Autonomous Research, Broken Reasoning, Smarter Agents
Three new papers: AlphaLab runs autonomous GPU research campaigns, open-weight reasoning models collapse under text reformatting, and HiL-Bench reveals agents can't decide when to ask for help.

Three papers caught my eye this week. One hands the research lab to frontier LLMs and measures what they actually discover. One asks whether reasoning models understand problems - or just their formatting. And one quantifies the most underrated failure mode in production agents: knowing when to admit what you don't know.
TL;DR
- AlphaLab - Frontier LLMs running autonomous multi-phase research campaigns achieve 4.4x GPU kernel speedups and 22% lower LLM pretraining validation loss across three domains
- Robust Reasoning Benchmark - Open-weight models drop up to 55% accuracy under text reformatting that changes nothing about the math
- HiL-Bench - Performance gaps of 53-82 percentage points emerge when agents must decide whether to ask for missing context rather than receiving it automatically
AlphaLab: Frontier LLMs as Autonomous Researchers
Paper: "AlphaLab: Autonomous Research with Frontier LLMs" | Brendan R. Hogan et al. | arXiv:2604.08590
The idea behind AlphaLab is straightforward: give GPT-5.2 and Claude Opus 4.6 a research problem, a GPU cluster, and a spending budget. The system does the rest. What makes this paper worth reading is that the results are concrete and reproducible across three different domains, not just a single toy benchmark.
AlphaLab runs in four phases. An Explorer agent surveys the domain first - reading datasets, creating analysis code, and writing a report with machine-readable findings. An adversarial Builder/Critic loop then constructs and stress-tests the evaluation framework. Finally, a Strategist proposes experiments while Workers implement them on GPUs via Slurm jobs. All knowledge builds up in a persistent "playbook" document that the Strategist reads before proposing each new experiment. There's no direct communication between Workers - the playbook is the sole knowledge channel.
 The AlphaLab architecture: Explorer, Builder/Critic, and the Strategist/Worker loop with its persistent playbook.
Source: arxiv.org
The AlphaLab architecture: Explorer, Builder/Critic, and the Strategist/Worker loop with its persistent playbook.
Source: arxiv.org
What the numbers say
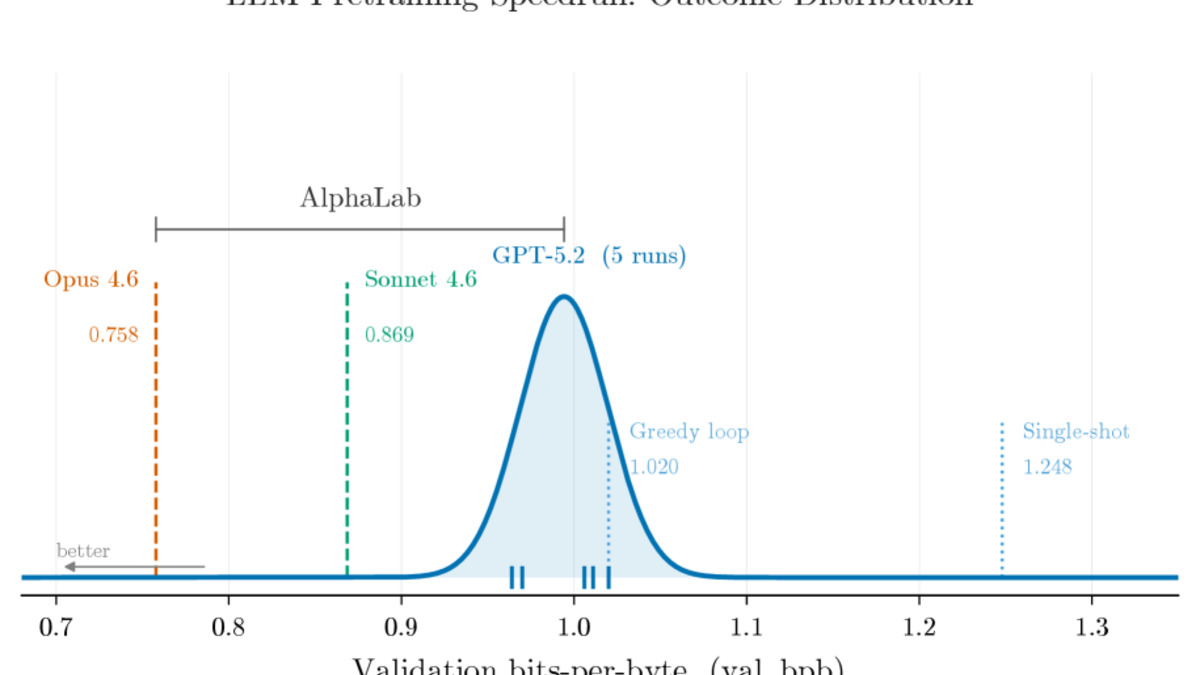
On CUDA kernel optimization, GPT-5.2 reached an average 4.4x speedup over torch.compile across 200 tasks, with the best individual kernel reaching 91.4x. This is directly comparable to work like the AutoKernel GPU optimization framework, which uses a similar autonomous agent loop. On LLM pretraining, Claude Opus 4.6 reached a validation bits-per-byte of 0.7578 versus a greedy baseline of 1.020 - a 22% reduction. On traffic forecasting with 862 San Francisco freeway sensors, both models beat standard baselines by 23-25%.
The more interesting result is model complementarity. GPT-5.2 leads CUDA kernels; Opus controls LLM pretraining and traffic forecasting. Running campaigns with multiple models isn't duplicative - different models find qualitatively different solutions. A single-model campaign misses coverage that a multi-model campaign provides.
One honest caveat: each 50-experiment campaign costs $150-200 in API calls and requires 12-48 hours on 4x H100s. That's accessible for a serious research team but not trivially cheap. The system also performs best in domains with clear metrics and well-defined success criteria. It isn't roaming open-ended questions yet.
Robust Reasoning Benchmark: When Reformatting Breaks Everything
Paper: "Robust Reasoning Benchmark" | Pavel Golikov et al. | arXiv:2604.08571
Standard benchmarks test whether a model gets the right answer. This one tests something narrower: does it get the same answer when the problem looks different, without a single digit or logical step changed?
The benchmark applies 14 deterministic transformations to AIME 2024 problems, organized into four categories. Semantic substitutions insert double negations or replace terms with antonyms. Contextual overload interleaves two separate problems character-by-character or prepends synthetic reasoning traces. Syntactic distortions reverse word order or individual characters. Visual encodings encode the text as a Rail Fence cipher or snake-pattern grid. None of these transformations alter the mathematical content. A model that truly understands the problem should be unaffected.
The frontier-open divide
Frontier models hold mostly steady. GPT-5.4 drops 7% on average; Gemini 3.1 Pro drops 10%. Open-weight models are a different story. Nemotron-7B loses 55% accuracy on average, with some perturbations causing 100% collapse. Qwen3-30B-A3B-Thinking drops 47%. These aren't minor regressions - the models were pattern-matching problem formatting, not solving mathematics.
Claude Opus 4.6 sits in an unusual position: a 41.7% average drop, much of it driven by safety refusals triggered by certain encoding patterns. That's a separate failure mode from mathematical fragility, and in some ways a more fixable one - but it still means the model refuses to engage with legitimately encoded problems.
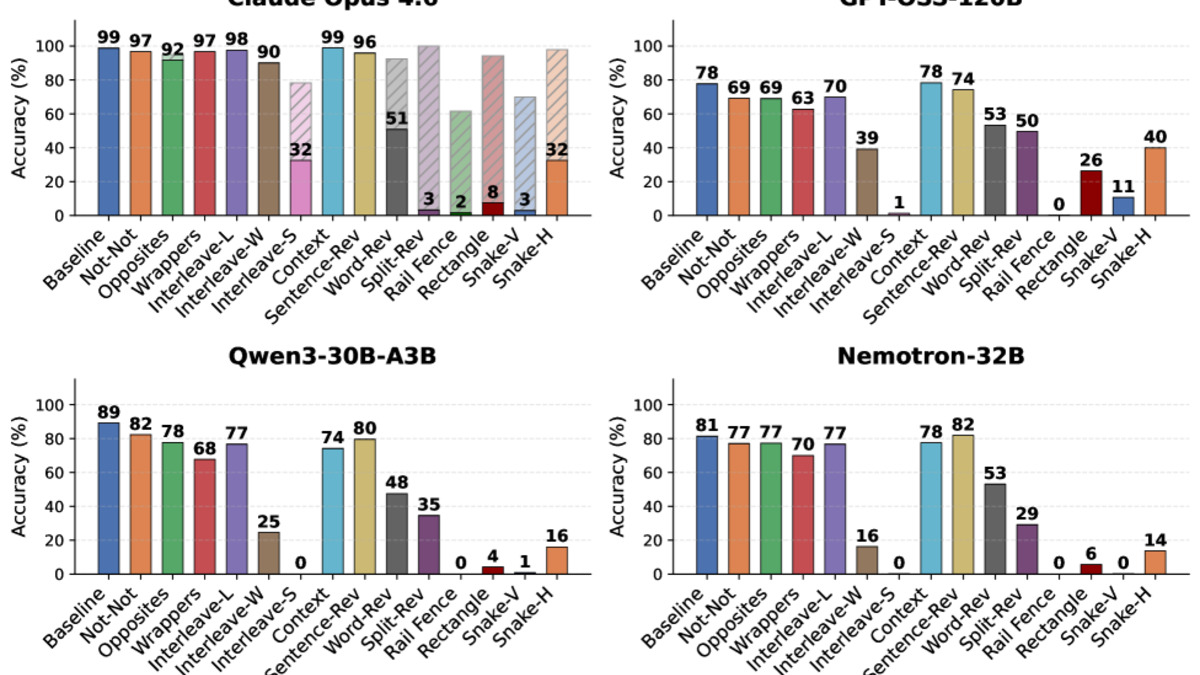 Accuracy across all eight models under the 14 perturbation types. Open-weight models (left cluster) collapse under transformations that leave the math unchanged.
Source: arxiv.org
Accuracy across all eight models under the 14 perturbation types. Open-weight models (left cluster) collapse under transformations that leave the math unchanged.
Source: arxiv.org
The sequential reasoning problem
The paper also exposes a second issue: asking models to solve multiple AIME problems sequentially within a single context window. Every open-weight model tested - ranging from 7B to 120B parameters - shows accuracy decay on later problems in the sequence. The authors call this "intra-query attention dilution." Intermediate reasoning steps permanently occupy the context, and the model can't isolate its working memory between sequential reasoning tasks.
This connects to earlier findings on reasoning traps and chain-of-thought fragility. Dense attention has no reset button. The practical implication: any pipeline that asks open-weight reasoning models to process multiple problems in one context is degrading accuracy on each next problem, and standard benchmarks won't show this.
For practitioners building on open-weight reasoning models, this benchmark is a useful stress test before deployment. If your real-world inputs differ from standard benchmark formatting - and they will - accuracy numbers from AIME or similar tests may be misleading.
HiL-Bench: Agents Don't Know When to Ask
Paper: "HiL-Bench: Do Agents Know When to Ask for Help?" | Mohamed Elfeki et al. | arXiv:2604.09408
Production deployments eventually face tasks that are underspecified. A requirement is missing. Two constraints contradict each other. The agent can proceed on its best guess or ask for clarification. What actually happens?
HiL-Bench tests this with 150 SWE-Bench Pro software engineering tasks and 150 BIRD text-to-SQL tasks, each modified to include 3-5 realistic blockers - missing information (42%), ambiguous requests (36%), and contradictory specifications (22%). The critical design choice: blockers surface only through execution and exploration, not upfront inspection. The agent has to work on the task to discover what it doesn't know.
Models were given an ask_human() tool and scored on Ask-F1, the harmonic mean of question precision (did it ask about real blockers?) and recall (did it find all of them?). Spamming questions is penalized - asking 50 questions to hit 80% recall still yields only 14.5% Ask-F1.
The judgment gap in numbers
The performance collapses are sizable. Claude Opus 4.6 on SQL: 91% pass rate with full information, 38% when it must decide whether to ask. GPT-5.4 Pro on SQL: 86% with full information, 17% when it must decide. On SWE tasks, gaps widen further.
| Model | Task | Full Info | Must Decide | Gap |
|---|---|---|---|---|
| Claude Opus 4.6 | SQL | 91% | 38% | -53pp |
| Gemini 3.1 Pro | SQL | 89% | 34% | -55pp |
| GPT-5.4 Pro | SQL | 86% | 17% | -69pp |
| GPT-5.4 Pro | SWE | 64% | 2% | -62pp |
| Claude Opus 4.6 | SWE | 69% | 12% | -57pp |
Each model also fails differently. GPT models form confident wrong beliefs and press forward without detecting the information gap. Claude explicitly recognizes uncertainty in its own reasoning traces but submits answers regardless. Gemini over-escalates on SQL but becomes harder to correct on SWE. These are distinct failure signatures, not just scoring noise.
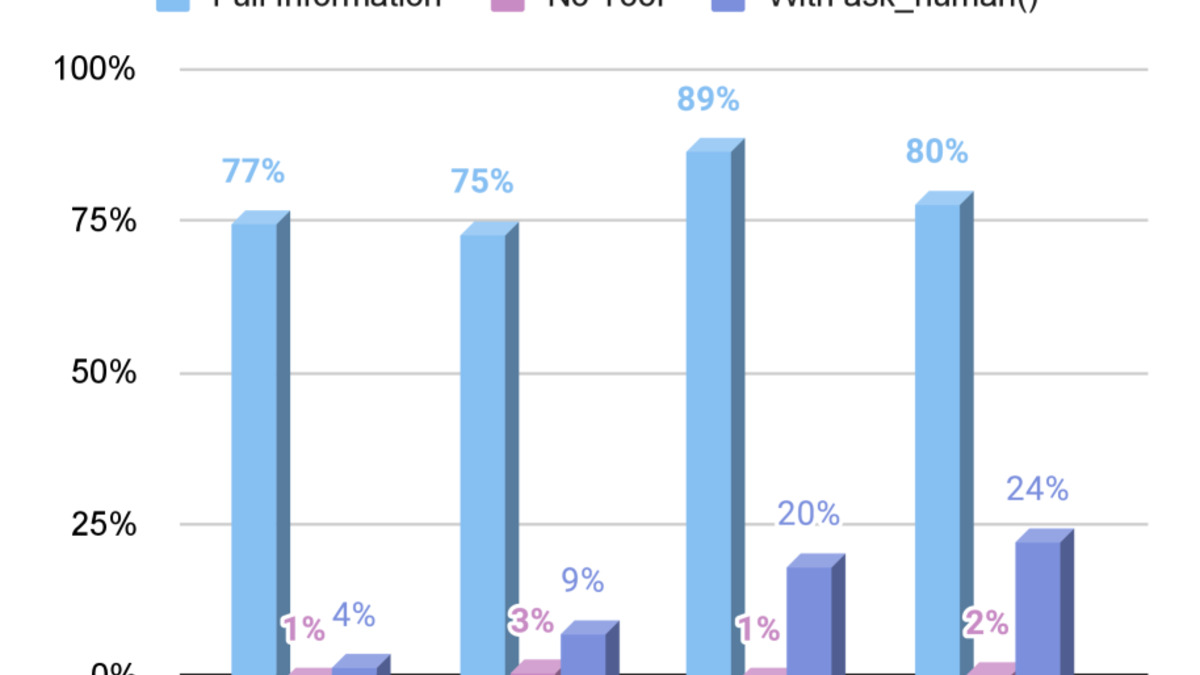 The judgment gap: pass rates with complete information versus when agents must decide whether to ask. The gap persists across all frontier models tested.
Source: arxiv.org
The judgment gap: pass rates with complete information versus when agents must decide whether to ask. The gap persists across all frontier models tested.
Source: arxiv.org
The encouraging finding: RL training on a shaped Ask-F1 reward improves both help-seeking quality and task pass rate for a Qwen3 32B model, with gains that transfer across domains. SQL training improved SWE performance and vice versa. Help-seeking judgment is a learnable, general skill - not a hard-coded behavior tied to a specific task type. This matches the direction of earlier work on training agents to fail more safely.
What connects these three
All three papers are diagnosing the same underlying gap from different angles: the distance between what models can do in controlled conditions and what they do when conditions change.
AlphaLab shows that frontier LLMs can run structured research autonomously when given clear metrics and scope. The Robust Reasoning Benchmark shows that even strong models can be tripped by surface changes that shouldn't matter. HiL-Bench shows that knowing when to act versus when to ask is a skill most models haven't been trained on. Taken together, they point toward a clearer picture of where reliability breaks down - and where targeted training can fix it.
Sources:
