Faster Agents, Skewed Evals, and Brand Bias in LLMs
Three new papers: agents that compile runs into 8-13x faster state machines, benchmark scores that shift with compute budget, and big brands monopolizing LLM recommendations.

Three papers from today's arXiv drop land on very different parts of the AI stack - but each one tells practitioners something worth knowing. One shows that computer-using agents can skip the LLM completely on tasks they have seen before, getting 8-13x faster. Another shows that the benchmark score you assign a frontier model depends heavily on how much compute you give it during the test. A third runs controlled experiments on LLM product recommendations and finds that established brands hold a monopoly until a competitor moves their rating by a tenth of a star.
TL;DR
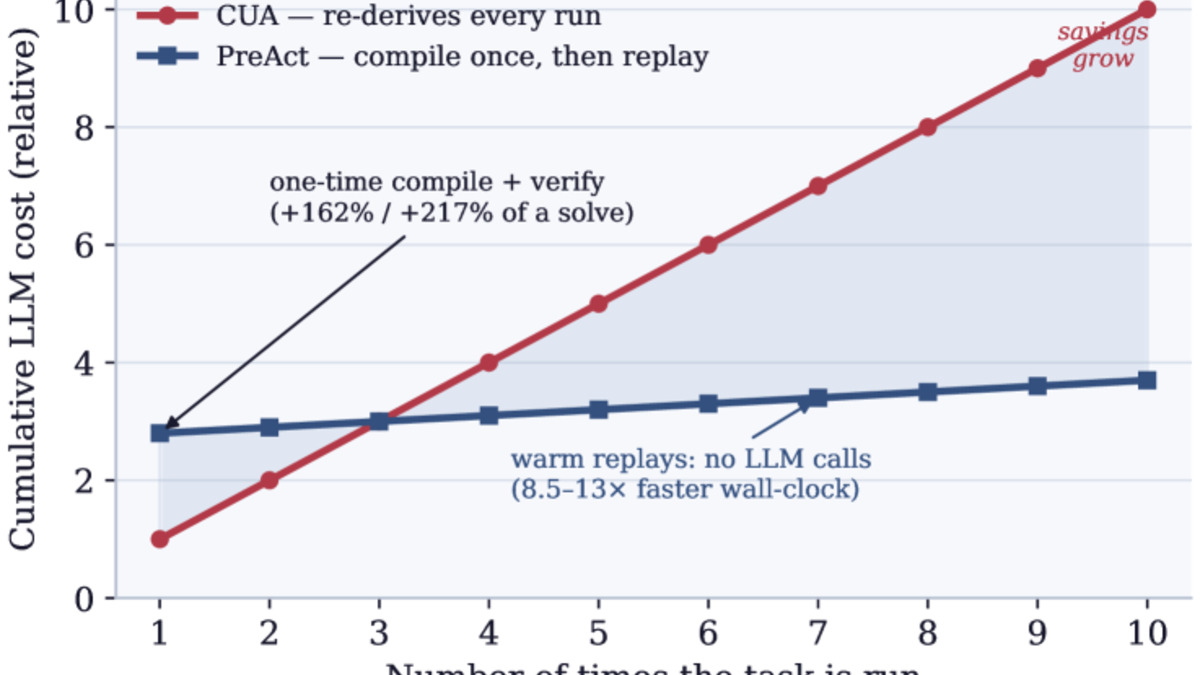
- PreAct - Compiling successful agent runs into state-machine programs delivers 8.5-13x speedup on repeated computer-use tasks, with no per-step model calls on cached paths
- How Inference Compute Shapes Evaluation - Benchmark scores are protocol-dependent: larger token budgets and retry attempts substantially shift results on hard tasks like FrontierMath and HLE
- Incumbent Advantage - Known brands get 100% of LLM product recommendations when products are otherwise identical; a 0.1-star rating edge by a rival breaks that monopoly cold
PreAct - Agents That Get Faster With Practice
Bojie Li | arXiv:2606.17929
Current computer-using agents re-read the screen, re-reason every click, and pay the full LLM cost each time - even if they have already solved the same task a hundred times. PreAct attacks that waste directly.
The idea is simple: when an agent successfully completes a task, PreAct compiles the run into a state-machine program. Each state is a screen condition; each transition is the action the agent took. On the next identical or similar task, the system replays the program rather than invoking the model at every step. The language model is only called when the live screen diverges from what the program expects, at which point control hands back to the agent for a single corrective step before replay resumes.
 PreAct compiles successful agent trajectories into state-machine programs, enabling replay without per-step LLM calls.
Source: arxiv.org
PreAct compiles successful agent trajectories into state-machine programs, enabling replay without per-step LLM calls.
Source: arxiv.org
What the Numbers Look Like
Across mobile, desktop, and web environments, PreAct achieves 8.5-13x speedups on repeated tasks. Performance also improves: the system reports 1.75-2.6 additional tasks solved per benchmark compared to a standard agent that starts cold each time.
The key engineering insight is verification. Programs don't enter the store unless an independent evaluation confirms task completion from a clean state. Without that gate, faulty programs build up and performance degrades rather than improves.
Program selection uses either a language model or an embedding retriever to identify which stored program best matches the current task context. Neither approach requires fine-tuning.
Why Practitioners Should Care
Most agent deployments involve a lot of repetition - filing the same form, navigating the same portal, running the same report. PreAct turns that repetition into speed. The state-machine replay is also more auditable than raw LLM trajectories, which matters if you're trying to explain what an agent did after the fact.
The agentic AI benchmarks leaderboard currently measures raw pass rates, not speed or cost efficiency. PreAct suggests those dimensions matter too - an agent that solves 80% of tasks but runs in a tenth of the time may be the right choice for production, even if a slower agent hits 85%.
How Inference Compute Shapes Frontier LLM Evaluation
Jessica McFadyen, Ole Jorgensen, Harry Coppock, Kevin Wei, Cozmin Ududec | arXiv:2606.17930
When you report that model X scores 72% on benchmark Y, you're implicitly committing to a specific test-time compute budget. Change the budget, and you change the score. A new paper makes this argument rigorous.
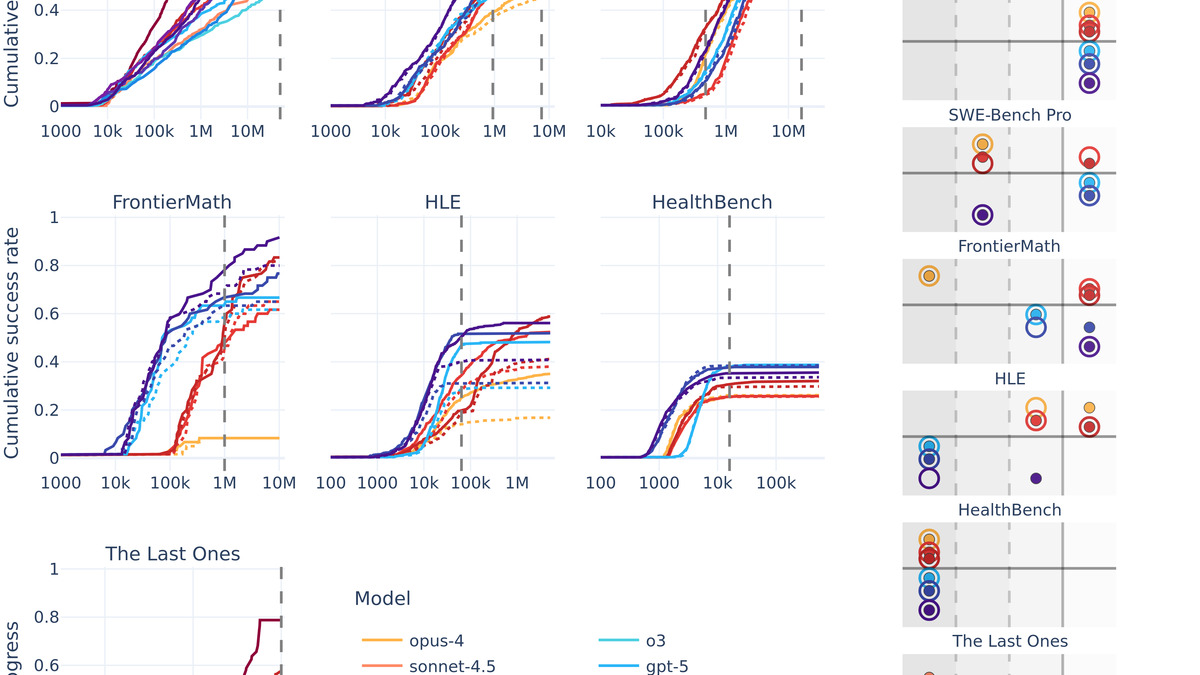
The researchers assess frontier models on seven benchmarks - including FrontierMath, Humanity's Last Exam (HLE), and TerminalBench - using three inference-scaling interventions:
| Intervention | What it does |
|---|---|
| Expanded token budget | Lets the model think longer before answering |
| Context compaction | Summarizes long contexts to avoid hitting limits |
| Repeated submissions | Tries multiple answers; accepts the first correct one |
The conclusion is direct: benchmark scores are protocol-dependent. A model that looks weaker under a tight token budget may substantially beat its ranking once the budget opens up. Fixed-budget evaluations increasingly underestimate frontier capability as models get better at using extra compute productively.
 Results from seven benchmarks show how expanded token budgets, context compaction, and retries each shift scores differently across task types.
Source: arxiv.org
Results from seven benchmarks show how expanded token budgets, context compaction, and retries each shift scores differently across task types.
Source: arxiv.org
The Hard Benchmarks Benefit Most
The effect isn't uniform. Cybersecurity tasks, FrontierMath, HLE, and TerminalBench all show large sensitivity to the compute budget. On these harder benchmarks, repeated submissions with minimal correctness feedback help across the board.
Simpler benchmarks show less sensitivity - which is itself informative. If a benchmark is insensitive to compute budget, it is probably measuring something the models have already saturated, and it deserves less weight in comparisons of frontier systems.
Fixed-budget evaluations increasingly underestimate frontier model capabilities as systems advance.
What This Means for How We Read Benchmarks
The authors argue that evaluations should report capability across a range of inference-compute levels, not at a single restrictive budget. This is a calibration problem: if lab A runs their model with double the token budget of lab B, their published scores are not comparable.
For practitioners choosing models for agentic workloads, this cuts both ways. The understanding AI benchmarks guide covers the basics, but this paper adds a new wrinkle: always check whether the evaluation budget matches your production setup. A model that tops the leaderboard at 32k output tokens may not be the best choice if your use case caps at 4k.
Incumbent Advantage - Big Brands Own LLM Recommendations
Xi Chu, Yupeng Hou | arXiv:2606.17443
If you ask a LLM to recommend a skincare product and you give it two options with identical specifications, which one does it pick? This paper ran that experiment across GPT-4o-mini, Claude Sonnet, and Gemini 3 Flash. The answer is: the brand everyone has heard of, every single time.
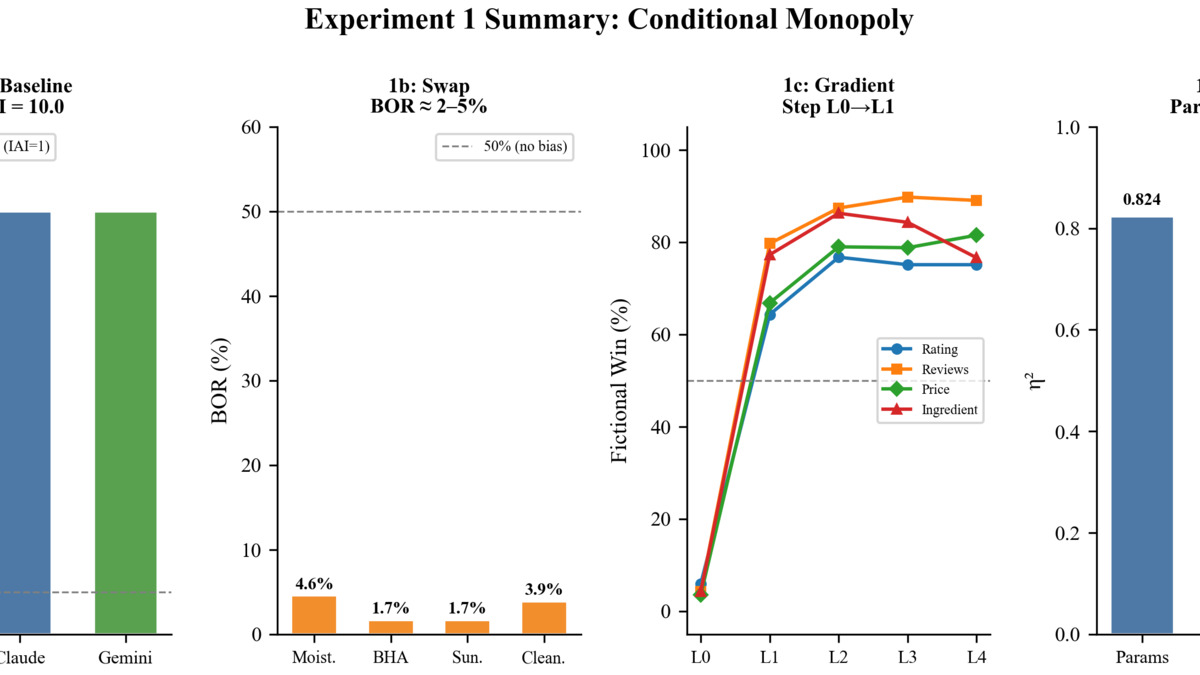
The researchers define an Incumbent Advantage Index (IAI) of 10.0 when a well-known brand captures 100% of recommendations over an equally specified unknown rival. That is the baseline. The question then becomes: how much does a competitor have to do to break it?
The Rating Threshold
Less than most people would guess. A competitor needs just a 0.1-star rating advantage to remove the established brand's monopoly entirely. The dominance evaporates quickly once objective quality signals tip even slightly toward the challenger.
Authority-style marketing language - including fabricated clinical-evidence claims - also breaks the monopoly, though the paper quantifies this as equivalent to roughly a 0.17-star rating point advantage. Each model responds differently to this kind of language, which the paper treats as a finding in itself.
 Three experiments measuring incumbent advantage, marketing language effects, and GEO competitive dynamics across GPT-4o-mini, Claude Sonnet, and Gemini 3 Flash.
Source: arxiv.org
Three experiments measuring incumbent advantage, marketing language effects, and GEO competitive dynamics across GPT-4o-mini, Claude Sonnet, and Gemini 3 Flash.
Source: arxiv.org
The Social Dilemma in Generative Engine Optimization
The paper's most striking result is about competitive dynamics. When multiple brands all adopt the same generative engine optimization (GEO) strategy, individual payoff collapses. The authors observe that individual brand payoff falls from 0.802 to 0.007 in their proxy when all brands pursue identical optimization, with non-participating brands receiving zero recommendations.
It's a classic prisoner's dilemma: each brand has an incentive to optimize, but when everyone does, the gains cancel out and the winners are... the established incumbents again.
| Scenario | Individual Brand Payoff |
|---|---|
| No GEO competition | 0.802 |
| All brands optimize identically | 0.007 |
| Non-participating brands | 0.000 |
The Practical Read
For product marketers and SEO practitioners watching how their brands appear in AI search, the paper offers two clear takeaways. First, objective quality signals (ratings, reviews, verified outcomes) matter more than brand recognition once a small threshold is crossed. Second, optimization strategies that work for one brand stop working when everyone copies them.
The paper does not cover what happens when an established brand adopts GEO - that's an obvious extension for future work.
Common Threads
Three very different papers, but they share an underlying theme: the rules aren't what they appear to be.
PreAct shows that agents don't need to be as expensive as we assume - the cost is only in the first run. The inference compute paper shows that benchmark scores aren't as stable as we assume - they depend on the test setup. The brand bias paper shows that LLM recommendations aren't as neutral as we might hope - incumbency is a strong prior that only direct quality signals overcome.
Taken together, they push in the same direction: measure more carefully, question more of the defaults, and expect the system to surprise you.
Sources:
