MedGemma 1.5, Smarter MCTS, and Auditing AI Agents
Google's MedGemma 1.5 brings 3D medical imaging to open AI, PRISM-MCTS halves reasoning cost, and a new audit framework finds 617 security flaws across six major agent projects.

Three papers this week that each point to a different pressure building in AI development: what happens when models move into high-stakes domains, how we make inference cheaper without sacrificing quality, and whether the agent systems we're deploying can even be held accountable when something goes wrong.
TL;DR
- MedGemma 1.5 - Google's open medical AI model now handles full 3D CT and MRI volumes natively, with MRI classification jumping from 51% to 65% accuracy and pathology ROUGE-L improving from 0.02 to 0.49
- PRISM-MCTS - A new MCTS framework using shared memory and metacognitive reflection halves trajectory requirements on GPQA while beating Search-o1
- Auditable Agents - Audit of six major open-source agent projects found 617 security findings; adding tamper-evident logs costs just 8.3ms median overhead
MedGemma 1.5 - Google Opens Up 3D Medical Imaging
The jump from MedGemma to MedGemma 1.5 isn't a routine version bump. The new model, a 4B parameter multimodal system from Google, is the first open medical generalist model that can natively process full 3D imaging volumes - complete CT and MRI scans rather than individual slices. That distinction matters enormously for clinical workflows, where a radiologist reading a chest CT is interpreting a stack of 300-500 cross-sectional images, not a single frame.
 MRI scanners generate hundreds of cross-sectional slices per scan - the kind of 3D volume MedGemma 1.5 can now process natively.
Source: commons.wikimedia.org
MRI scanners generate hundreds of cross-sectional slices per scan - the kind of 3D volume MedGemma 1.5 can now process natively.
Source: commons.wikimedia.org
The accuracy gains bear that out. MRI disease classification improved from 51% to 65% - a 14 percentage point gain on a task that was clearly undertrained in the first release. CT disease classification moved from 58% to 61%. Pathology imaging tells an even sharper story: the ROUGE-L score for histopathology whole slide images went from 0.02 to 0.49, which means the first version was essentially failing at the task. MedGemma 1.5 now matches the performance of PolyPath, a specialized pathology model.
| Benchmark | MedGemma v1 | MedGemma 1.5 | Change |
|---|---|---|---|
| CT disease classification | 58% | 61% | +3pp |
| MRI disease classification | 51% | 65% | +14pp |
| Pathology ROUGE-L | 0.02 | 0.49 | +47pp |
| Anatomical localization (IoU) | 3% | 38% | +35pp |
| MedQA reasoning | 64% | 69% | +5pp |
| EHRQA (EHR Q&A) | 68% | 90% | +22pp |
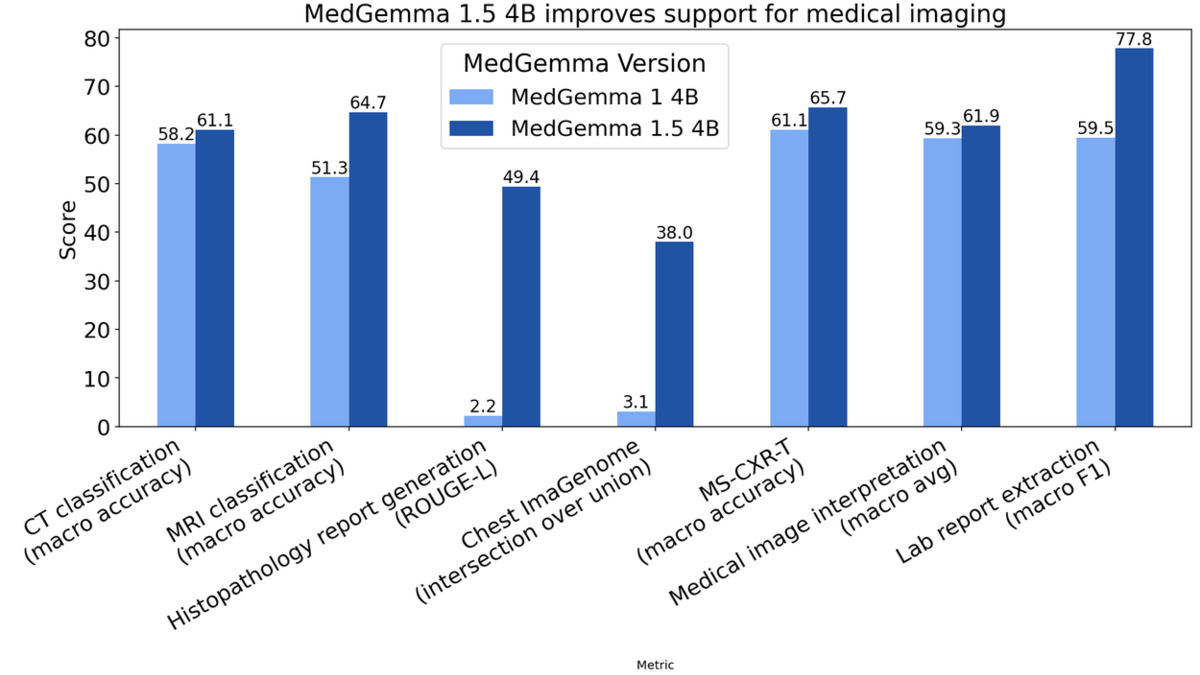 MedGemma 1.5 benchmark comparison from the Google Research blog. The pathology and localization improvements are the largest gains.
Source: research.google
MedGemma 1.5 benchmark comparison from the Google Research blog. The pathology and localization improvements are the largest gains.
Source: research.google
The electronic health records numbers are striking in their own right. A 22 percentage point improvement on EHRQA puts the model well past the 80% threshold that tends to get taken seriously in clinical informatics research.
Google is also releasing MedASR alongside the model - a medical speech recognition system targeting clinical dictation. On chest X-ray dictations, MedASR achieves a 5.2% word error rate compared to 12.5% for Whisper large-v3. For general medical dictation across varied specialties, the gap widens further: 5.2% versus 28.2%. That second number suggests Whisper struggles badly with specialized medical vocabulary, which anyone who has tried to dictate a pathology report with a general-purpose model already knows.
Both models are free for research and commercial use via Hugging Face and Google Cloud's Vertex AI. Google is also running a $100,000 Kaggle hackathon to push developer adoption. The standard disclaimer applies: MedGemma isn't intended for direct clinical diagnosis without validation and adaptation by the launching organization. Real-world deployments include Qmed Asia's askCPG tool in Malaysia, which uses the model to provide conversational access to 150+ clinical practice guidelines.
For practitioners interested in multimodal AI, MedGemma 1.5 is the most capable open medical foundation model currently available. The 4B parameter size also means it's deployable offline, which matters notably for resource-constrained healthcare settings.
PRISM-MCTS - Reasoning That Learns From Itself
Monte Carlo Tree Search has had a moment in AI reasoning research. The idea of using MCTS to explore solution paths before committing to an answer has produced strong results on hard reasoning tasks. The problem is efficiency: most MCTS implementations treat each rollout as a separate, stateless exploration, burning tokens rediscovering the same dead ends over and over.
PRISM-MCTS, from researchers at ACL 2026, attacks exactly this waste. The system adds two components to standard MCTS: a Process Reward Model (PRM) that scores intermediate reasoning steps rather than just final answers, and a dynamic shared memory that accumulates knowledge across rollouts. When the search finds a promising path or identifies a consistently wrong approach, that information spreads to subsequent rollouts rather than being discarded.
Scaling inference by reasoning judiciously rather than exhaustively - that's the core proposition. Fewer rollouts, same or better performance.
The results on GPQA - a benchmark of truly difficult graduate-level questions in biology, chemistry, and physics - show PRISM-MCTS needs roughly half the trajectories of comparable approaches to reach the same accuracy. It outperforms both MCTS-RAG and Search-o1 on the benchmark.
The PRM training strategy deserves attention. Getting good process-level supervision is expensive because it requires humans or a strong model to label intermediate steps, not just final answers. PRISM-MCTS develops a data-efficient training approach that works under a few-shot regime, which makes the method more accessible to teams that don't have the budget for massive annotation pipelines.
For practitioners building reasoning-heavy applications, this is worth watching. The reasoning benchmarks leaderboard has seen a surge of new entries in 2026, most of them chasing higher accuracy through more compute. PRISM-MCTS is betting that smarter search beats brute-force rollout expansion - and the GPQA numbers support that bet.
Auditable Agents - 617 Reasons to Pay Attention
The third paper isn't proposing a new model architecture or a new training trick. It's asking a more uncomfortable question: if an AI agent does something wrong in production, can you actually figure out what happened?
Researchers from Yi Nian, Aojie Yuan, and colleagues audited six prominent open-source AI agent projects and found 617 security findings across them. The paper is careful to distinguish between three concepts that often get conflated. Accountability means being answerable for actions. Auditability means having the technical infrastructure to reconstruct what happened. Auditing is the process of actually doing that reconstruction. The paper argues, credibly, that you can't have accountability without auditability - and most current agent systems are failing the auditability test.
The researchers identify five dimensions where agent systems need to be measurable:
- Action recoverability - can you reconstruct what the agent did, even partially, without conventional logs?
- Lifecycle coverage - does logging capture the full agent lifecycle, including pre-execution and teardown?
- Policy checkability - can you verify whether the agent was operating within defined constraints at any given moment?
- Responsibility attribution - when multiple agents or humans are involved, can you assign blame or credit accurately?
- Evidence integrity - are audit records tamper-evident, or can they be modified after the fact?
The 617 findings suggest most of the projects assessed fail on several of these dimensions simultaneously. That's not a knock on the teams behind those projects - auditability wasn't a design requirement when most of them were built. But as agents move into enterprise contexts where regulatory compliance matters, it'll need to become one.
No agent system can be accountable without auditability. The paper's central claim is simple, and the audit results make it hard to argue with.
The performance overhead argument for skipping audit infrastructure doesn't hold up either. The paper shows that pre-execution mediation with tamper-evident records adds just 8.3ms median latency overhead. For most agent applications running tasks that take seconds or minutes, that's negligible. The paper also proposes an Auditability Card format - a structured checklist that developers can use to document and assess the auditability properties of their agent systems, similar in spirit to model cards for ML models.
This connects directly to ongoing concerns tracked in the agentic AI benchmarks leaderboard: we have good ways to measure what agents can do, but far fewer tools for measuring whether we can trust the record of what they did.
Common Thread
These three papers are working on different problems, but they share a common context: AI systems are moving into environments where failure is expensive. Medical diagnosis, multi-hop reasoning chains, enterprise agent deployments - these aren't toy tasks where a wrong answer costs nothing.
MedGemma 1.5 is Google's answer to the question of how good open medical AI needs to be before it's useful in real deployments. PRISM-MCTS is an efficiency argument at a moment when inference costs still constrain practical reasoning. Auditable Agents is asking whether the accountability infrastructure even exists to deploy agents responsibly at scale. All three are trying to close the gap between research benchmarks and the requirements of real-world use.
Sources:

