Hyperagents, Milestone Rewards, and the 19x Efficiency Win
Three arXiv papers push AI agents further: metacognitive self-modification, milestone-based RL lifting Gemma3-12B from 6% to 43% on WebArena-Lite, and hybrid workflows cutting inference costs 19x.

Today's arXiv batch has three agent papers worth reading carefully. They're not gradual tweaks - each one addresses a specific limit that's been blocking real-world deployment: agents that can't improve their own improvement process, agents that get stuck halfway through complex web tasks, and workflows that burn through inference budget faster than they deliver value.
TL;DR
- Hyperagents - Self-referential agents extend the Darwin Gödel Machine so the improvement mechanism itself can be rewritten, with gains that transfer across coding, math, and robotics domains
- Gemma3-12B jumps from 6.4% to 43.0% on WebArena-Lite using milestone-based RL, beating GPT-4o (13.9%) and GPT-4-Turbo (17.6%)
- HyEvo mixes LLM nodes with deterministic code nodes in an evolutionary workflow, cutting inference costs by up to 19x vs. the best open-source baseline
Hyperagents: Modifying the Modifier
Paper: Hyperagents (arXiv:2603.19461) | Jenny Zhang, Bingchen Zhao, Wannan Yang, Jakob Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, Tatiana Shavrina
Last year, Sakana AI's Darwin Gödel Machine showed that agents can improve their own code - taking a coding benchmark from 20% to 50% by evolving and selecting better versions of themselves. That paper established the basic loop: write agents, test them, keep the best, repeat. But the improvement mechanism itself was fixed. You couldn't change how the machine decides to improve.
Hyperagents breaks that constraint. The new framework, DGM-Hyperagents (DGM-H), treats the meta-level modification procedure as another editable program. As the authors put it, "the meta-level modification procedure is itself editable, enabling metacognitive self-modification." The agent can rewrite not just what it does, but how it chooses to get better.
 The Darwin Gödel Machine's open-ended agent archive, which Hyperagents extends with editable meta-level improvement.
Source: sakana.ai
The Darwin Gödel Machine's open-ended agent archive, which Hyperagents extends with editable meta-level improvement.
Source: sakana.ai
What "metacognitive" actually means here
In standard self-improvement systems, a fixed optimizer selects among agent variants. The optimizer's own logic - how it scores candidates, how it generates new versions, what memory it maintains - is hardcoded. DGM-H makes that optimizer editable too.
This matters because prior systems assumed a "domain-specific alignment between task performance and self-modification skill." In plain terms: if you trained a coding agent to self-improve, that improvement process was calibrated for coding. DGM-H removes that assumption. The system can discover improvement strategies that generalize across domains.
The results span four domains: coding, paper review, robotics reward design, and Olympiad-level math solution grading. Improvements build up across runs rather than plateauing. Code is available under CC BY 4.0.
The obvious question is whether this forms a genuine capability jump or just a more flexible architecture. The authors are careful not to overclaim. Transfer across domains is shown empirically, not theoretically guaranteed. For practitioners, the short answer is: if you're building long-running self-improving systems, this is the paper to read. If you need a production agent next quarter, it's still research.
MiRA: Fixing the "Stuck Midway" Problem
Paper: A Subgoal-driven Framework for Improving Long-Horizon LLM Agents (arXiv:2603.19685) | Taiyi Wang, Sian Gooding, Florian Hartmann, Oriana Riva, Edward Grefenstette
Web navigation is one of the cleaner proxies for real-world agent usefulness, and the numbers on agentic benchmarks have been stubbornly low for open-source models. This paper from Wang et al. explains why and fixes it.
The diagnosis is specific: 42-49% of agent failures happen because agents get "stuck midway." They've completed several steps toward a goal, new information has arrived, and they lose track of where they are and what's left to do. The failure mode isn't at the start or the end - it's in the middle of complex multi-step tasks.
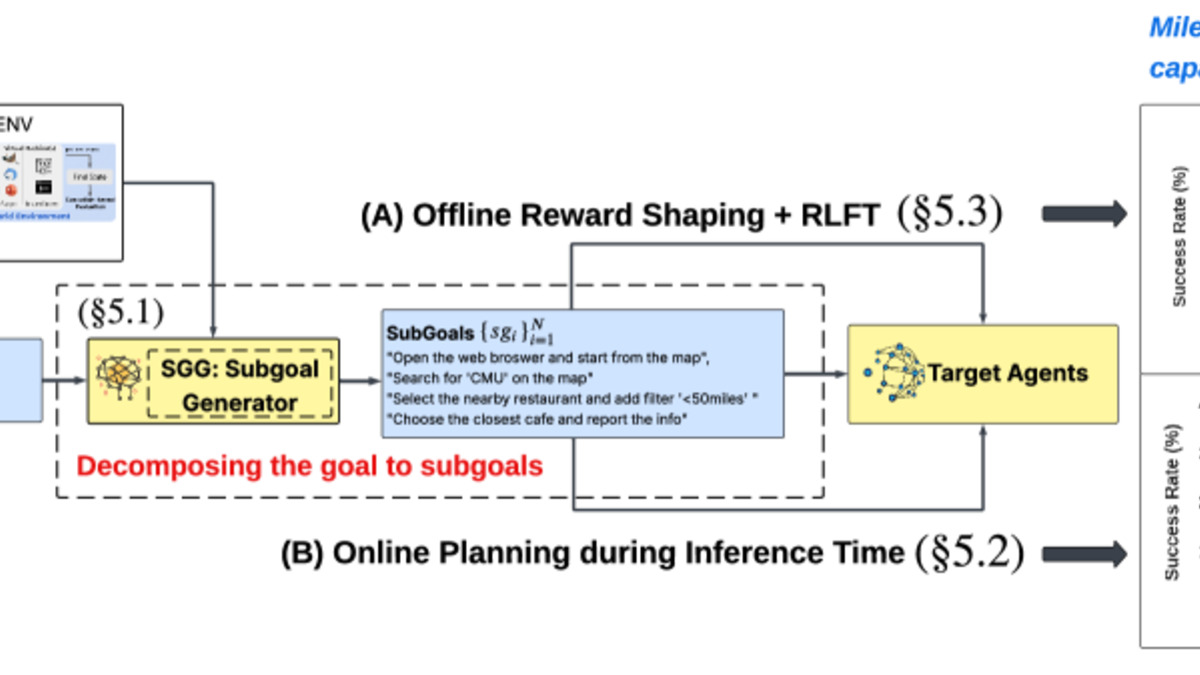 MiRA's architecture: a Potential Critic providing dense milestone rewards alongside a Value Critic tracking task success probability.
Source: arxiv.org
MiRA's architecture: a Potential Critic providing dense milestone rewards alongside a Value Critic tracking task success probability.
Source: arxiv.org
Two components, one fix
The paper proposes two interlocking pieces:
Subgoal generation (SGO) uses a teacher model - specifically Gemini-2.5-Pro - to decompose tasks into milestones at planning time. Rather than handing the agent a monolithic goal, SGO produces a sequence of verifiable checkpoints. An AutoRater validates which checkpoints have been hit in real time, preventing agents from hallucinating progress they haven't made.
MiRA (Milestoning RL Enhanced Agent) is the training-time component. Instead of a sparse binary reward at task completion, MiRA produces dense reward signals from subgoal completion. A Potential Critic converts discrete checkpoint events into smooth progress curves via linear interpolation, solving the credit assignment problem that makes long-horizon RL so difficult. A Value Critic runs in parallel, tracking the overall probability of task success.
The team confirms this with an AUROC of 0.84 for subgoal completion as a progress indicator - meaning these milestone signals truly predict success, not just correlate with it incidentally.
The numbers
| Model | Baseline | With MiRA/SGO |
|---|---|---|
| Gemma3-12B | 6.4% | 43.0% |
| Gemini-2.5-Pro | baseline | +10% absolute |
| GPT-4-Turbo (reference) | 17.6% | - |
| GPT-4o (reference) | 13.9% | - |
| WebRL (prior SOTA) | 38.4% | - |
Taking a 12B open-source model past GPT-4o on a real-world navigation benchmark isn't a marginal improvement. For teams building on open-source foundations, this represents a concrete path to competitive performance without proprietary model costs. The Gemma 3 27B model page gives more context on the model family - the 12B used here is the smaller sibling.
HyEvo: Evolving Your Way to 19x Cheaper
Paper: HyEvo: Self-Evolving Hybrid Agentic Workflows (arXiv:2603.19639) | Beibei Xu, Yutong Ye, Chuyun Shen, Yingbo Zhou, Cheng Chen, Mingsong Chen
Most automated workflow systems treat every step as a LLM call. When you need a loop counter or a regex match, you still route it through the same large model that handles nuanced reasoning. HyEvo treats that as waste.
The core idea is a workflow graph with two node types: LLM nodes for semantic reasoning and code nodes for deterministic execution. Sorting a list, checking a condition, parsing JSON - these go to code nodes. Interpreting ambiguous instructions, synthesizing across sources - those go to LLM nodes. The split sounds obvious once stated, but building it automatically is the hard part.
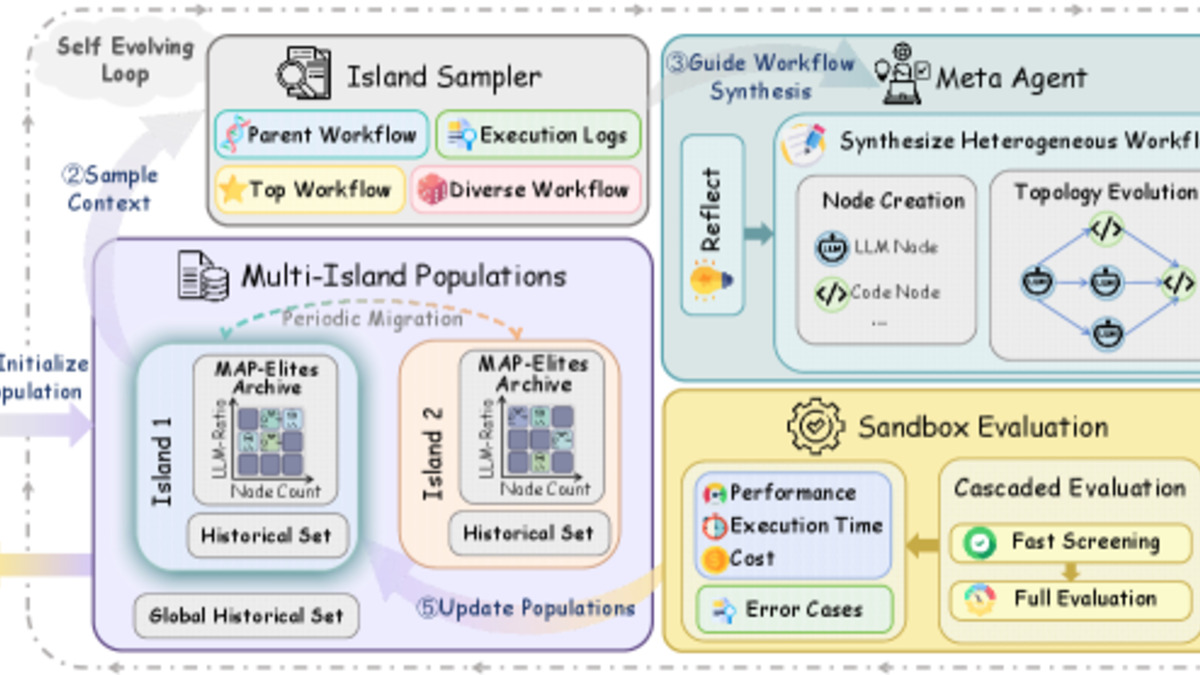 HyEvo's multi-island evolutionary strategy discovers best mixes of LLM and code nodes, then spreads the best patterns across populations.
Source: arxiv.org
HyEvo's multi-island evolutionary strategy discovers best mixes of LLM and code nodes, then spreads the best patterns across populations.
Source: arxiv.org
How the evolution works
HyEvo uses a multi-island evolutionary strategy with a reflect-then-generate mechanism. Each island maintains a population of workflow variants. At fixed intervals, top performers propagate to neighboring islands. Within each island, a meta-agent first reflects on why recent workflows failed, then produces new variants guided by that diagnosis.
The result is that HyEvo doesn't just find good workflows - it finds good workflows that it understands well enough to improve. This matters because ad-hoc search tends to find local optima; the reflect-then-generate loop keeps the search space well-explored.
Results across five benchmarks
| Benchmark | HyEvo | Best Baseline (MaAS) |
|---|---|---|
| GSM8K | 93.36% | 92.30% |
| MATH | 53.91% | 51.82% |
| MultiArith | 99.67% | 98.80% |
| HumanEval | 93.89% | 92.85% |
| MBPP | 83.28% | 82.17% |
HyEvo beats MaAS on all five and averages 84.82% overall, a 2.57% improvement over AFlow. But the headline figure isn't accuracy - it's the 19x inference cost reduction and 16x latency reduction compared to the top open-source baseline. In production, that's the number that determines whether a product ships.
The efficiency gains come directly from offloading predictable operations from LLM inference. If 60% of your workflow steps don't need language understanding, routing them through a 70B model is just burning money. HyEvo finds and exploits that gap automatically.
The Common Thread
These three papers converge on the same idea from different directions: agents fail not because they lack raw capability, but because they lack the right structure around that capability. Hyperagents adds structure to self-improvement. MiRA adds structure to long-horizon planning via milestones. HyEvo adds structure to workflow execution by separating reasoning from computation.
None of them require a bigger model. All three show meaningful gains on existing architectures. For practitioners building real systems, that's the practical takeaway: before scaling compute, check whether you've structured the task correctly.
Sources:

