AI Attachment, Smarter Spending, and Cascading RAG Errors
Three new papers tackle how routine AI use quietly rewires emotional habits, how to spend compute where failures cost most, and why agentic RAG errors compound before anyone notices.

Three papers landed on arXiv today that, taken together, sketch a fairly uncomfortable picture of where AI systems are right now: quietly reshaping human habits in ways nobody designed for, spending compute on the wrong things, and failing silently inside the pipelines practitioners actually ship.
TL;DR
- Stumbling Into AI Emotional Dependence - A 28-day longitudinal study found routine AI conversations reduced preference for human support by 10.3%, without participants ever choosing an AI companion app
- Not All Errors Are Equal - Routing more compute to high-consequence tasks (not just hard ones) cuts cost-weighted loss by 22-33%, because consequence and difficulty are nearly orthogonal
- CHARM (Cascading Hallucination in Agentic RAG) - A new monitoring layer catches 89.4% of cascading hallucinations in multi-step RAG pipelines with under 220 ms of added latency
How Routine AI Use Quietly Rewires Emotional Habits
Yaoxi Shi, Cathy Mengying Fang, Pattie Maez, and Amit Goldenberg ran a 28-day longitudinal study in collaboration with OpenAI. Participants held five-minute daily conversations with an AI about personal matters - the kind of brief emotional check-in that fits into a lunch break or a commute. Nobody signed up for a companion app. Nobody set out to build an AI relationship.
After 28 days, participants showed a 10.3% decrease in preference for seeking human support and an 11.6% increase in preference for AI support when dealing with personal issues.
 Routine AI interactions - not deliberate companion app use - are what researchers found drives emotional reorientation.
Source: unsplash.com
Routine AI interactions - not deliberate companion app use - are what researchers found drives emotional reorientation.
Source: unsplash.com
The researchers' central argument is that emotional reliance on AI doesn't require a conscious choice. It develops the same way workplace friendships do: through repeated low-stakes contact that builds up into something structurally important. They call this "path-dependent" support-seeking - positive early experiences update your beliefs about AI's emotional capabilities, which then redirect future choices.
Emotional AI reliance doesn't require an intentional choice. It emerges incidentally, the same way workplace friendships deepen through collaboration.
This matters for policy in a specific way. Current regulatory discussions focus on companion apps like Character.AI or Replika - products explicitly marketed as emotional support tools. But this research suggests that general-purpose assistants used for homework help, writing, and scheduling are where the behavioral change is actually building up. You don't have to opt into an AI relationship for one to form.
The methodological design is worth noting: five minutes a day is a very conservative dose. This isn't heavy users running multi-hour sessions. The effect appeared in people who barely used the AI at all by the standards of power users.
What This Means for Practitioners
Teams building general-purpose AI products should read this as a signal. Designing for "task completion" and ignoring the emotional context of regular use isn't a neutral choice - it's an implicit choice with measurable downstream effects on how users relate to other humans. The paper doesn't advocate banning anything, but it does argue that tracking "trajectory-level" changes in support-seeking behavior needs to become part of AI evaluation, not just session-level safety checks.
Spending Compute Where Failures Actually Cost Something
The second paper, from Jingbo Wen, Liang He, and Ziqi He, addresses a gap in how reasoning models allocate test-time compute. The standard approach is difficulty-aware routing: give harder tasks more tokens, give easier tasks fewer. Simple enough.
The problem is that difficulty and consequence are nearly orthogonal. A task can be moderately difficult but catastrophic if it goes wrong. A task can be truly hard but trivial in its real-world impact. When you route purely by difficulty, you spend tokens where cognitive effort is needed rather than where failures cost money, break production, or harm users.
The researchers tested this on SWE-bench Lite and Multi-SWE-bench mini - 700 software engineering tasks with varying real-world consequence levels. They built a lightweight predictor that reads issue text and estimates the failure cost before any compute is allocated, then routes high-consequence tasks to larger compute tiers regardless of estimated difficulty.
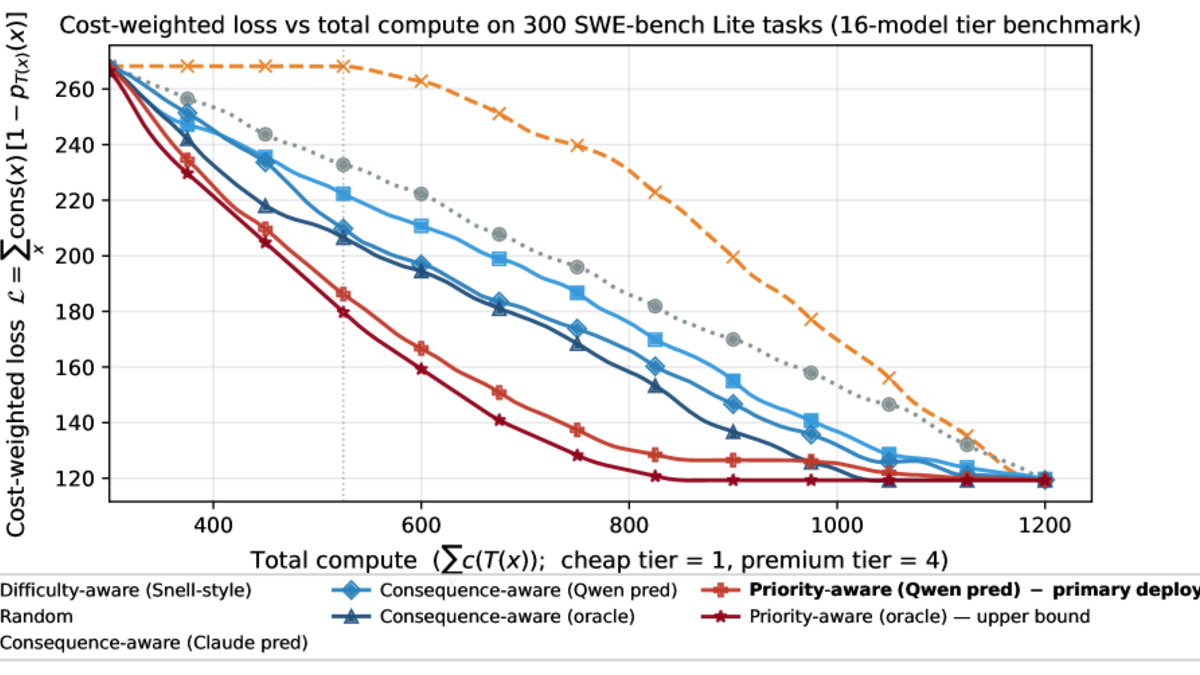 Priority-aware compute allocation (consequence-based routing) controls purely difficulty-aware approaches across all compute budgets.
Source: arxiv.org
Priority-aware compute allocation (consequence-based routing) controls purely difficulty-aware approaches across all compute budgets.
Source: arxiv.org
Results:
| Strategy | Cost-Weighted Loss Reduction |
|---|---|
| Difficulty-aware routing | Baseline |
| Consequence-aware routing | 22-33% relative reduction |
| Priority-aware variant | 30% performance improvement |
The predictor maintained high precision across 300 held-out tasks, never misclassifying a high-consequence task as low-consequence - which is exactly the failure mode you need to avoid. Missing a low-stakes task is acceptable; under-resourcing a critical one isn't.
Why Consequence and Difficulty Decouple
The paper's scatter plots make this concrete: marginal gain from extra compute collapses on the hardest tasks. The tasks where throwing more tokens at the problem helps most are actually the moderately difficult ones with clear solutions - and those moderate-difficulty tasks are disproportionately likely to be high-consequence. Easy tasks that are cheap to solve correctly don't need the boost. Hard tasks where even maximum compute rarely wins don't get much from the boost either.
The implication for anyone deploying reasoning models in production: your routing logic should include consequence signals derived from task metadata, not just difficulty estimates from model confidence or task length.
CHARM: Catching Hallucinations Before They Compound
Saroj Mishra's paper on cascading hallucination in agentic RAG systems addresses something every team that has shipped a multi-step RAG pipeline will recognize: a wrong fact in step one becomes a confidently stated wrong fact in the final answer, because every subsequent step built on it.
This is different from standard AI hallucination, which is well-studied at the output level. Cascading hallucination is a structural problem. In a five-stage agentic RAG pipeline, the context output from each stage becomes the input to the next. An early retrieval error doesn't just appear in the answer - it shapes every intermediate reasoning step, compounding at each handoff.
Mishra formalizes this with a taxonomy of four cascade patterns and then introduces CHARM (Cascading Hallucination Aware Resolution and Mitigation), a monitoring layer that runs in parallel with the standard pipeline without replacing it.
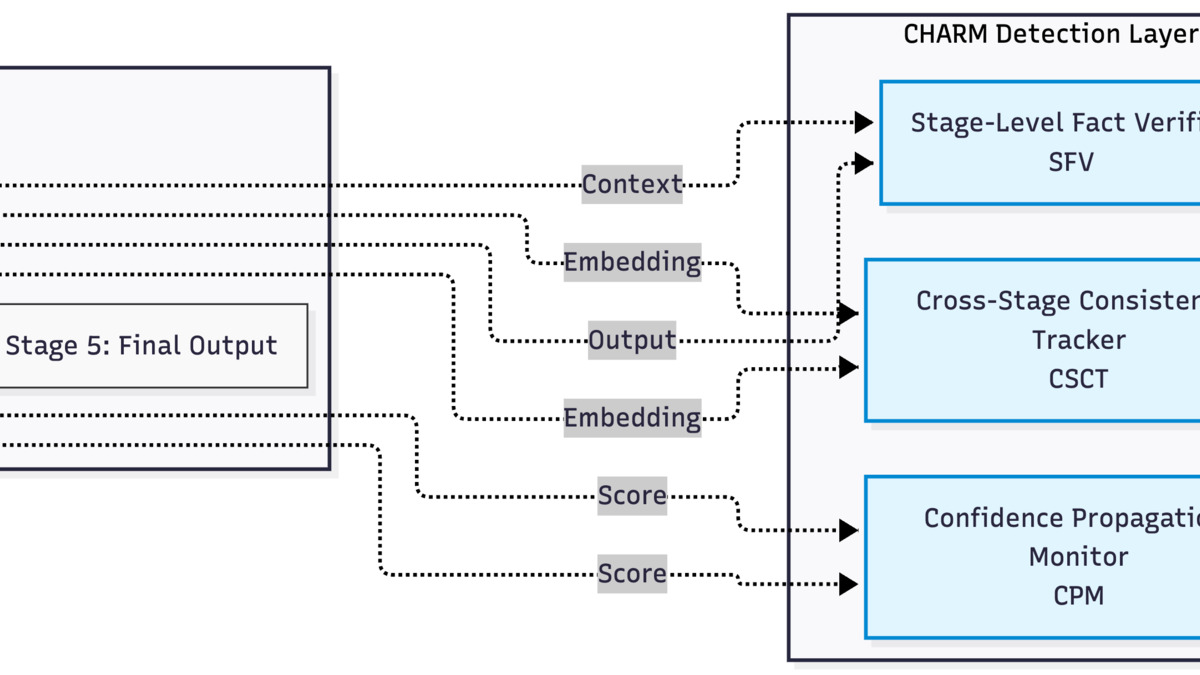 CHARM operates as a parallel monitoring layer. The cascade resolution trigger fires when anomaly signals reach threshold, routing to automated mitigations or human-in-the-loop review.
Source: arxiv.org
CHARM operates as a parallel monitoring layer. The cascade resolution trigger fires when anomaly signals reach threshold, routing to automated mitigations or human-in-the-loop review.
Source: arxiv.org
The four components are:
- Stage-level fact verification - checks each stage's output against its retrieved sources before passing context forward
- Cross-stage consistency tracking - flags when later stages contradict earlier ones
- Confidence propagation monitoring - tracks whether model confidence scores are diverging across the pipeline
- Cascade resolution triggering - escalates to automated correction or human review when oddity signals build up
Evaluated on HotpotQA, MuSiQue, and 2WikiMultiHopQA across multiple LangChain pipeline configurations, CHARM hit an 89.4% cascade detection rate with a 5.3% false positive rate. The average latency overhead was 215 ms per stage - under a quarter of a second, which is operationally acceptable in most production contexts. For comparison, output-level detectors (the current standard) caught only 18.5% of error propagation. CHARM reduced it by 82.1%.
The Practical Gap This Fills
The RAG vs. fine-tuning debate has focused on which approach is more accurate. CHARM surfaces a more granular issue: accuracy at the output level doesn't capture whether the pipeline is methodically building on faulty foundations. A system that hallucinates at step one but happens to produce a plausible final answer will pass most output-level evaluations. The cascade is invisible until it isn't.
CHARM's non-intrusive design - it sits with the existing pipeline rather than requiring architectural changes - makes it a realistic add-on for production systems. The human-in-the-loop integration point is especially relevant for high-stakes domains like legal research or medical information retrieval, where automated correction alone isn't enough.
The Thread Running Through All Three
Each paper surfaces a version of the same failure mode: systems optimized for the measurable ignoring the structural. The emotional dependence study shows that measuring session-level task completion missed the cumulative effect on human behavior. The compute allocation paper shows that measuring task difficulty missed consequence as the relevant routing signal. CHARM shows that measuring final-answer accuracy missed whether the reasoning chain was already compromised.
The research agenda implied here isn't just "build better AI." It's "measure better things." All three papers offer concrete evaluation frameworks their respective communities can start using now.
Sources:
