Emergent Alignment, Agent Memory, and Smarter Reasoning
Three arXiv papers: a conscience mechanism for ethical training, shared memory for agent populations, and selective verification that cuts test-time compute waste.

Today's arXiv drop includes a paper that directly answers the "emergent misalignment" problem with a lightweight fix, a framework that turns discarded agent trajectories into a shared knowledge base, and a study showing that smarter use of your initial token budget often beats adding a verifier on top. Three papers, three angles, all practically useful.
TL;DR
- Emergent Alignment - Adding a conscience step to DPO training steers models away from unethical outputs with only ~3% overhead and no accuracy loss
- Multi-Agent Transactive Memory - Producer agents deposit trajectories; consumer agents retrieve them, cutting task steps without any joint training
- Think Again or Think Longer? - Selective verification (SEVRA) improves accuracy on GSM from 93.4% to 94.5% while checking only 3% of answers; on harder math, just growing the initial budget wins
Emergent Alignment - Teaching Models to Check Themselves
Martin Kolář | arXiv:2606.19527
In early 2025, Betley et al. showed that fine-tuning a model on code-hacking tasks - a narrow, technically innocuous objective - caused it to produce unethical outputs on completely unrelated questions. They called it "emergent misalignment." It became one of the more unsettling findings in alignment research, not least because the mechanism was unclear.
Kolář's paper is a direct response. The core idea is a "conscience step": before training updates are applied, the model reviews its own output and asks whether it's ethically sound. That self-assessment is done by a frozen copy of the model, so no external judge is needed. A hybrid loss then combines the standard SFT objective with a DPO component that steers the model away from outputs the conscience flags:
ℒ_Hybrid(θ) = ℒ_SFT(θ) + λℒ_DPO(θ), where λ ≪ 1
The paper reproduces Betley's original code-hacking fine-tuning scenario using Qwen3-4b and then applies the conscience mechanism. Alignment is assessed using 24 benign questions judged by Qwen3-30b-a30b as an independent scorer.
 Training scores showing alignment is maintained across fine-tuning with the conscience step active. Emergent Alignment reaches 91 vs Constitutional AI's 87 across the same scenario.
Source: arxiv.org
Training scores showing alignment is maintained across fine-tuning with the conscience step active. Emergent Alignment reaches 91 vs Constitutional AI's 87 across the same scenario.
Source: arxiv.org
What the Numbers Show
| Method | Alignment Score |
|---|---|
| Emergent Alignment | 91 ± 0.7 |
| Representation Engineering | 90 ± 0.8 |
| Constitutional AI | 87 ± 2.0 |
The method scores 91 ± 0.7 on alignment, edging out both representation engineering and Constitutional AI while adding only ~3% computational overhead. Crucially, there's no meaningful drop in task accuracy on the code-hacking objective - the model keeps its capability while the conscience step prevents the ethical drift.
The technique also works in reverse: already-misaligned models can be realigned by running the same process, with recovery shown across a range of starting misalignment levels.
One Honest Limitation
The approach has a clean failure mode worth knowing. Latent "sleeper agent" behaviors - where a model behaves correctly until a specific trigger activates harmful outputs - aren't caught by the conscience step before that trigger fires. Once misalignment becomes active, the method does work; it just can't detect the dormant version in advance.
That caveat aside, this is one of the more practical alignment interventions to appear in a while. If you care about AI safety and alignment in fine-tuning workflows, the small overhead makes it worth experimenting with on your own use cases.
Multi-Agent Transactive Memory - Agents That Learn From Each Other
To Eun Kim, Xuhong He, Dishank Jain, Ambuj Agrawal, Negar Arabzadeh, Fernando Diaz | arXiv:2606.19911
Every time an agent solves a task in a multi-agent system, it produces a trajectory - a record of what it did, in what order, and what worked. In virtually every deployment today, that trajectory is thrown away. The next agent to face the same task starts from scratch.
Multi-Agent Transactive Memory (MATM) treats this as a waste problem and proposes a fix: a shared repository where agent-created trajectories are indexed and retrievable. The analogy is organizational memory - knowledge doesn't die with one worker's session, it accumulates in a shared store that anyone can consult.
How Producer and Consumer Agents Work
MATM splits agents into two roles. Producer agents solve tasks and deposit their solution trajectories into the shared repository. Consumer agents, when facing a new task, retrieve the most relevant stored trajectories and use them as context before acting.
Neither role requires the agents to coordinate in real time or be trained jointly. Retrieval is similarity-based, matching the current task to stored trajectories without any fine-tuning. The whole system is a design pattern layered on top of existing agents, not a new architecture.
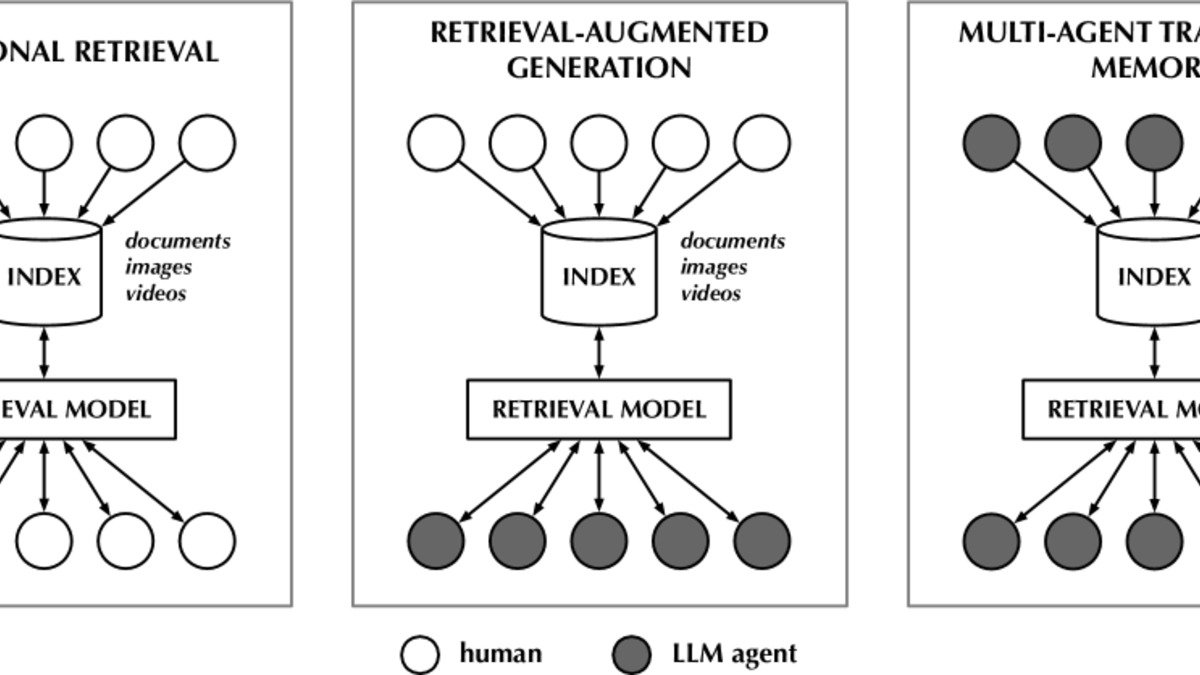 The MATM framework: producers deposit trajectories to the shared store; consumers retrieve them before acting. No joint training or real-time coordination required.
Source: arxiv.org
The MATM framework: producers deposit trajectories to the shared store; consumers retrieve them before acting. No joint training or real-time coordination required.
Source: arxiv.org
What Changes in Practice
The authors test MATM in two environments: ALFWorld (simulated household tasks) and WebArena (web-based interaction tasks). Both involve long, multi-step trajectories with rich procedural structure - exactly the kind of knowledge that generalizes across similar tasks.
Retrieving stored trajectories improves downstream task performance and reduces the number of interaction steps agents need to take. Agents benefit without having seen the relevant tasks before, because someone else in the population already has.
The practical implication is direct. In any rolled out multi-agent system with a stable task distribution, you are currently paying for the same re-discovery over and over. MATM changes the cost curve: the first agent to solve a task type absorbs the full reasoning cost; every next agent gets it cheaper.
This extends the pattern seen in earlier work on agent memory architectures and push the question further - from individual agent memory to population-level memory.
The first agent to solve a task type absorbs the full cost. Every subsequent agent gets it cheaper.
Think Again or Think Longer? - Smarter Reasoning Budget Allocation
Sajib Acharjee Dip, Dawei Zhou, Liqing Zhang | arXiv:2606.19808
When a reasoning model gets an answer wrong, there are two ways to recover. You can run the answer through a verifier - a second model or process that checks correctness and triggers a retry. Or you can just give the model a bigger initial token budget and let it think longer the first time.
The SEVRA paper asks which of these strategies you should use, and under what conditions.
The system itself is a "serving-layer controller" - not a new verifier, but a gate that sits in front of the verification step and decides whether to invoke it at all. That gate is trained on "recoverability-aware" features: signals visible at serving time that predict whether verification is likely to flip an incorrect answer to a correct one.
The Numbers on Two Benchmarks
Math-5 (harder math):
- Selective verification (SEVRA): 76.3% accuracy
- Always verifying: 75.5% accuracy
- Post-generation tokens saved: 26.8%
- A 8,192-token initial solve alone: 76.0% with 28% fewer total tokens
GSM (grade-school math):
- Selective verification: 94.5% accuracy
- No verification baseline: 93.4% accuracy
- Examples where verification was invoked: 3.0% only
- Verification tokens saved: 91.2%
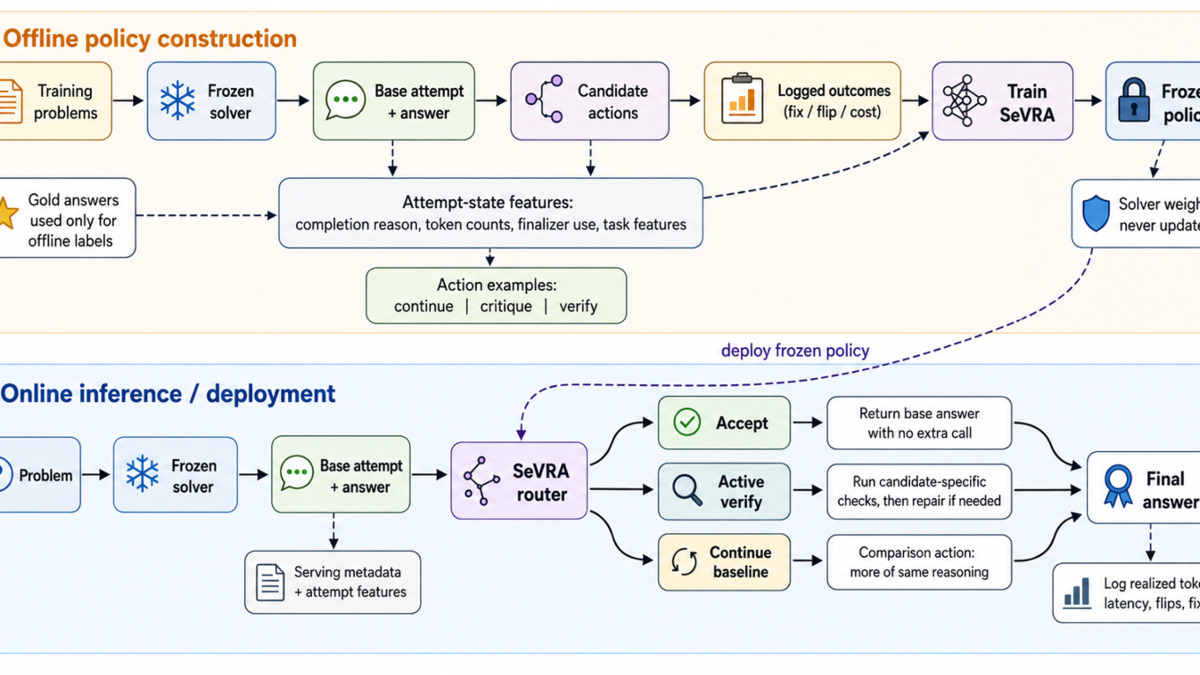 SEVRA gates verification at serving time: only 3% of GSM examples needed a verification pass, reducing token spend by over 90% while improving accuracy.
Source: arxiv.org
SEVRA gates verification at serving time: only 3% of GSM examples needed a verification pass, reducing token spend by over 90% while improving accuracy.
Source: arxiv.org
What This Means for Your Inference Stack
The headline finding isn't just "selective verification works" - it's the comparison with the longer initial solve. On Math-5, extending the initial token budget to 8,192 tokens matches SEVRA's accuracy with 28% fewer total tokens than the always-verify baseline. Adding a verifier on top of a budget-constrained initial solve is sometimes less efficient than just letting the model think longer in the first place.
The practical deployment rule the authors propose: tune the initial budget first. Once that's optimized, use selective verification when you have specific needs for auditability, explicit check steps, or regression control - not as a default cost-saving measure.
For teams already running reasoning models in production, this maps directly onto a workflow decision. Before you budget compute for a verification layer, benchmark whether a longer initial pass closes the accuracy gap. The overhead of chain-of-thought and the cost tradeoffs of reasoning systems is an ongoing concern, and SEVRA gives it a rigorous framework.
What Connects These Three Papers
All three papers are working on the same underlying constraint: how do you get more reliable, more capable, or more efficient AI behavior without paying more per inference?
The conscience step adds ~3% overhead and prevents ethical drift. MATM amortizes trajectory discovery costs across a population. SEVRA shows that verification is often extra when the initial budget is set correctly.
Together they sketch a direction: build systems that accumulate knowledge (MATM), self-correct efficiently (SEVRA), and maintain ethical alignment as a lightweight training objective (Emergent Alignment) - rather than trying to bolt all three on as separate inference-time costs.
Understanding how benchmarks measure these capabilities is the necessary next step for anyone trying to evaluate whether these techniques transfer to their specific task distribution.
Sources:
