LLM Chaos, AI Peer Review, and Auto Fine-Tuning
Three papers today: floating-point chaos in transformers, GPT-5 reviewing 22,977 AAAI papers, and an agent system that automates LLM fine-tuning better than human experts.

Three papers today that don't share a topic but share a spirit: each one pokes at something practitioners assume works fine and finds it wobblier than expected. One shows that transformer outputs can diverge catastrophically from numerical rounding alone. Another measures what happened when 22,977 conference papers were reviewed by AI - and the results surprised the researchers who ran the study. The third shows an agent system consistently beating hand-crafted fine-tuning recipes.
TL;DR
- Numerical chaos in LLMs - Tiny floating-point rounding errors trigger "avalanche effects" in early transformer layers, causing outputs to flip ~15% of the time near decision boundaries
- AAAI-26 AI review pilot - GPT-5 reviewed all 22,977 AAAI papers in under 24 hours; 53.9% of participants found the reviews useful, and AI was preferred over humans on 6 of 9 criteria
- TREX - A two-agent fine-tuning system that models training as a search tree, surpassing expert-designed recipes by +228% to +336% on domain-specific benchmarks
When Rounding Errors Crash Transformer Outputs
The paper: Numerical Instability and Chaos: Quantifying the Unpredictability of Large Language Models, from Chashi Mahiul Islam, Alan Villarreal, Mao Nishino, Shaeke Salman, and Xiuwen Liu.
Most people who work with LLMs know they're non-deterministic - run the same prompt twice and you might get different outputs. The usual explanation is temperature sampling. This paper points to a different mechanism completely: floating-point arithmetic.
The researchers used directional derivatives to measure how sensitive transformer outputs are to perturbations at floating-point epsilon scale (around 10^-14). What they found is that early transformer layers can behave chaotically. A rounding error too small to observe directly either vanishes or explodes. Directional condition numbers exceed 10^6 in chaotic regions, meaning an imperceptible perturbation can be amplified by a factor of a million before it reaches the output layer.
 The double pendulum - a classic chaos theory system where tiny differences in initial conditions lead to wildly different trajectories. Transformer layers near decision boundaries behave similarly with floating-point perturbations.
Source: commons.wikimedia.org
The double pendulum - a classic chaos theory system where tiny differences in initial conditions lead to wildly different trajectories. Transformer layers near decision boundaries behave similarly with floating-point perturbations.
Source: commons.wikimedia.org
The paper identifies three distinct operating regimes. In constant regions, perturbations fall below a threshold and the output stays bit-for-bit identical. In chaotic regions, rounding noise dominates and drives output divergence. In signal-dominated regions, actual input variation overrides the numerical noise. The median instability across runs is 0.0, but the mean is 10^5 to 10^6 - because when instability hits, it hits hard.
Testing on Meta-Llama-3.1-8B-Instruct and OpenAI-GPT-OSS-20B across TruthfulQA and AdvBench, the team found roughly 15% output flip frequency near decision boundaries, with 779-866 fragmented stable regions and crossing densities of 49-52 per normalized dimension. The fix is disarmingly simple: noise averaging over just 10-100 samples stabilizes estimates toward true singular values without much compute overhead.
Why does this matter? LLM deployments that require reproducibility - legal document review, medical summarization, any regulated context - can't assume stability just because temperature is set to zero. This paper gives practitioners a framework to measure where in input space their model lives dangerously. The mitigation is cheap; knowing you need it is the harder part.
GPT-5 Reviews Your Conference Paper - And Reviewers Liked It
The paper: AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot, from Joydeep Biswas, Sheila Schoepp, Gautham Vasan, and ten collaborators.
For the AAAI-26 conference held in Singapore in January 2026, the organizers did something nobody at that scale had tried before: they produced AI reviews for every single one of the 22,977 main-track submissions. Not as a replacement for human review - as a supplement, clearly labeled, with no scores or recommendations attached.
The system used GPT-5 with high reasoning effort, combined with olmOCR (for converting PDFs to markdown), a Python code interpreter for technical verification, and web search for literature checks. Total cost: under $1 per paper. Total time: under 24 hours for all 22,977 papers. Human review of the same pile takes months and requires recruiting over 28,000 program committee members - which is what AAAI-26 also did.
The survey gathered 5,834 responses from authors, reviewers, senior program committee members, and area chairs. The headline number is 53.9% found the AI reviews useful versus 20.2% who didn't. But the more interesting data is the head-to-head comparison with human reviews across nine criteria.
AI was preferred on six: technical error identification (+0.67 mean difference), raising points reviewers hadn't considered (+0.61), presentation improvement suggestions (+0.54), research design recommendations (+0.49), and overall thoroughness (+0.48). Humans came out ahead on evaluating novelty and real-world impact - the judgment calls that require domain intuition accumulated over years.
 Academic peer review is under pressure from submission volumes doubling year over year. AAAI-26 ran the largest AI-assisted review experiment to date.
Source: commons.wikimedia.org
Academic peer review is under pressure from submission volumes doubling year over year. AAAI-26 ran the largest AI-assisted review experiment to date.
Source: commons.wikimedia.org
46.6% of reviewers said AI caught concerns humans would have missed. 49.4% said AI missed concerns humans would have caught. The results don't suggest replacing reviewers - they suggest AI catches a different class of problem than human reviewers do, which means the combination is better than either alone.
The paper also introduces a benchmark tool that the team says substantially beats a simple LLM-created review baseline at detecting scientific weaknesses. That benchmark could be useful beyond conferences - any research team that wants automated feedback before submission now has a more principled target to compare against.
One caveat worth noting: 61.5% expected AI reviews to be beneficial for future processes, but feedback also flagged excessive length, technical misreadings of equations and tables, and weak novelty assessment as real limitations. The tool isn't peer review - it's a structured pre-screen that catches a specific set of errors quickly. Conferences drowning in volume might find that more valuable than the framing suggests.
An Agent That Fine-Tunes Better Than Your ML Team
The paper: TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration, from Zerun Ma and nine collaborators.
Fine-tuning LLMs well is slow, iterative, and requires decisions that aren't obvious in advance: which data to use, how to mix it, what objective to optimize, when to stop. Practitioners who have read our fine-tuning and distillation guide know how many variables are in play. TREX automates the entire loop.
The architecture is a two-agent system. A Researcher module handles literature search, dataset discovery, and training strategy formulation. An Executor module manages data preparation, the training run itself, and evaluation. Between them, the system models the experimental process as a search tree - each node is a training configuration, branches represent modifications, and the tree structure lets the system reuse results from earlier runs rather than starting cold every time.
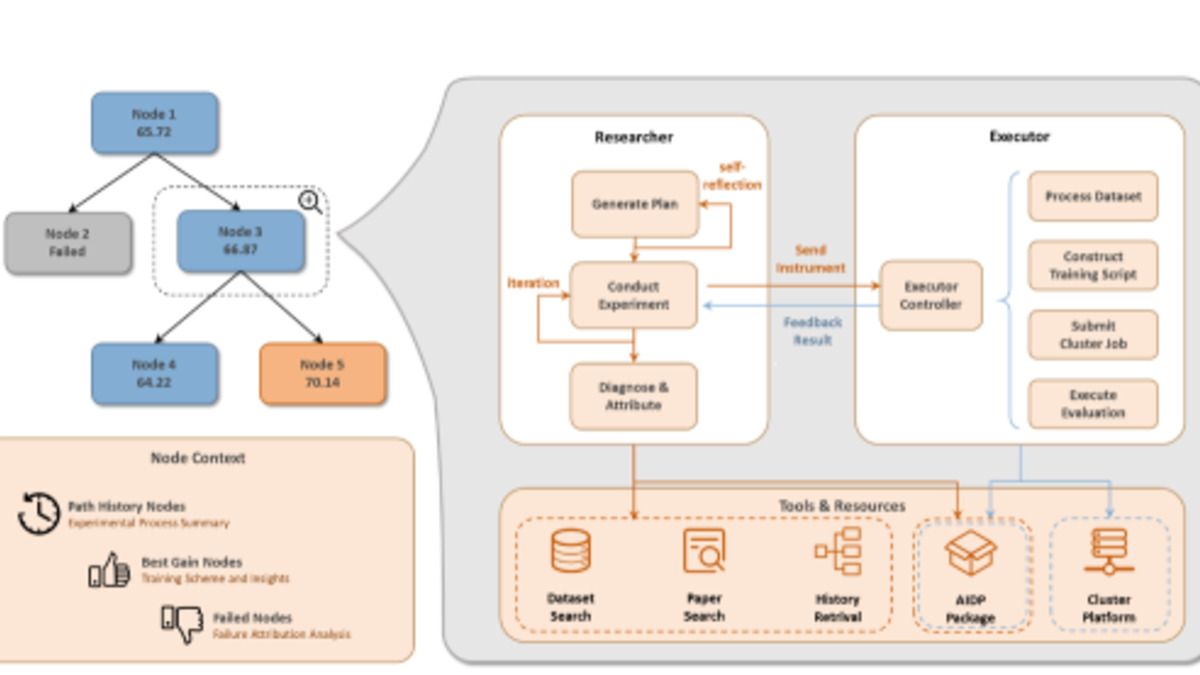 The TREX dual-agent architecture: Researcher drafts strategy while Executor runs the training loop. The tree-based structure lets the system learn from previous experiments.
Source: arxiv.org
The TREX dual-agent architecture: Researcher drafts strategy while Executor runs the training loop. The tree-based structure lets the system learn from previous experiments.
Source: arxiv.org
The team assessed TREX on FT-Bench, a new benchmark they built with 10 real-world fine-tuning tasks spanning biomedical text (ACI-Bench for clinical notes, HoC for cancer hallmark classification), chemistry (TOMG-Bench for molecule generation, oMeBench for reaction reasoning), finance (OpenFinData), law (LawBench), and more.
The numbers are striking. On oMeBench, TREX delivered +228% to +336% improvement over the reference model. On HoC, +237% to +238%. On TOMG-Bench, +82% to +108%, and TREX's 0.498 performance score on that benchmark surpasses expert-designed baselines like OpenMolIns-Large, which human ML engineers reached with scores between 0.025 and 0.207.
The significance isn't just the raw performance. It's that the system maintains these gains "under limited resource and time budgets," as the paper puts it. Real ML teams don't have unlimited GPU hours. TREX learns which experiments to run next from the tree structure - rather than random search or following a fixed recipe, it accumulates insight across runs.
This connects to the direction we tracked in the autonomous research roundup from last week, where AlphaLab agents ran multi-phase GPU research campaigns. TREX is a narrower tool aimed at one specific job, which probably makes it more deployable in practice. A team that wants to stop hand-tuning recipes for domain adaptation tasks now has a concrete system to test.
The Common Thread
These three papers are about the same underlying problem from different angles: we're building on top of systems we don't fully understand, and the gaps are becoming visible.
Floating-point chaos is a hardware-level property that survived the scaling transition intact. AI peer review is a capability that arrived faster than the community had theories to assess it. Automated fine-tuning works better than expert intuition in ways that practitioners will need to stress-test carefully before trusting at production scale.
None of these findings are catastrophic. All of them are practical.
Sources:
- Numerical Instability and Chaos: Quantifying the Unpredictability of Large Language Models (arXiv:2604.13206)
- AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot (arXiv:2604.13940)
- TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration (arXiv:2604.14116)
- AAAI-26 Review Process - AAAI
