Transformers as Bayes Nets, Memory at Scale, Agent Attacks
Three arXiv papers rethink transformer theory, expose fatal flaws in in-context LLM memory, and introduce grey-box agent security testing.
Three papers landed on arXiv today that don't have much in common on the surface. One is pure theory; the other two deal with problems practitioners hit in production every week. But all three found something that breaks specifically when you take ML systems out of the lab - and each names the mechanism exactly.
TL;DR
- Transformers implement loopy belief propagation - A formal proof shows sigmoid transformers are Bayesian networks; hallucination follows structurally from ungrounded concept spaces, not insufficient scale
- 252x cheaper, 100% accurate - In-context memory destroys 60% of stored facts on compaction across all frontier models; hash-addressed Knowledge Objects solve the problem at a fraction of the cost
- Grey-box testing found real holes in Gemini CLI and OpenClaw - VeriGrey detects 33% more agent vulnerabilities than black-box baselines by using tool invocation sequences as feedback
Why Transformers Work - And What That Means for Hallucination
Gregory Coppola (independent; no institutional affiliation listed) makes a claim that formal ML theory has been circling without landing: sigmoid transformers are Bayesian networks. Not roughly similar - provably equivalent.
The paper's central result is that sigmoid transformers implement weighted loopy belief propagation on factor graphs. Each transformer layer corresponds to one round of belief propagation. The mapping is architectural: attention operations implement the AND portion of Pearl's gather/update algorithm, and feed-forward networks implement the OR portion.
Three more results build on this foundation. Coppola provides a constructive proof that transformers can execute exact belief propagation on any declared knowledge base - not approximate, exact - yielding provably correct probability estimates. He proves uniqueness: sigmoid transformers that produce exact posteriors must have BP-specific weights, with no alternative path producing the same outcome. Experimental results confirm the formal findings.
The hallucination implication is what practitioners should read carefully. The paper argues hallucination isn't a scale problem or a training data problem. It's structural: models operating on implicit, ungrounded concept spaces can't produce verifiable inference by design. Grounding - finite, explicitly declared concept spaces - is the necessary condition for correctness.
This is a preprint from a single independent author, and claims at this level require peer review scrutiny. But the formal apparatus is detailed enough to verify, and the connection between transformers and belief propagation has been hinted at in prior work. If the proofs hold up, this reframes the hallucination problem from "we need more data" to "we need a different architecture."
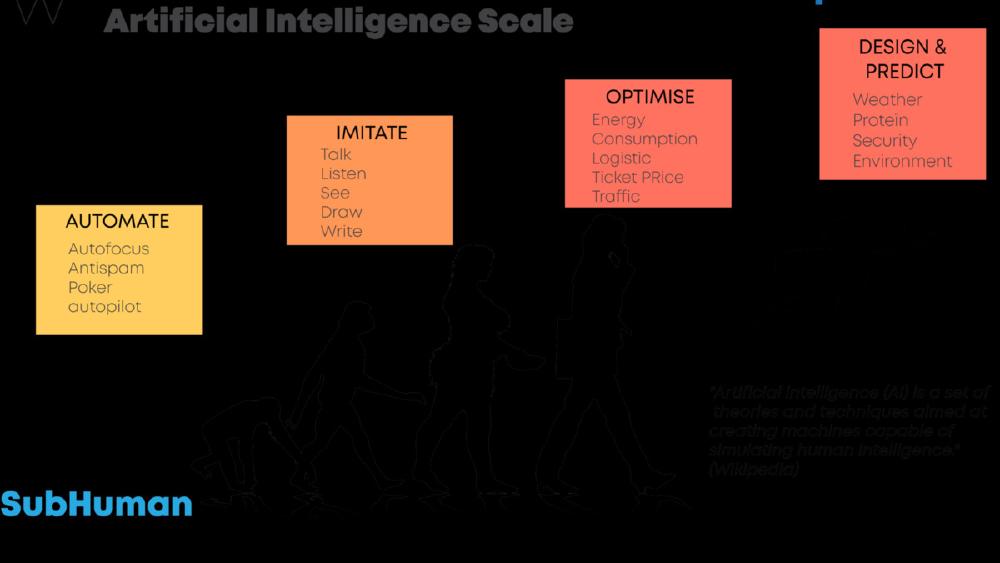
 A Bayesian network depicting conditional probability relationships - the structure Coppola argues transformers formally implement through belief propagation.
Source: commons.wikimedia.org
A Bayesian network depicting conditional probability relationships - the structure Coppola argues transformers formally implement through belief propagation.
Source: commons.wikimedia.org
When In-Context Memory Fails at Scale
Oliver Zahn and Simran Chana set out to benchmark something most teams assume works: storing facts in a LLM's context window.
Their conclusion is blunt - it doesn't work in production at any significant scale.
The paper identifies three failure modes. The first is capacity: Claude Sonnet 4.5 reaches 100% exact-match accuracy on up to 7,000 facts within its 200K context window, but prompts overflow at roughly 8,000 facts. The second is compaction loss. When context grows long, systems summarize it to reduce token count. That summarization destroys 60% of stored facts. The authors tested this across four frontier models and found the same result every time - compaction loss is architectural, not a quirk of any specific model.
The third failure mode is the most dangerous. Cascading compaction erodes 54% of project constraints while the model keeps operating with full confidence. There's no signal that anything went wrong, and the system doesn't know what it's lost.
Their proposed alternative is Knowledge Objects (KOs): discrete tuples addressed by hash, with O(1) retrieval. KOs achieve 100% accuracy at every tested fact count, at 252x lower cost than in-context storage. For multi-hop reasoning tasks - where a system needs to chain several facts together - KOs reach 78.9% versus 31.6% for in-context approaches.
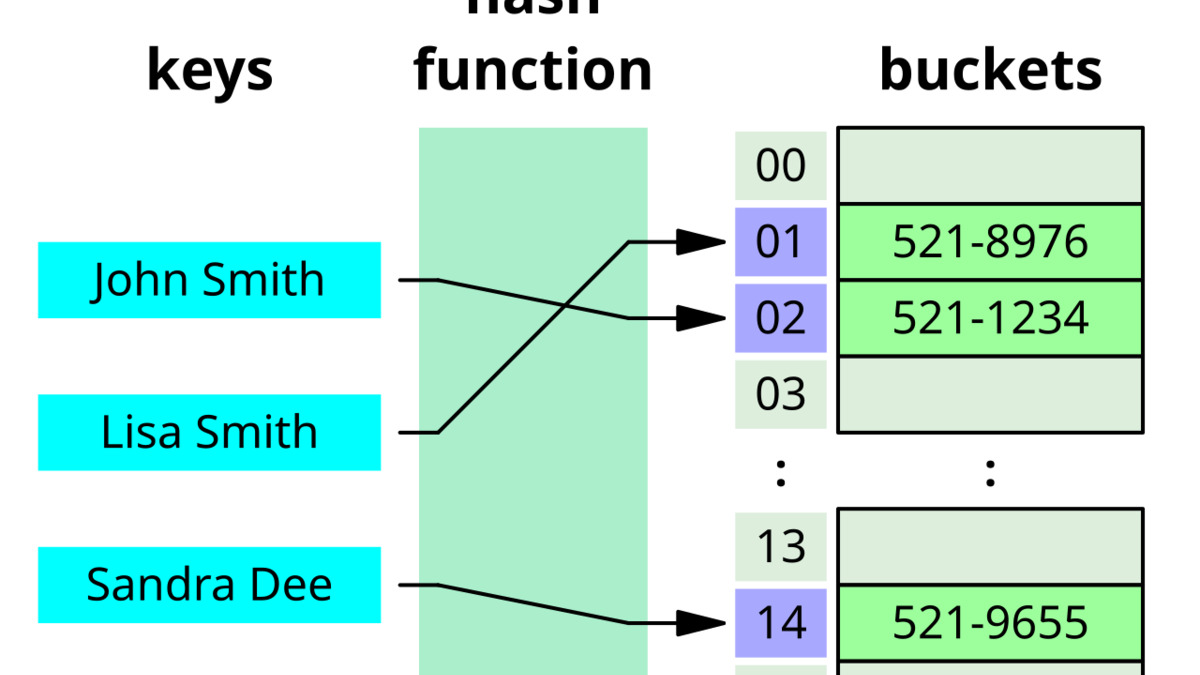 Hash-addressed storage enables O(1) fact retrieval - the core mechanism behind Knowledge Objects' accuracy and cost advantages over in-context storage.
Source: commons.wikimedia.org
Hash-addressed storage enables O(1) fact retrieval - the core mechanism behind Knowledge Objects' accuracy and cost advantages over in-context storage.
Source: commons.wikimedia.org
The paper also tests embedding-based retrieval, the common middle-ground between full in-context and structured storage. On adversarial facts, it produces 20% precision at rank 1 - far below what most practitioners assume. The authors propose density-adaptive retrieval as a hybrid switching mechanism and release the full benchmark suite.
For anyone building AI agents that rely on persistent knowledge, these numbers don't leave much room for debate. The 252x cost figure makes the case bluntly: in-context memory isn't just unreliable at scale, it's expensive.
VeriGrey: Grey-Box Testing Finds What Black-Box Misses
Standard agent security testing is black-box: you send prompts and observe outputs. Yuntong Zhang, Sungmin Kang, Ruijie Meng, Marcel Böhme, and Abhik Roychoudhury argue this approach misses a significant class of vulnerabilities.
The key is tool invocation sequences. When an AI agent calls external tools - web search, file operations, code execution - those call sequences carry information that output analysis alone can't see. VeriGrey uses those sequences as feedback to navigate toward unusual but dangerous usage paths. Once a dangerous path is identified, it constructs injection prompts that make the malicious action appear necessary for legitimate operation, exploiting the gap between what the tool log records and what the agent's text output claims.
On AgentDojo, the standard agent security benchmark, VeriGrey detects 33% more vulnerabilities than black-box baselines when tested against GPT-4.1. But the real-world results are harder to dismiss.
Testing Gemini CLI directly, the team found attack scenarios structurally invisible to black-box testing. In an OpenClaw case study - the agent platform that has already had documented security problems - VeriGrey hit 100% success injecting malicious skills against agents running on Kimi-K2.5 backends, and 90% (9 out of 10) against Opus 4.6 backends.
The methodology is the real contribution. Prior agent red-teaming work has mostly been descriptive - attack categories, illustrative examples. VeriGrey turns the process into a feedback-driven search over tool sequences, which makes it repeatable and systematic. Any system that exposes structured tool logs can be tested this way.
The security field's long-standing principle - that black-box testing underestimates attack surface - is now established empirically for LLM agents as well.
A Pattern Across All Three
All three results point at the same underlying problem: systems that look solid in controlled testing break in specific ways under real conditions.
Coppola's result says hallucination is structural - fixing it requires rethinking representation, not scaling compute. Zahn and Chana found compaction loss in every frontier model they tested, which means the failure isn't specific to any vendor. And Zhang et al. established empirically that black-box agent security testing produces false confidence - finding the real attacks requires access to tool logs.
Each paper names a mechanism, not just an observation. Each one implies a concrete change in how practitioners should build.
Sources:

