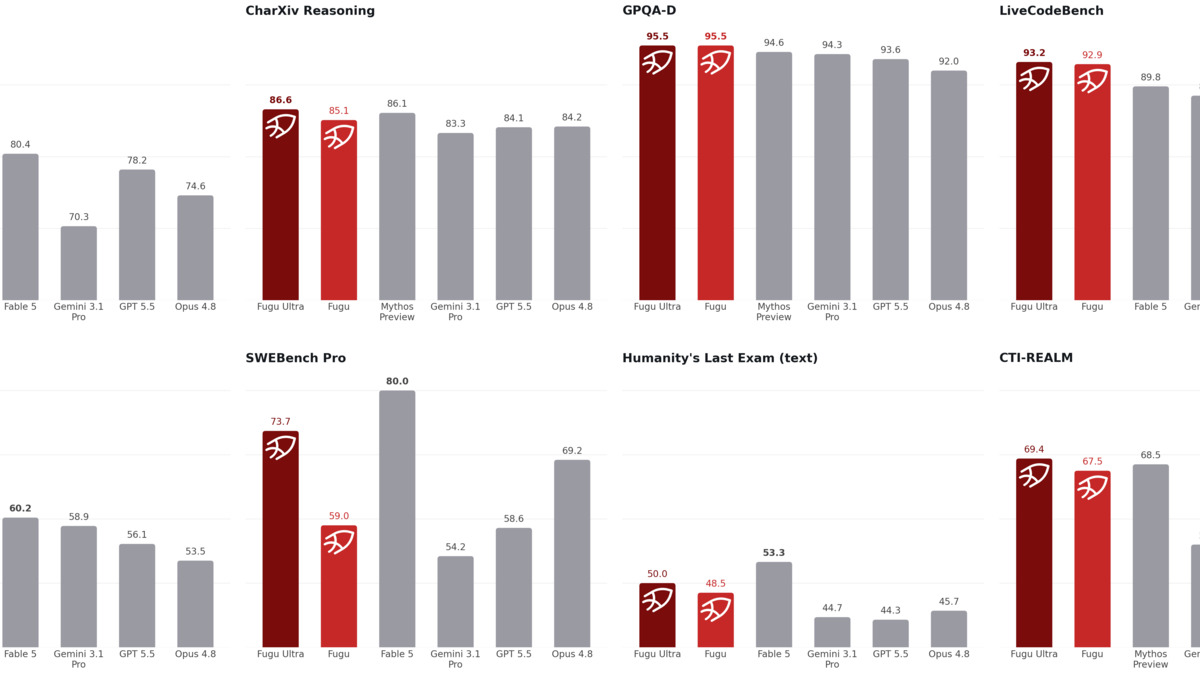 Fugu Ultra's benchmark performance across 11 evaluations, compared to Opus 4.8 and GPT-5.5.
Source: sakana.ai
Fugu Ultra's benchmark performance across 11 evaluations, compared to Opus 4.8 and GPT-5.5.
Source: sakana.ai
The caveat: within 24 hours of launch, independent testers flagged a gap between benchmark results and performance on arbitrary real-world tasks. That's not unusual for orchestration systems, which can optimize toward specific evaluation formats. Worth tracking as more third-party evals come in.
Fugu is available through an OpenAI-compatible API with subscription and pay-as-you-go tiers.
Microsoft Fara-1.5: Beating Operator Without Frontier Compute
Microsoft Research's Fara-1.5 - released in May, with the full technical report surfacing this week - is a family of three browser agents (4B, 9B, 27B) built on Qwen3.5 base models. The 27B variant scores 72.0% on Online-Mind2Web and 88.6% on WebVoyager. The 9B reaches 63.4% and 86.6% respectively.
To put those numbers in context: OpenAI Operator scores 58.3% on Mind2Web, Gemini 2.5 Computer Use 57.3%. Microsoft's mid-tier open-weight model beats both.
The FaraGen1.5 Pipeline
The training approach is what makes this worth studying. Microsoft built FaraGen1.5, a synthetic data pipeline with three modular components.
Environments include live websites and six sandboxed FaraEnvs - purpose-built simulators covering email, calendar, streaming, booking, ML model management, and scheduling. These cover login-gated and irreversible-action scenarios that public websites can't be used to train on.
Solvers use GPT-5.4 as a teacher agent, with a user simulator for multi-turn interactions. The solver itself achieves 83% on Mind2Web, producing clean trajectories for the students to learn from.
Verifiers apply three filters: task correctness, execution efficiency, and appropriate handling of critical interaction points (things like confirming before submitting a payment). This last one matters in deployment.
The resulting dataset runs to around 2 million samples, built up over 16 months. That's not something you can replicate in a weekend.
A detail worth noting: Fara1.5 agents are trained to stop and ask the user before irreversible actions. Most browser agents skip this. It makes the system safer for production workflows where reverting a form submission isn't possible.
Fara1.5-9B is live now on Azure AI Foundry via the MagenticLite interface. Inference code is MIT-licensed on GitHub. Check our Computer Use Leaderboard for how it stacks up across all benchmarks in the space.
VibeThinker-3B: Frontier Math at 3 Billion Parameters
The VibeThinker-3B paper from WeiboAI landed on June 16, but it's getting serious attention this week after hitting 356 points on Hacker News and trending on HuggingFace with over 41,000 downloads in a month.
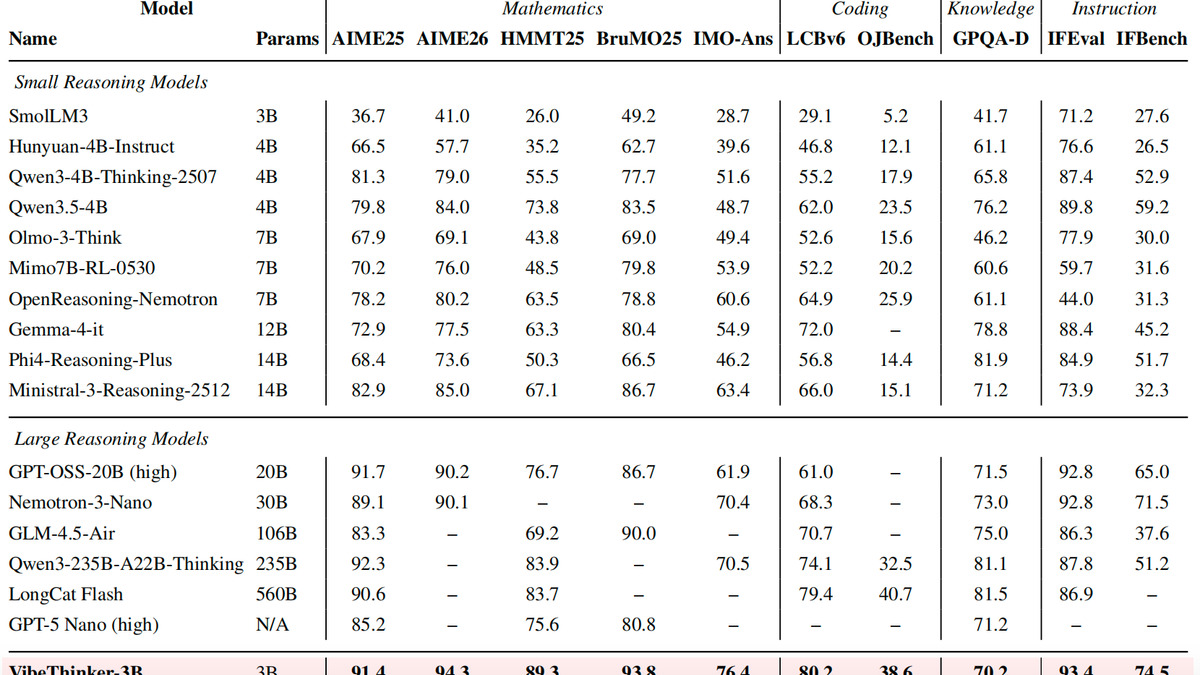
The claim: a 3B dense model achieves 94.3 on AIME 2026, the same score as DeepSeek V3.2, which has 671 billion parameters. With test-time scaling, it reaches 97.1. On IMO-AnswerBench (400 competition-level problems), it scores 76.4 - 80.6 with their Claim-Level Reliability Assessment strategy.
A 3B model matching a 671B system on competition math is exactly the kind of result that demands scrutiny.
The Training Approach
The team from Sina Weibo's AI research group calls their method "Spectrum-to-Signal" post-training. It runs in stages: curriculum-based supervised fine-tuning on diverse reasoning problems, multi-domain reinforcement learning with verifiable reward signals, and offline self-distillation. The base is Qwen2.5-Coder-3B. Training cost is estimated at a fraction of what large-scale pretraining or post-training of frontier models requires.
 VibeThinker-3B benchmark results on AIME, IMO-AnswerBench, and LiveCodeBench, compared to larger models.
Source: huggingface.co/WeiboAI
VibeThinker-3B benchmark results on AIME, IMO-AnswerBench, and LiveCodeBench, compared to larger models.
Source: huggingface.co/WeiboAI
What to Make of the Numbers
These results are self-reported. No independent lab has re-run the evaluations yet. The AIME and LeetCode benchmarks are narrow - they measure competition math and algorithmic coding, not general capability. The model's GPQA-Diamond score is 70.2%, which looks pedestrian next to 95.5% from Fugu Ultra. This is a specialized model that trades general knowledge for depth in verifiable domains.
That's not a criticism. It's actually the explicit thesis of the paper: they call it the "Parametric Compression-Coverage Hypothesis" - the idea that small models can reach frontier performance on constrained task classes if you accept coverage limits. LeetCode contests show this most clearly: 123 of 128 unseen problems solved correctly.
LiveCodeBench v6: 80.2 Pass@1. IFEval (instruction following): 93.4.
For anyone building math tutors, competitive programming assistants, or STEM reasoning pipelines, VibeThinker-3B runs locally, is MIT-licensed, and now has GGUF quantizations available on HuggingFace courtesy of the community.
A Common Thread
All three papers this week push back against the same orthodoxy: that frontier performance requires frontier compute. Sakana Fugu gets there via coordination. Fara-1.5 gets there via synthetic training data at scale. VibeThinker-3B gets there via specialization.
None of these approaches generalizes cleanly - Fugu costs more per query than a single model call, Fara-1.5 still requires Microsoft's cloud infrastructure for the best results, and VibeThinker-3B doesn't perform like a frontier model outside its target domains. But the convergence of three independent research teams arriving at similar conclusions in one week isn't coincidence.
Sources:
- Sakana Fugu Technical Report (arXiv:2606.21228)
- Sakana AI Fugu product page
- VentureBeat: Sakana achieves frontier performance with Fugu multi-model system
- Fara-1.5 arXiv technical report (arXiv:2606.20785)
- Microsoft Research: Fara1.5 article
- Microsoft Research blog: MagenticLite, MagenticBrain, Fara1.5
- VibeThinker-3B arXiv paper (arXiv:2606.16140)
- WeiboAI/VibeThinker-3B on HuggingFace
- VentureBeat: Why Weibo's VibeThinker-3B has the AI world arguing
