MoE Myths, Context Compression, and Steering Proofs
Three papers this week challenge how we think about MoE expert routing, LLM context management, and the limits of activation steering.

Three papers landed this week with results that should make practitioners stop and reconsider some deeply held assumptions. One dismantles a central belief about how Mixture of Experts models actually route tokens. Another shows that LLMs can learn to compress their own reasoning traces - cutting KV cache use by more than half. The third proves, with mathematics, that activation steering and prompt-based control are formally distinct interventions.
TL;DR
- The Myth of Expert Specialization in MoEs - Expert routing is driven by representation geometry, not architecture design, and experts aren't as specialized as assumed
- MEMENTO - LLMs trained to compress their own reasoning into dense summaries cut peak KV cache 2.5x and nearly double inference throughput
- Steered LLM Activations are Non-Surjective - Activation steering pushes models off the manifold reachable by any prompt, making the two intervention types formally incomparable
The MoE Routing Story Doesn't Hold Up
Paper: "The Myth of Expert Specialization in Mixture of Experts" by Xi Wang, Soufiane Hayou, and Eric Nalisnick. ArXiv:2604.09780.
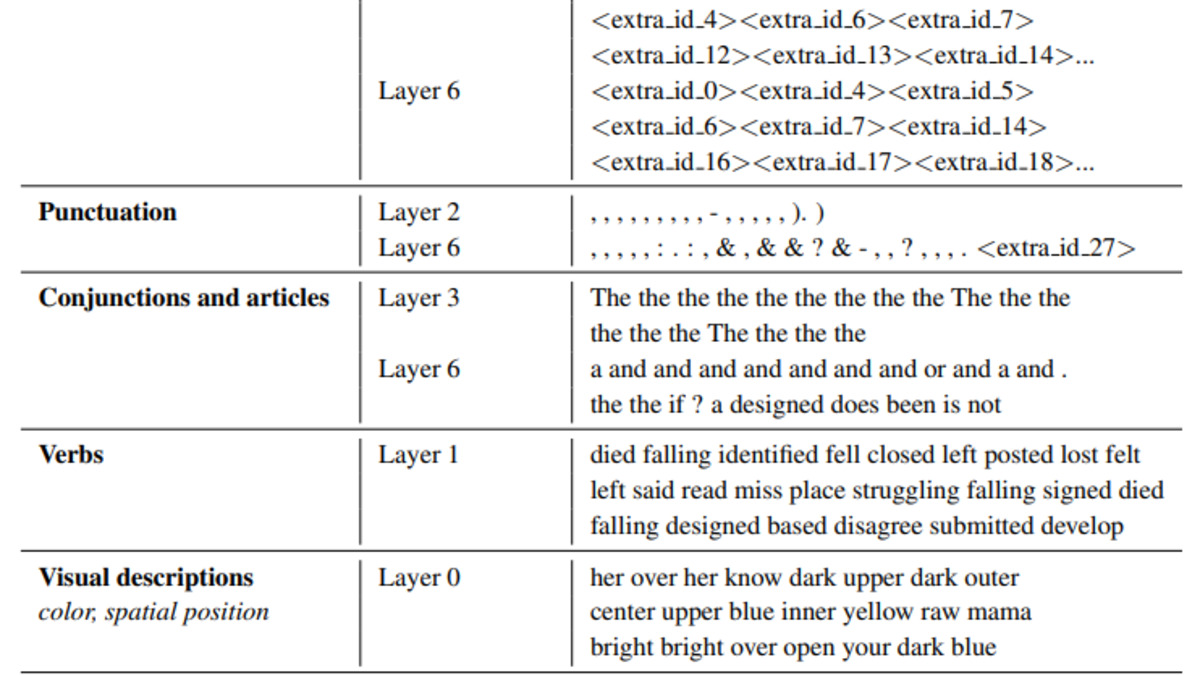
Mixture of Experts models - used in Mixtral, DeepSeek V3, and a growing share of frontier systems - are built around a seductive idea: different experts specialize in different types of content. The router learns to send math tokens to the math expert, code tokens to the code expert, and so on. It's clean, intuitive, and mostly wrong.
Wang, Hayou, and Nalisnick show that expert specialization in MoE models isn't a product of the routing architecture at all. It's an emergent consequence of the representation space geometry. With linear routers, hidden state similarity becomes both necessary and sufficient to explain which expert a token gets sent to. The router isn't learning semantic categories; it's reflecting the geometry of the embeddings it receives.
 How a Switch Transformer-style gating network dispatches tokens to experts - the geometry of embeddings, not learned semantic categories, drives these choices.
Source: huggingface.co
How a Switch Transformer-style gating network dispatches tokens to experts - the geometry of embeddings, not learned semantic categories, drives these choices.
Source: huggingface.co
The load-balancing loss that most MoE implementations use actually suppresses shared directions in the representation space to keep routing varied. Routing variety is maintained, but specialization in any interpretable sense isn't the result. Deeper layers show nearly identical expert activation patterns regardless of the semantic content being processed.
The most pointed result: when the researchers measured expert overlap between models answering identical questions versus completely different questions, the overlap was only around 60% in both cases. Same question, different question - the routing looks almost the same. That's a number practitioners building on top of MoE systems should sit with.
What This Means for Practitioners
If you're building an application that relies on MoE routing to implicitly separate types of work - assuming math queries route differently from text queries, for instance - the empirical reality is less clean than the architecture diagrams suggest. The theoretical proofs hold across five pre-trained MoE models at both token and sequence levels, so this isn't a quirk of one model family.
It also complicates the case for interpretability tooling that treats MoE experts as semantically coherent units. They aren't, at least not in the way the framing implies.
Teaching LLMs to Manage Their Own Context
Paper: "MEMENTO: Teaching LLMs to Manage Their Own Context" by Vasilis Kontonis, Yuchen Zeng, Shivam Garg, Lingjiao Chen, Hao Tang, Ziyan Wang, Ahmed Awadallah, Eric Horvitz, John Langford, and Dimitris Papailiopoulos. ArXiv:2604.09852.
KV cache growth is one of the less glamorous but very real constraints on deploying reasoning-capable LLMs at scale. Long chains of thought that a model needs to produce good answers are exactly the thing that fills your GPU memory and tanks throughput. The MEMENTO paper, from a team at Microsoft Research among others, takes a direct approach: train the model to compress its own reasoning into dense summaries as it goes.
The method segments a model's reasoning trace into blocks - sentences, code blocks, equations - and trains the model to create a "memento" for each block before moving on. The memento carries forward everything the model needs to keep reasoning without access to the original block's tokens. After producing the memento, the original block's KV cache entries can be discarded.
How Well It Works
The results are concrete. On a B200 GPU, a MEMENTO-trained model ran at 4,290 tokens per second versus 2,447 for the baseline - a 1.75x throughput improvement. Peak KV cache dropped 2.5x. Models trained this way maintained strong accuracy on math, science, and coding benchmarks. The researchers showed 96.4% overlap between problems solved by base models and MEMENTO models, with the gap closable further through voting or reinforcement learning.
Training used OpenMementos, a new dataset of 228,000 reasoning traces segmented and annotated with intermediate summaries. About 54% of the dataset is math, 19% code, 27% science - which matters for practitioners assessing generalization. The dataset compresses roughly 11,000 tokens of reasoning down to under 2,000 tokens of mementos per trace, a roughly 6x trace-level compression ratio.
One finding worth noting: removing the KV cache for masked blocks entirely (what they call "restart mode") dropped AIME'24 accuracy from 66.1% to 50.8%. Information from earlier reasoning blocks leaks forward through KV representations even when those blocks aren't attended to directly. The model uses two channels to carry context forward - the memento text and the KV state - and both matter.
The approach was tested across Qwen3, Phi-4, and OLMo 3 at 8B to 32B parameter scales, which suggests it isn't model-specific. If you're thinking about long-context inference costs, this is a more structured alternative to approaches like KV cache pruning or token compression.
Activation Steering and Prompting Are Not the Same Thing
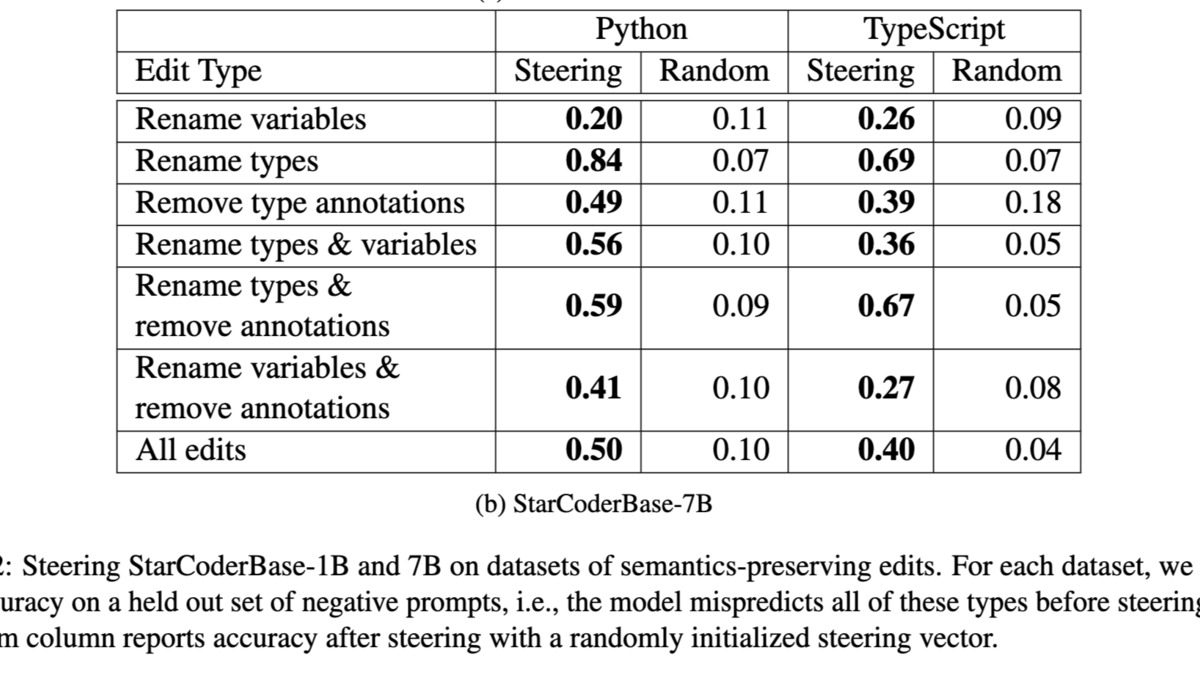
Paper: "Steered LLM Activations are Non-Surjective" by Aayush Mishra, Daniel Khashabi, and Anqi Liu. ArXiv:2604.09839.
Activation steering - injecting vectors into a model's residual stream to push its behavior in a desired direction - has grown into a serious research area. It's used for persona modification, safety interventions, and interpretability probes. One implicit assumption in much of this work is that steering effects can be explained or copied via prompting: if you can steer a model toward a behavior, there should be some prompt that gets you there too.
Mishra, Khashabi, and Liu prove this assumption is false.
 Empirical results showing behavioral differences between steering-based interventions and equivalent prompting attempts - the two intervention types don't converge even when targeting the same behavior.
Source: sidn.baulab.info
Empirical results showing behavioral differences between steering-based interventions and equivalent prompting attempts - the two intervention types don't converge even when targeting the same behavior.
Source: sidn.baulab.info
They frame the question as a surjectivity problem. Given a fixed model, can every activation-steered state be reached via some natural textual prompt? The answer, proven formally under practical assumptions, is no. Activation steering pushes the residual stream off the manifold of states reachable from discrete prompts. Almost surely, no prompt can reproduce the internal behavior induced by steering.
Why This Matters for Interpretability Research
The result creates a formal separation between white-box and black-box interventions. This has direct implications for how researchers interpret results from both sides. A steering intervention that "successfully" instills a behavior isn't evidence that the same behavior is achievable through prompting. But a prompt that fails to elicit a behavior doesn't tell you whether the behavior is accessible via steering.
For safety researchers, this cuts both ways. Steering-based jailbreaks that work in white-box settings may not translate to black-box access, which is somewhat reassuring. But interpretability claims that treat steering vectors as stand-ins for prompt-based concepts need to be revisited - the two aren't probing the same space.
The paper confirms results empirically across three widely used LLMs. It doesn't resolve what steering is measuring when it works, but it's precise about what it isn't.
The Common Thread
These three papers each challenge a default assumption that the field has been operating on. MoE experts don't specialize the way the framing suggests. KV cache growth from long reasoning chains isn't an immovable constraint. And white-box interpretability tools don't commute with black-box prompting.
None of these results mean the underlying techniques are useless - MoE still works, activation steering still works, long context still works. They do mean the intuitions used to justify these approaches need updating. The architecture diagrams and the conceptual stories that accompany them are lagging the empirical evidence.
Earlier we covered related ground on interpretability limits and probe blind spots. This week's papers add more formal weight to what was already a skeptical picture.
Sources:
