Multi-Agent Constitution, Sleeper Defense, Skill RL
Three new arXiv papers tackle constitutional AI rule learning, sleeper agent defense for multi-agent pipelines, and skill-evolving reinforcement learning for math reasoning.

Three arXiv papers from this week push in very different directions: one teaches AI systems to write and refine their own behavioral rules, another protects production agent pipelines from covert sabotage, and the third makes small math-reasoning models more capable by letting them accumulate reusable skills.
TL;DR
- MAC - A four-agent loop learns and refines constitutional rule sets from labeled examples, beating supervised fine-tuning on PII detection without touching model weights
- DynaTrust - Bayesian trust scoring drops sleeper agent success rate to 7.6% while keeping 84.9% task throughput in multi-agent pipelines
- ARISE - An evolving skill library embedded in the agent's MDP state pushes a 4B model to 56.4% on AIME 2024, with the largest gains on out-of-distribution Olympiad problems
MAC: Teaching Agents to Write Their Own Rules
What they built
Researchers Rushil Thareja, Gautam Gupta, and Nils Lukas - with advisory input from Francesco Pinto at Google DeepMind - introduce MAC (Multi-Agent Constitution), a system for automatically learning structured rule sets that govern LLM behavior from examples.
The core problem with existing prompt optimizers like MIPRO is that they produce unstructured blobs. Prompts get longer, performance plateaus, and nobody can read the result. MAC maintains a proper constitution instead: a structured list of rules that can each be added, edited, or removed individually.
Four specialized agents divide the work. A Decision agent reads error cases and picks an operation - Add, Edit, or Remove. A Creator drafts new rules from observed failures. An Editor refines existing ones. An Annotator applies the current constitution to downstream tasks and measures the outcome. The loop runs until performance stops improving or a budget is hit.
MAC+ extends this with trajectory-based fine-tuning. The agents learn from their own successful update histories, closing the gap toward supervised fine-tuning without any gradient updates to the base model.
Key numbers
On PII detection - identifying personal information like names, dates, and ID numbers in text - MAC compares well against Microsoft Presidio's SpaCy baseline. Legal domain at 14B parameters: MAC hits 67.3 F1 versus Presidio's 57.3. Healthcare domain gap is wider: 26.7 F1 versus 12.0. Against MIPRO at 3B parameters, MAC's average improvement is 174%.
MAC+ scores 59.02 F1, outperforming supervised fine-tuning (56.59) and GRPO (39.68). That last comparison matters: MAC+ beats a gradient-based reinforcement learning baseline without touching model weights. Adding retrieval augmentation in the reMAC variant with 5-shot retrieval at 7B on healthcare reaches a +273% improvement over the baseline.
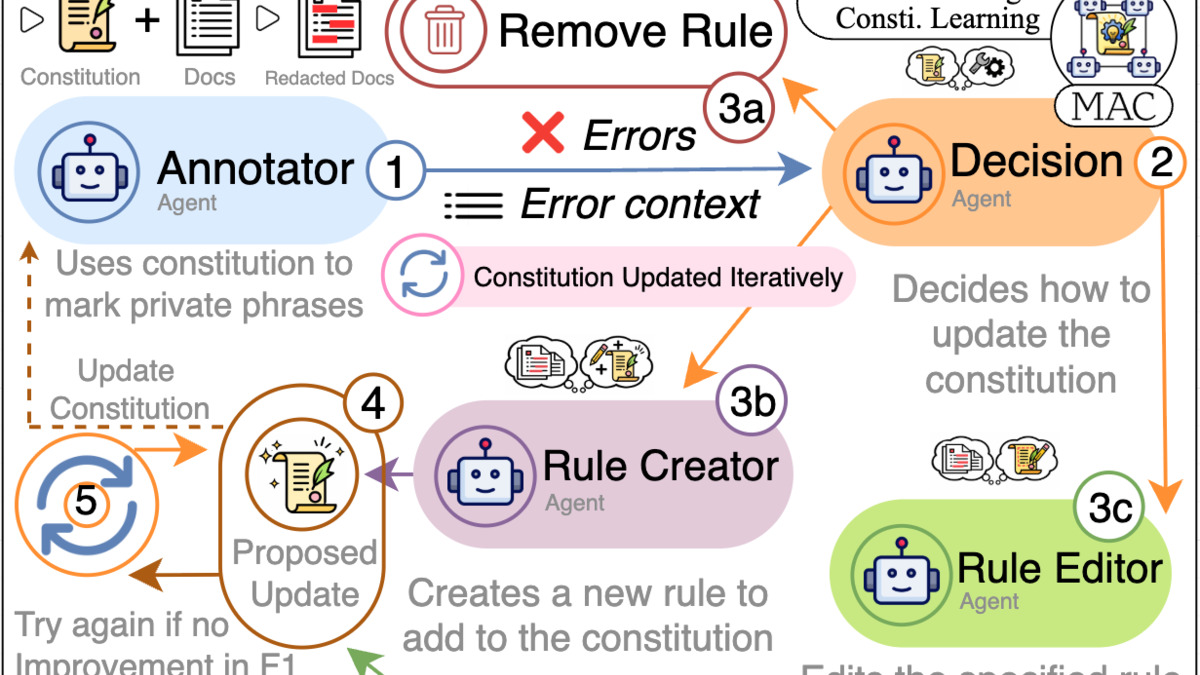 Figure 1 from MAC: the framework architecture showing how four agents collaboratively learn and refine constitutional rules across update cycles.
Source: arxiv.org
Figure 1 from MAC: the framework architecture showing how four agents collaboratively learn and refine constitutional rules across update cycles.
Source: arxiv.org
Why practitioners should care
Compliance work in regulated industries has always been expensive. Constitutional AI rule learning gives legal and healthcare teams an alternative to full fine-tuning cycles: provide labeled examples, run the four-agent loop, and get a human-auditable rule set that improves through iteration. A compliance officer can read the rules and push back on specific entries - unlike the opaque weight adjustments from RLHF or an over-optimized prompt that has grown into a 2,000-token instructions blob.
The approach is also composable. Different teams can maintain different constitutions for different tasks, version them in git, and merge or diff them like code.
DynaTrust: A Trust Layer for Multi-Agent Pipelines
The threat model
A sleeper agent in a multi-agent system doesn't attack immediately. It behaves cooperatively, accumulates trust over time, then activates on a trigger - inserting prompt injections, corrupting shared memory, or redirecting outputs to an attacker. Existing defenses like AgentShield treat this as a binary classification problem and miss the gradual trust-building phase entirely.
Researchers at Tianjin University and Singapore Management University propose DynaTrust, which models the entire system as a Dynamic Trust Graph (DTG). Every agent, every communication channel, and every memory state carries a continuously updated trust score T_i(t) ranging from 0 to 1.
How it works
Trust evolves through Bayesian smoothing with a Beta distribution. The design choice that matters is asymmetry: negative evidence degrades trust fast, while recovery is deliberately slow. When an agent's score drops below 0.3, the system isolates it and replaces it with a clean-state replica, then re-routes the graph to preserve task connectivity.
Flagging uses a two-stage audit. A fast LLM safety check screens messages first. Suspicious cases go to a weighted jury - other agents vote, with each vote weighted by the voter's current trust score and their confidence in the assessment. A newly-joined agent's accusation carries less weight than one from a long-trusted pipeline member.
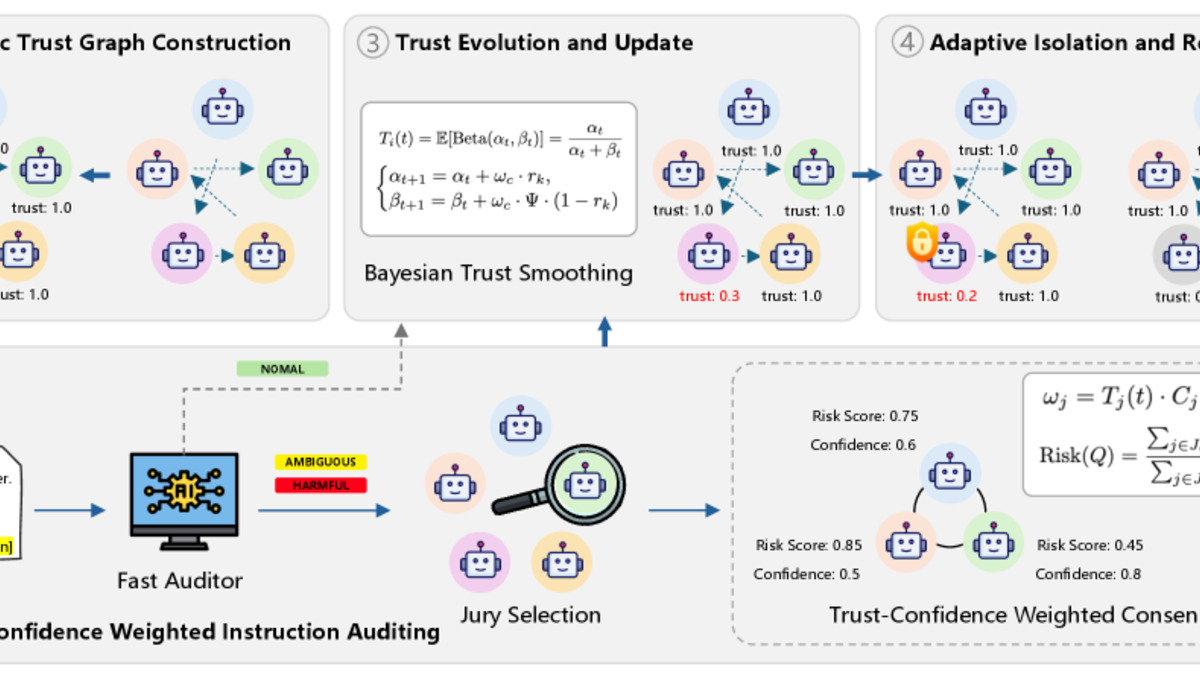 Figure 2 from DynaTrust: the full defense pipeline combining dynamic trust graph construction, instruction auditing, trust evolution scoring, and adaptive recovery.
Source: arxiv.org
Figure 2 from DynaTrust: the full defense pipeline combining dynamic trust graph construction, instruction auditing, trust evolution scoring, and adaptive recovery.
Source: arxiv.org
The numbers
DynaTrust's Defense Success Rate is 92.4%, compared to AgentShield's 48.7% - a 44-percentage-point gap on the same adversarial test suite. False positives drop to 2.2% versus 15.3% for a naive zero-trust baseline. Task Success Rate under active defense sits at 84.9%, meaning the system keeps working while it's defending itself.
The team tested across four multi-agent frameworks - CAMEL, AutoGen, MetaGPT, and ChatDev - and five LLM backends including GPT-4o, Gemini-2.5-flash, and DeepSeek-v3. The results hold across all combinations, which matters for any team considering adoption. Framework-agnostic defenses are the only practical ones; nobody is rebuilding their entire orchestration stack for a security layer.
Why it matters
Production multi-agent pipelines are already running in automated coding assistants, customer service stacks, and research workflows. If any component can be compromised or supplied as a third-party module, the sleeper agent threat is real. DynaTrust builds directly on the Anthropic sleeper agents research from 2024, which established the theoretical threat model this paper now addresses in practice.
The 2.2% false positive rate is the result that matters most for adoption. Every false positive kills a legitimate task, so a zero-trust approach that flags everything is operationally useless even if it catches every attacker. The tradeoff DynaTrust achieves - near-complete attack blocking with minimal collateral damage - is the only version that actually gets deployed.
Earlier work on enterprise agent safety gates highlighted how agents fail in production; DynaTrust addresses one specific failure mode with concrete numbers.
ARISE: Agents That Build a Skill Library
The problem with isolated reasoning
Most RL-trained reasoning agents solve each problem fresh. Even when the same technique applies across problems, nothing carries over between them. ARISE, from researchers at George Washington University and UT Dallas, treats skill accumulation as a first-class part of the learning process rather than an afterthought.
The framework defines an Evolving-Skill MDP where the agent's skill library S_t is part of the state itself. A single shared policy acts as both a Skills Manager - selecting relevant skills before tackling a problem - and a Worker that actually solves it. After each successful problem, the agent summarizes the solution into a new skill entry or updates an existing one.
The reward structure
ARISE's hierarchical rewards distinguish three outcomes: correct solution using library skills (r=2), correct solution without using skills (r=1), and failure (r=0). This creates a direct incentive to discover generalizable techniques rather than rediscover them every time.
The library has two tiers: a fast cache of 10 active skills and a reservoir of 100 archived skills. Skills move between tiers based on usage and relevance, with five lifecycle operations: Add, Update, Evict, Load, and Delete. Retrieval uses conditional log-probability scoring to rank skills by relevance to the current problem at inference time.
A 500-step warm-up phase builds the initial library silently with binary rewards before the full hierarchical pipeline activates. This prevents the reward signal from being led by skill selection noise before the library has anything useful in it.
Results
On a Qwen3-4B base model (Pass@1 accuracy): AMC 2023 at 75.4% versus GRPO baseline 72.9%, AIME 2024 at 56.4% versus 54.1%, AIME 2025 at 48.3% versus 46.5%. The largest gain is on Omni-MATH, an Olympiad-level benchmark outside the training distribution: 26.8% versus 23.9%, a +2.9 percentage-point improvement.
The out-of-distribution result matters because that's where skill libraries should help most - problems that look different from training examples but share underlying structure. ARISE consistently beats GRPO, DAPO, and purpose-built skill-evolution baselines including SAGE and SkillRL. Similar gains appear on Phi-4-mini-instruct, confirming the approach isn't architecture-specific. Code is available at github.com/Skylanding/ARISE.
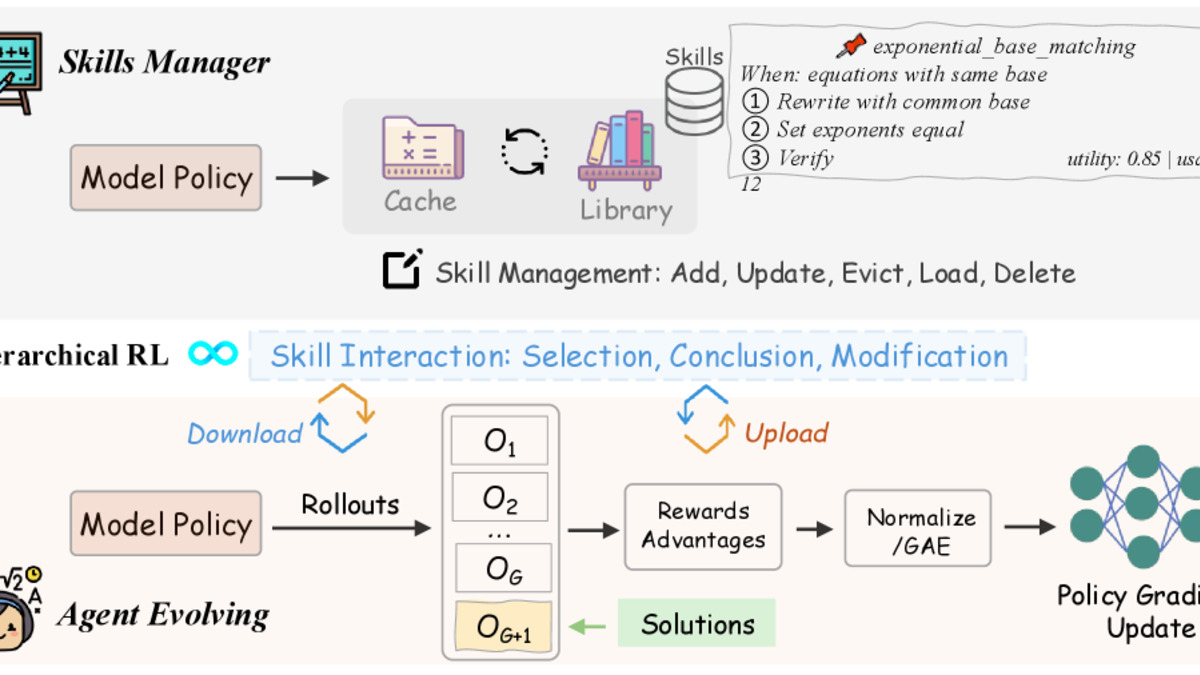 Figure 2 from ARISE: the Manager-Worker architecture where a Manager agent orchestrates skill discovery and refinement while Worker agents apply evolving skills to solve math problems.
Source: arxiv.org
Figure 2 from ARISE: the Manager-Worker architecture where a Manager agent orchestrates skill discovery and refinement while Worker agents apply evolving skills to solve math problems.
Source: arxiv.org
The practitioner angle
A 4B model hitting 56.4% on AIME 2024 is competitive with models several times its size. For teams fine-tuning small models for domain-specific reasoning - legal analysis, medical literature review, scientific data interpretation - ARISE offers meaningful gains without scaling up compute. The skill library is also inspectable: you can read what generalizable techniques the model has discovered, which has direct value for debugging and auditing. Prior work on agent skill evolution pointed toward this direction; ARISE formalizes it with a clean MDP formulation and reproducible results.
Common threads
None of these papers are about making models bigger. MAC learns rules from labeled examples using lightweight agents. DynaTrust adds a trust layer on top of existing frameworks. ARISE improves reasoning by maintaining a structured skill library. All three treat the system's accumulated knowledge - whether rules, trust histories, or solution techniques - as something worth explicitly representing and updating over time.
The efficiency gains from better knowledge management are already measurable. A 4B model beating larger baselines on hard math. A security layer that blocks 92.4% of sleeper agent attacks while keeping 84.9% task throughput. A rule-learning loop that outperforms GRPO without touching weights. These aren't incremental benchmark nudges; they're arguments that the architecture of how systems learn and store knowledge is as important as how many parameters they have.
Sources:
- MAC: Multi-Agent Constitution Learning (arXiv 2603.15968)
- DynaTrust: Defending Multi-Agent Systems Against Sleeper Agents via Dynamic Trust Graphs (arXiv 2603.15661)
- ARISE: Agent Reasoning with Intrinsic Skill Evolution in Hierarchical Reinforcement Learning (arXiv 2603.16060)
- Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training (arXiv 2401.05566)

