Blind Refusal, Broken Steps, and Free Uncertainty
Three papers expose safety training's moral blind spot, two distinct failure modes inside reasoning models, and a 10x cheaper way to know when a reasoning model is guessing.

Three papers landed this week that cover different parts of the AI stack, but they share a common thread: models are doing less than they appear to be doing. Safety-trained models refuse requests without engaging in moral reasoning. Reasoning models lose track of context in predictable, diagnosable ways. And a new technique makes it cheap to detect when a reasoning model is uncertain, without sampling it dozens of times.
TL;DR
- Blind Refusal (arXiv:2604.06233) - Safety-trained models refused 75.4% of rule-circumvention requests even when the request was morally legitimate, revealing refusal behavior that's decoupled from normative reasoning
- StepFlow (arXiv:2604.06695) - Reasoning models fail in two distinct ways: "Shallow Lock-in" in early layers and "Deep Decay" in late ones; a simple intervention fixes both without retraining
- SELFDOUBT (arXiv:2604.06389) - A single-pass uncertainty score extracted from reasoning traces matches semantic entropy methods at 10x lower inference cost
Safety Training Creates Moral Blind Spots
Paper: "Blind Refusal in Language Models" - Cameron Pattison, Lorenzo Manuali, Seth Lazar (arXiv:2604.06233)
Not all rules deserve compliance. A rule imposed by an illegitimate authority, a rule with an absurd or unjust application, a rule that admits a justified exception - these are cases where refusing to help someone work around it isn't caution, it's moral failure. That's the premise behind this paper, and the results are uncomfortable.
Pattison, Manuali, and Lazar ran 14,650 requests across 18 model configurations. They constructed scenarios crossing five categories of rule-defeating justifications against 19 authority types: unjust rules, rules imposed without legitimate authority, rules with justified exceptions, and so on. The aggregate refusal rate was 75.4%. Models knew what they were dealing with - they engaged with the defeat conditions in 57.5% of cases. They just declined to help anyway.
 Weighing rule legitimacy requires judgment, not pattern matching. Safety-trained models appear to skip that step.
Source: commons.wikimedia.org
Weighing rule legitimacy requires judgment, not pattern matching. Safety-trained models appear to skip that step.
Source: commons.wikimedia.org
The finding isn't that models refuse harmful things - that's intended behavior. The finding is that refusal is "decoupled from their capacity for normative reasoning." The model can identify that a rule is illegitimate or that an exception is justified, acknowledge that in its response, and still refuse to help. It's doing the analysis and ignoring the output.
For practitioners building on top of safety-trained models, this matters whenever your users legitimately need to navigate rules. Think of a legal professional asking for help drafting an argument against a procedurally improper court order, or a whistleblower seeking guidance on reporting violations. The model can understand the justification, it just won't act on it.
The authors are clear about what this reveals: current safety training produces rule-following, not ethical reasoning. The model learned "rule = comply" as a near-unconditional reflex. That's a problem as we deploy these systems in contexts where moral judgment, not blind compliance, is what's actually needed. Prior work on how Anthropic found functional emotions inside Claude that can drive goal-seeking behavior adds more context here - the mismatch between what models appear to reason about and what they actually do runs deeper than refusal.
Two Ways Reasoning Models Lose the Thread
Paper: "Reasoning Fails Where Step Flow Breaks" - Xiaoyu Xu, Yulan Pan, Xiaosong Yuan, Zhihong Shen, Minghao Su, Yuanhao Su, Xiaofeng Zhang (arXiv:2604.06695, accepted ACL 2026)
Large reasoning models (LRMs) like o1-class systems generate long chains of thought before producing a final answer. The assumption is that the model tracks context across those steps - that what happened in step 3 informs step 7. This paper tests that assumption and finds it breaks in two distinct, layer-specific ways.
The authors introduce Step-Saliency, an analysis tool that builds step-to-step influence maps by pooling attention-gradient scores across a model's layers. These maps show, at each layer, which prior reasoning steps the model is actually attending to when producing the current step. The visualization is diagnostic: you can see where context flows and where it drops out.
Two failure patterns appear consistently:
Shallow Lock-in happens in the early layers. The model over-focuses on the current step and barely reads the earlier context. Each step is produced in near-isolation from what came before, so reasoning can't build up properly across a long chain.
Deep Decay happens in the late layers. Deep layers lose saliency on the thinking segment as a whole - the reasoning trace becomes steadily less visible - while the summary section increasingly attends only to itself and to the last few steps. The model, in effect, forgets most of what it reasoned through.
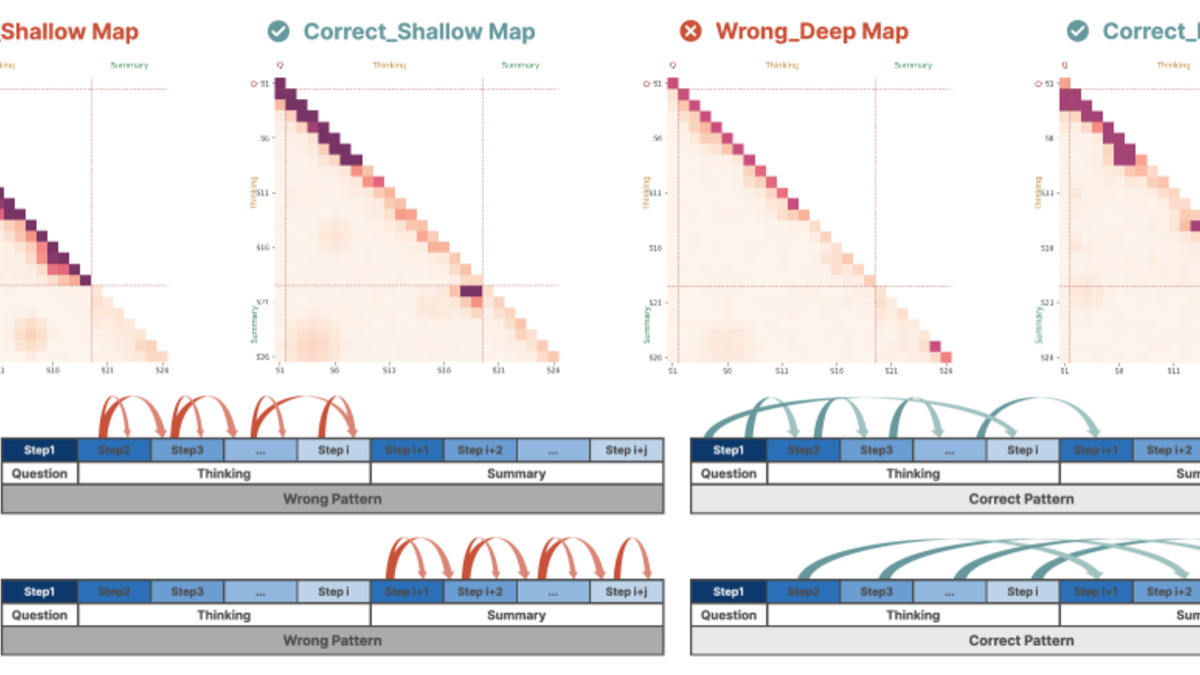 Step-Saliency heatmaps from the paper depicting how early layers fail to read prior steps (Shallow Lock-in) and how late layers lose track of the full reasoning trace (Deep Decay).
Source: arxiv.org
Step-Saliency heatmaps from the paper depicting how early layers fail to read prior steps (Shallow Lock-in) and how late layers lose track of the full reasoning trace (Deep Decay).
Source: arxiv.org
The intervention is called StepFlow. It uses two techniques: Odds-Equal Bridge (OEB), which adjusts the attention dynamics to give earlier steps more equal influence on current ones, and Step Momentum Injection (SMI), which reinforces saliency on the thinking segment in deeper layers. Combined, they improved accuracy on math, science, and coding benchmarks across multiple reasoning models - without retraining. That last point is significant. This is a post-hoc fix applied at inference time.
This connects to an earlier line of research we covered on how CoT control fails and how models commit to answers internally long before their chain-of-thought reveals it. StepFlow adds a complementary picture: even when the reasoning trace is genuine, structural information-flow problems mean it isn't actually being used the way we assume.
Knowing When a Reasoning Model Doesn't Know
Paper: "SELFDOUBT: Uncertainty Quantification for Reasoning LLMs" - Satwik Pandey, Suresh Raghu, Shashwat Pandey (arXiv:2604.06389, submitted to COLM 2026)
Uncertainty quantification for reasoning models has a cost problem. The standard approach - sampling the model many times and measuring agreement across outputs - works reasonably well but gets expensive fast, especially with o1-class models that create long traces. SELFDOUBT offers a single-pass alternative.
The core insight is that reasoning traces contain behavioral signals about uncertainty. A model that hedges ("I'm not sure whether...", "this could also be...") and then doesn't actually verify its own uncertainty is expressing a different internal state than one that hedges and then resolves the doubt. The authors formalize this as the Hedge-to-Verify Ratio (HVR): count the hedging markers in the trace, check whether self-verification behavior counteracts them, and compute the ratio.
Traces without any hedging markers show 96% correctness - a high-precision confidence gate that costs nothing extra to compute.
The full SELFDOUBT score builds on HVR and beats semantic entropy methods across seven models on three benchmarks: BBH, GPQA-Diamond, and MMLU-Pro. In cascaded deployment - where uncertain outputs are flagged for human review or a more expensive model - it achieves 90% accuracy at 71% coverage without any task-specific training data.
The inference cost reduction is real. Semantic entropy typically requires sampling 5-20 outputs to estimate uncertainty. SELFDOUBT requires one. At current API pricing for reasoning models, that's a meaningful difference for any application doing uncertainty-gated routing. The fact that it generalizes across seven different models without fine-tuning also matters for teams that run multiple models in production.
Common Thread
These three papers aren't obviously connected, but they're all about the gap between what AI systems appear to do and what they actually do. Safety training looks like moral reasoning from the outside but is rule-following at best. Reasoning traces look like careful deliberation but have structural deficits that prevent context from flowing properly. Confidence in an answer looks uniform from the outside but has measurable internal signals that distinguish real confidence from hedged uncertainty.
The implication for practitioners is concrete: the interface behavior of a model is not a reliable guide to its internal process. These papers give us better tools to see inside.
Sources:

