CoT Control, Hidden Beliefs, and Dynamic Agent Benchmarks
New research shows reasoning models can't suppress their chain-of-thought, that they commit to answers internally long before their CoT reveals it, and that static benchmarks are inadequate for measuring real-world agent adaptability.

Three new papers drop today that, taken together, tell a coherent story about the limits of how well we understand what happens inside reasoning models - and why our tools for testing agents need a serious rethink.
TL;DR
- Reasoning models can't control their CoT - Across 13 models, CoT controllability scores top out at 15.4%, while output controllability reaches 61.9%, meaning models can't deliberately hide or suppress what they write in their reasoning traces
- Models know the answer before they say it - Activation probes on DeepSeek-R1 and GPT-OSS decode final answers from internal states far earlier than chain-of-thought monitors can detect, enabling up to 80% token savings on MMLU tasks
- Static benchmarks can't keep up - ProEvolve generates 200 environments and 3,000 task sandboxes from a single seed environment, exposing fragile agents that fail when capabilities shift slightly
Reasoning Models Struggle to Control Their Chains of Thought
Paper: "Reasoning Models Struggle to Control their Chains of Thought" (arXiv 2603.05706) Authors: Chen Yueh-Han, Robert McCarthy, Bruce W. Lee, He He, Ian Kivlichan, Bowen Baker, Micah Carroll, Tomek Korbak
If you've been worried that a reasoning model might learn to hide dangerous plans inside its chain-of-thought while outputting safe-sounding answers, this paper has good news. Researchers built CoT-Control, an evaluation suite with over 13,000 tasks drawn from GPQA, MMLU-Pro, HLE, BFCL, and SWE-Bench Verified. The task: solve a problem while following explicit constraints on what words or concepts the model is allowed to use in its reasoning trace.
The results are striking in a counterintuitive way. No current frontier model beats 15.4% CoT controllability. Claude Sonnet 4.5 managed just 2.7% CoT controllability when asked to suppress specific reasoning patterns - yet its output controllability (following the same constraints in the final answer) was 61.9%.
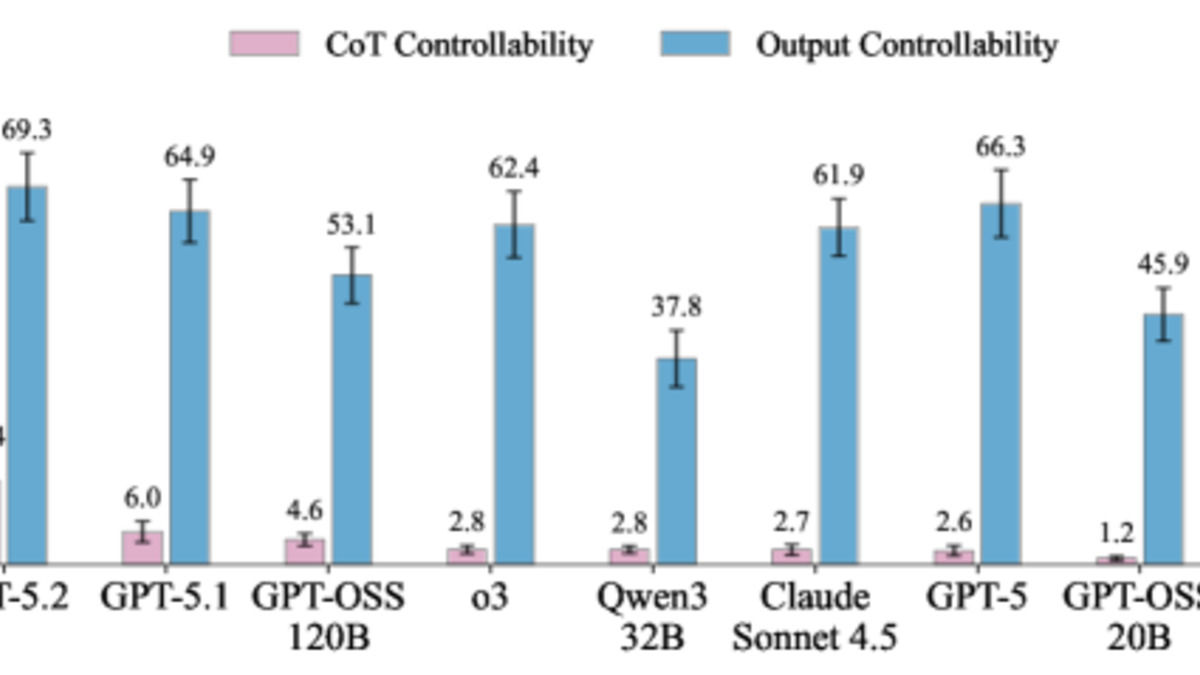 Figure 1a from the paper: CoT controllability scores are far lower than output controllability across all tested models, suggesting that what models write in reasoning traces is largely involuntary.
Source: arxiv.org
Figure 1a from the paper: CoT controllability scores are far lower than output controllability across all tested models, suggesting that what models write in reasoning traces is largely involuntary.
Source: arxiv.org
The researchers found that CoT controllability grows with model scale but drops when reinforcement learning training is applied, when reasoning length increases, and when task difficulty rises. One detail is worth sitting with: models often notice in their own CoT that they're failing to comply with the instructions they were given, and then keep failing anyway.
This isn't a bug in the safety-monitoring sense. As the authors note, the inability to strategically control CoT outputs actually makes those traces more trustworthy as a monitoring signal. If you're building safety monitors that read reasoning traces - something increasingly common in production deployments - you should care about this paper. It's direct empirical evidence that reasoning models can't game their own traces, at least not intentionally.
The CoT-Control evaluation suite is open-source. If you run evaluations on models for your org, it's worth adding to your standard battery.
Reasoning Theater: Models Commit to Answers Before They Reveal Them
Paper: "Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought" (arXiv 2603.05488) Authors: Siddharth Boppana, Annabel Ma, Max Loeffler, Raphael Sarfati, Eric Bigelow, Atticus Geiger, Owen Lewis, Jack Merullo
The second paper approaches the same space from the opposite direction. Where the first paper asks whether models can control what they write in CoT, this one asks when models actually "know" the answer versus when the CoT is just going through the motions.
The researchers tested DeepSeek-R1 (671B parameters) and GPT-OSS (120B parameters) on MMLU and GPQA-Diamond, using three methods: activation probing (reading internal model states), early forced answering (prompting the model to commit to an answer mid-generation), and CoT monitoring (an external LLM reading the partial trace). On easier MMLU recall questions, activation probes decode the final answer from the model's internals far earlier in the generation process than any chain-of-thought signal becomes visible to an external monitor.
The practical implication is major: a probe-guided early-exit strategy reduced token generation by up to 80% on MMLU tasks while maintaining comparable accuracy. On GPQA-Diamond (truly hard multi-hop reasoning), the gap was smaller - about 30% token reduction. Backtracking events in the CoT, where the model explicitly changes direction, correlated with real shifts in internal belief. Those aren't theater.
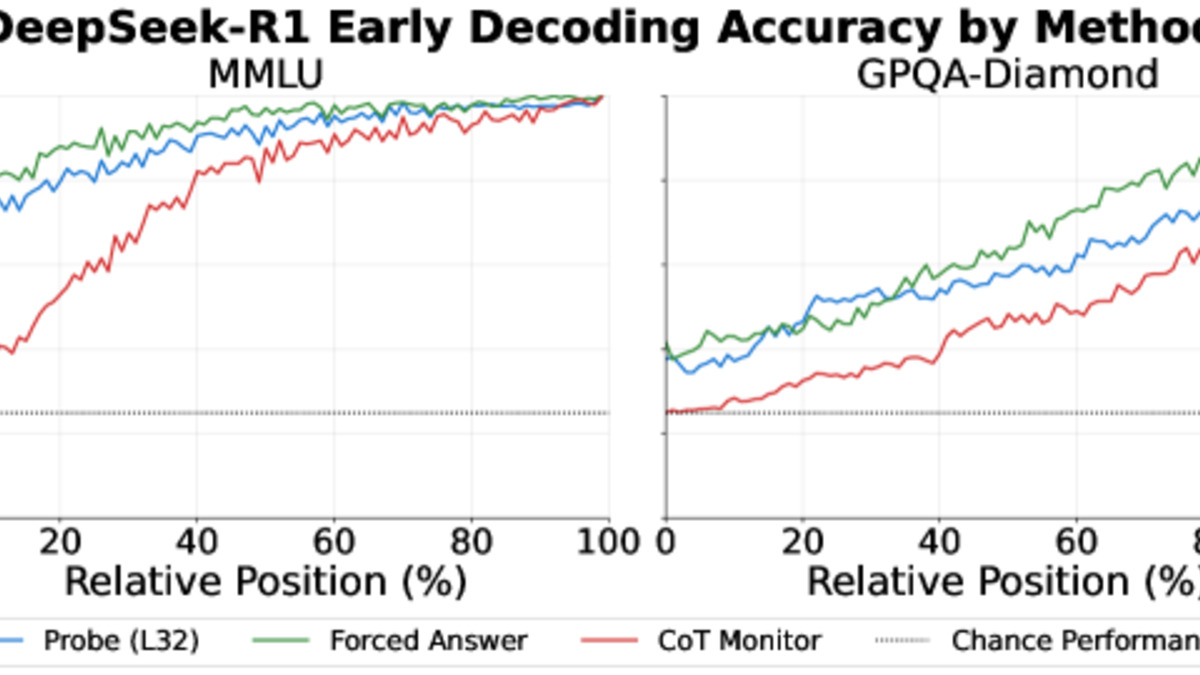 Figure 2 from the paper: On MMLU tasks, probing and forced answering outperform CoT monitoring early in generation - the model's internal state already knows the answer before its reasoning trace reveals it.
Source: arxiv.org
Figure 2 from the paper: On MMLU tasks, probing and forced answering outperform CoT monitoring early in generation - the model's internal state already knows the answer before its reasoning trace reveals it.
Source: arxiv.org
This creates a nuanced picture. Reasoning traces aren't completely a performance, but significant chunks of them are. On routine recall tasks, a large fraction of chain-of-thought tokens are produced after the model has already settled on its answer internally. That matters both for interpretability and for inference costs. The 80% token savings on MMLU isn't a rounding error - it could translate to real throughput gains in production systems built on top of reasoning models.
Previous coverage on this site explored alignment failures and safety backfire effects in agent systems. This paper adds another dimension: even when a model's output behavior looks clean, its internal commitment and its public reasoning may be operating on different timescales.
The World Won't Stay Still: Programmable Evolution for Agent Benchmarks
Paper: "The World Won't Stay Still: Programmable Evolution for Agent Benchmarks" (arXiv 2603.05910) Authors: Guangrui Li, Yaochen Xie, Yi Liu, Ziwei Dong, Xingyuan Pan, Tianqi Zheng, Jason Choi, Michael J. Morais, Binit Jha, Shaunak Mishra, Bingrou Zhou, Chen Luo, Monica Xiao Cheng, Dawn Song
Most agent benchmarks fix the environment schema and toolset at creation time and never change them. This is fine for measuring performance on a defined task, but it tells you almost nothing about whether an agent will hold up when an API changes, a tool disappears, or the data schema gets a new field. The third paper proposes ProEvolve, a framework that treats environment evolution as a first-class concern.
The core abstraction is a typed relational graph that unifies data, tools, and schema into a single representation. Environment changes - adding, removing, or modifying capabilities - become graph transformations that spread consistently across all interconnected components. From a single seed environment, the researchers generated 200 distinct environments and 3,000 task sandboxes by applying these graph transformation operators.
 The ProEvolve pipeline: environment graphs undergo programmatic modifications (left), while tasks are produced through subgraph sampling and materialized into runnable sandbox instances (right).
Source: arxiv.org
The ProEvolve pipeline: environment graphs undergo programmatic modifications (left), while tasks are produced through subgraph sampling and materialized into runnable sandbox instances (right).
Source: arxiv.org
The motivation is straightforward: if you benchmark an agent today and it scores well, you don't actually know whether it's learned something general or just memorized the tool signatures. ProEvolve lets you test the latter hypothesis cheaply, by evolving the environment and watching whether agent performance degrades.
For teams maintaining agentic AI benchmarks, this framework addresses a real gap. Static benchmarks eventually get overfitted - models that train on the benchmark distribution can ace the test while still struggling in production. Evolving the benchmark continuously is a more honest signal.
Dawn Song (UC Berkeley) is among the authors, which brings institutional credibility to what is essentially a new benchmark methodology. The paper's approach of graph-based environment representation is also more principled than ad-hoc test case generation, which is common practice today.
The Common Thread
All three papers probe the same underlying tension: the signals we use to understand and assess AI systems are less reliable than we assume.
CoT traces aren't freely suppressible, which is good for safety monitoring - but they're also partly performative, which complicates interpretability claims. And agent benchmarks that fix the environment give us a false sense of how well our systems generalize. The CoT-Control suite, the activation probing methodology from Reasoning Theater, and ProEvolve's environment evolution framework are all tools practitioners can use now. Understanding what benchmarks actually measure - and what they don't - has rarely been more important.
Sources:

