Agent Consensus, Uncertainty Anatomy, and ARC-AGI-3
Three papers from today's arXiv: why multi-agent consensus is often a lottery, how to decompose LLM uncertainty into three actionable components, and what ARC-AGI-3 reveals about frontier AI's limits.

Three papers landed today that, taken together, make a pretty sobering picture of where current AI actually stands. One asks whether your multi-agent system is reasoning or just getting lucky. Another breaks down LLM uncertainty into three distinct types so you can target the right fix. The third updates the scoreboard on ARC-AGI-3, where the best frontier systems clock in below one percent.
TL;DR
- Memetic Drift in Multi-Agent LLMs - Consensus in LLM populations is often driven by random sampling noise, not genuine collective intelligence, and small teams (N≤10) produce near-random outcomes
- The Anatomy of Uncertainty in LLMs - A new framework splits LLM uncertainty into input ambiguity, knowledge gaps, and decoding randomness - each requiring a different fix
- ARC-AGI-3 - Frontier AI scores below 1% on the new interactive benchmark; Gemini tops the leaderboard at 0.37% while humans hit 100%
When Multi-Agent Consensus Is Just a Lottery
Paper: "When Is Collective Intelligence a Lottery? Multi-Agent Scaling Laws for Memetic Drift in LLMs" | Hidenori Tanaka (Harvard University Center for Brain Science & NTT Research) | arXiv:2603.24676
There's an assumption baked into most multi-agent system designs: that getting several LLMs to deliberate and converge on an answer is better than asking one. Tanaka's paper from Harvard challenges that assumption with mathematical precision.
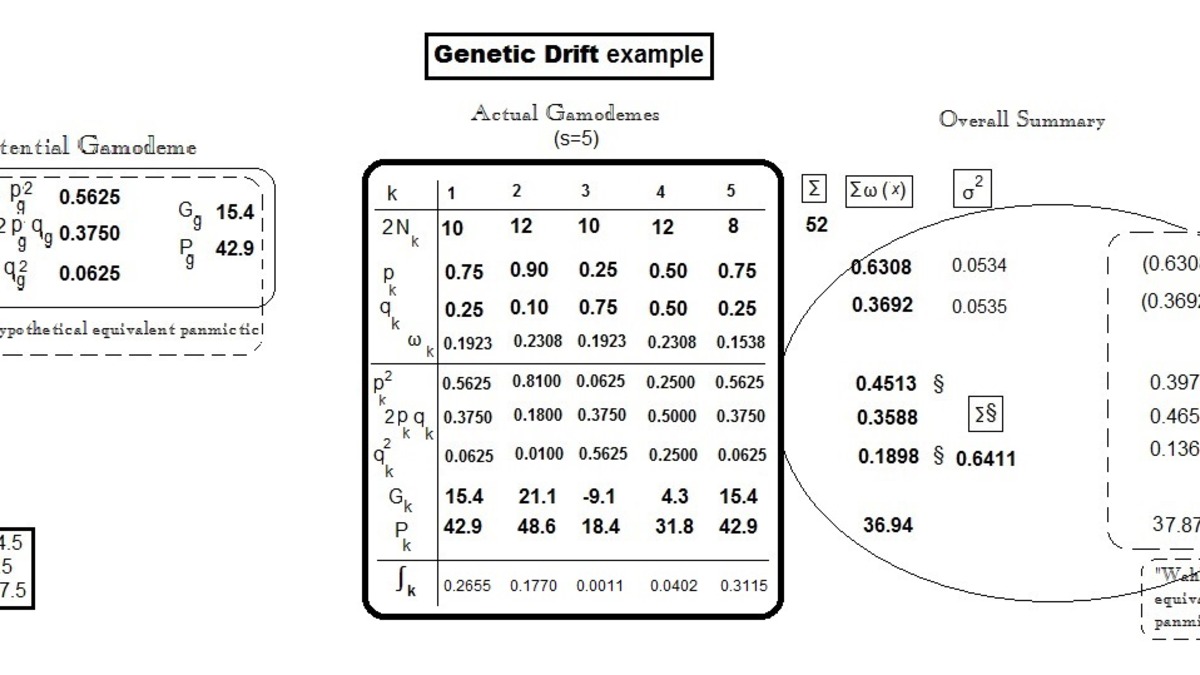
The core finding is uncomfortable. In LLM populations, consensus forms readily - but its origin is often sampling noise rather than shared reasoning. Tanaka calls this "memetic drift," borrowing the term from population genetics. When one agent produces an output, that output becomes part of the context for others. They update toward it. The process compounds. Before long, every agent in the population agrees on something that was originally an arbitrary choice by the first to speak.
The QSG Model
To study this analytically, Tanaka introduces the Quantized Simplex Gossip (QSG) model. It captures three features of real multi-agent systems: agents hold continuous internal belief distributions, they communicate via finite-bandwidth discrete messages, and they update their beliefs based on received messages at rate α. The gap between continuous internal beliefs and discrete outgoing messages is where sampling noise enters, and QSG isolates exactly how that noise spreads.
The math produces a crisp prediction. Early polarization grows at rate α²/N², meaning larger populations suppress drift. Consensus time scales as mN²/α², where m is the number of samples agents share per interaction. Increasing bandwidth (higher m) weakens drift proportionally - sharing more of your internal state reduces the amplification of noise.
 Genetic drift in biology: allele frequencies converge by chance in small populations, not because of fitness advantages. Tanaka shows the same dynamics apply to LLM populations converging on opinions.
Source: commons.wikimedia.org
Genetic drift in biology: allele frequencies converge by chance in small populations, not because of fitness advantages. Tanaka shows the same dynamics apply to LLM populations converging on opinions.
Source: commons.wikimedia.org
What It Means in Practice
Tanaka verifies QSG against real experiments using GPT-4o and Claude Haiku 4.5. Polarization trajectories match the model's predictions with a single fitted α across different population sizes. Consensus time grows roughly quadratically in N. The scaling laws hold.
Four takeaways that matter for builders:
- Small populations are especially vulnerable. At N≤10, inherent biases often lose to random drift - outcomes look roughly 50/50 regardless of which answer is actually better.
- Communication bandwidth is protective. Single-token exchanges amplify noise most severely. The more agents share of their internal reasoning, the less drift leads.
- Faster in-context learning can backfire. A higher adaptation rate α accelerates drift as fast as it accelerates genuine convergence toward correct answers.
- Consensus doesn't mean correct. The paper's central warning is worth quoting directly: "Agreement in an LLM population is not, on its own, evidence of collective reasoning or information aggregation; it can also be the consequence of amplified sampling noise."
For safety-critical applications, this matters beyond performance. Individually aligned agents don't compose cleanly into an aligned population. Harmful conventions can emerge from agent interaction even when every agent starts from a neutral position.
We've previously covered related multi-agent safety research on this site - Tanaka's work adds theoretical grounding to what that empirical work was showing in practice.
Three Types of Uncertainty, Three Different Fixes
Paper: "The Anatomy of Uncertainty in LLMs" | Aditya Taparia, Ransalu Senanayake, Kowshik Thopalli, Vivek Narayanaswamy | arXiv:2603.24967
Most approaches to LLM uncertainty treat it as a single quantity to measure. This paper argues that's the wrong frame. The researchers propose decomposing uncertainty into three distinct sources - and the distinction has real consequences for what you should actually do about it.
The three components are:
- Input ambiguity - the prompt itself is underspecified. The model is uncertain because any reasonable interpretation could be correct.
- Knowledge gaps - the model lacks the parametric knowledge needed to answer confidently. Training data didn't cover the relevant domain or the question is about something that postdates training.
- Decoding randomness - stochastic sampling introduces variance even when the model "knows" the answer. Same prompt, same model, different runs.
Why the Distinction Matters
Conflating these three leads to wrong interventions. If a model fails because of input ambiguity, the fix is better prompting or asking for clarification - not more training data. If failures come from knowledge gaps, retrieval augmentation helps; if from decoding randomness, lowering temperature or using greedy decoding addresses it more directly.
The paper shows that the relative dominance of these components shifts depending on model scale and task type. Larger models tend to have less uncertainty from knowledge gaps (they've seen more) but decoding randomness remains a consistent factor regardless of scale. Input ambiguity is task-specific - highly constrained tasks generate less of it.
Three sources of uncertainty, three different fixes. Prompt engineering, retrieval augmentation, and sampling temperature each target a different problem. Treating uncertainty as one undifferentiated thing means you're probably fixing the wrong one.
The practical implication is straightforward. If you're trying to reduce hallucination rates, running experiments that don't disaggregate uncertainty type will produce noisy results. A reduction that appears to help might be suppressing decoding randomness while leaving knowledge gaps intact - or vice versa. The framework gives practitioners a vocabulary and a diagnostic lens that was previously missing from the standard uncertainty quantification toolbox.
For teams building AI agents that need reliable reasoning, this decomposition is directly relevant: agents often fail in all three modes at once, and understanding which is dominant in a given context shapes the architecture choices worth making.
ARC-AGI-3: Frontier AI Still Can't Learn Like a Human
Paper: "ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence" | ARC Prize Foundation (François Chollet) | arXiv:2603.24621
Chollet's ARC-AGI benchmarks have never been designed to be flattering to current AI. ARC-AGI-3 continues that tradition, and the numbers are stark.
The benchmark is structurally different from anything the field has tried before. Instead of static input-output problems, ARC-AGI-3 presents interactive, turn-based environments. An agent enters with no instructions, no rules, no stated goals. It has to explore, figure out how the environment works, infer what "winning" looks like, and carry those learned rules forward across increasingly difficult levels. Humans achieve 100% on this task. Gemini currently scores 0.37%.
 The ARC-AGI-3 benchmark challenges agents to infer goals and rules from scratch across interactive environments - a task that humans find natural but frontier AI systems fail on almost completely.
Source: arcprize.org
The ARC-AGI-3 benchmark challenges agents to infer goals and rules from scratch across interactive environments - a task that humans find natural but frontier AI systems fail on almost completely.
Source: arcprize.org
What Makes This Hard
The benchmark aims to be unlearnable through memorization. Environments use only what Chollet calls "core knowledge" - basic spatial reasoning, color recognition, and pattern inference that humans develop in early childhood. There are hundreds of handcrafted environments, each novel. A system that has seen every previous ARC task can't use that to solve ARC-AGI-3.
Scoring is also different. Rather than binary pass/fail, ARC-AGI-3 measures action efficiency - how efficiently the agent reaches the goal compared to how a human player does it. This formally captures learning efficiency, not just capability.
The paper frames this as testing "fluid adaptive efficiency on novel tasks" - the ability to pick up truly new skills rather than pattern-match against training distribution.
The Gap in Context
For context on why this gap is so large, our overview of how AI benchmarks work is useful background. Systems that top standard benchmarks do so by recognizing patterns that appeared in training. ARC-AGI-3 explicitly removes that path.
The ARC-AGI-3 launch announcement covered the competition structure - the $2M+ prize pool, the three parallel tracks, and the November submission deadline. The technical paper released today provides the methodology behind the benchmark design and the scoring framework. The design choices are deliberate: no linguistic scaffolding, no external knowledge dependencies, calibrated against extensive human testing.
At 0.37%, the gap between humans and machines isn't closing fast enough to write off. The benchmark will run through November 2, with results announced December 4.
Reading Across the Three Papers
The common thread isn't pessimism - it's precision. All three papers push back against using coarse metrics to evaluate AI capability.
Multi-agent consensus doesn't mean collective intelligence. Aggregate uncertainty scores don't tell you what to fix. High benchmark scores on existing tasks don't transfer to novel environments. Each paper offers a more granular lens on a problem that the field has been measuring too bluntly.
Tanaka gives us scaling laws for when to trust multi-agent output. The uncertainty decomposition gives us a diagnostic framework for model failures. Chollet's benchmark gives us a task where the old measurement shortcuts simply don't apply.
That combination of more careful measurement tools is, arguably, more useful right now than another round of capability claims.
Sources:

