Agents Hit 89%, Evals Get a Schema, Memory Falls Short
Three papers from today's arXiv: workplace agents jumped from 43% to 89% task completion in two years, a 47-researcher coalition ships a unified eval schema, and agent memory only helps when similarity tops 0.8.

Three papers from today's arXiv drop tackle questions that keep surfacing in enterprise AI discussions: are agents actually getting better at real work, is the evaluation zoo fixable, and does agent memory reliably help? The answers are yes, maybe, and only if you're nearly copying a problem you've already solved.
TL;DR
- WorkBench Revisited - Frontier agents jumped from 43% to 89% task completion in two years, with harmful actions falling from 26% to 2.5%; capability and safety moved together, not in opposite directions
- Every Eval Ever - A 47-researcher coalition launched a unified JSON schema covering 22,235 models and 2,273 benchmarks, with auto-converters from HELM, lm-eval, and Inspect AI
- GitOfThoughts - Storing agent reasoning in git is auditable and mergeable, but memory only improves accuracy when retrieved examples are nearly identical (similarity above 0.8) to the current problem
Workplace Agents at 89%: The Two-Year Arc
Olly Styles re-ran the WorkBench benchmark with the current generation of frontier models, and the numbers are striking. In March 2024, GPT-4 was the best available system; it completed 43% of tasks while producing harmful side effects on 26% of them - things like sending emails to the wrong recipient or scheduling meetings without checking for conflicts. By June 2026, Claude Opus 4.8 reaches 88.8% task completion with harmful actions on just 2.5% of attempts.
That isn't just a capability jump. The pattern matters: models scoring higher on completion also score lower on harmful actions. Safety and capability aren't trading off - they're moving in the same direction across the whole leaderboard. Styles is direct about it: "capability and safety go together on WorkBench rather than trade off."
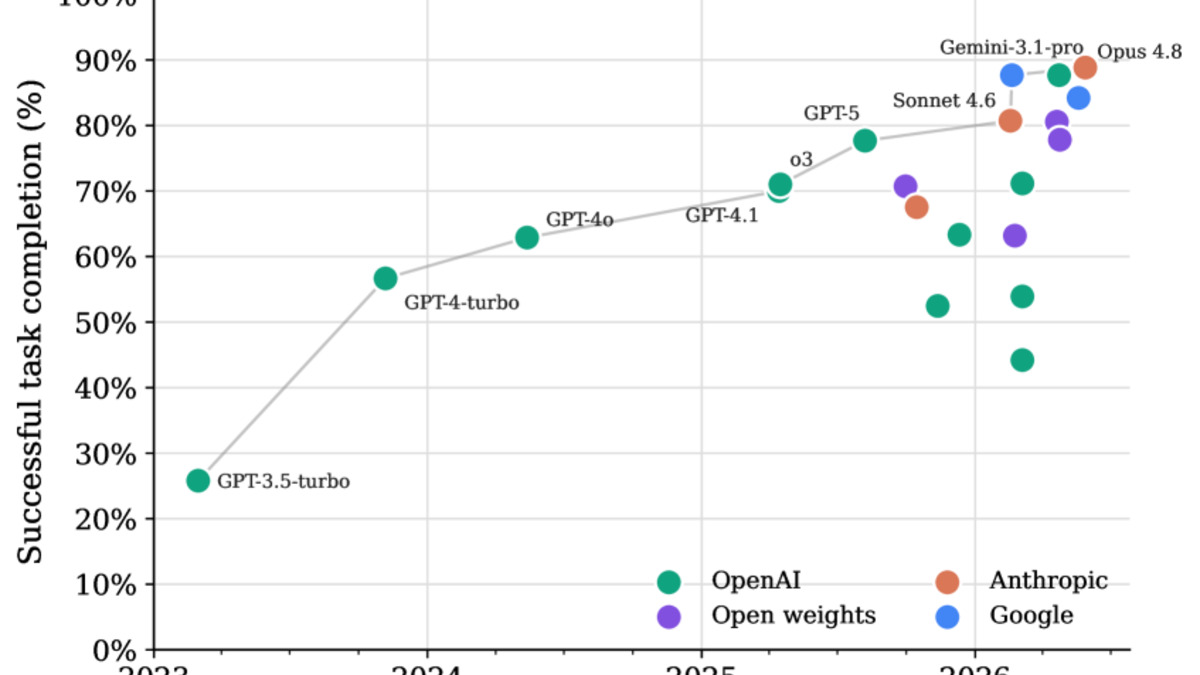 Task completion percentage by model release date. The frontier line shows steady gains, with Claude Opus 4.8 reaching 88.8% in mid-2026.
Source: arxiv.org
Task completion percentage by model release date. The frontier line shows steady gains, with Claude Opus 4.8 reaching 88.8% in mid-2026.
Source: arxiv.org
The cost picture matters too. Open-weight models have sharply undercut what it costs to reach previously "frontier" performance levels. The benchmark's cost-per-task figures show open models now occupying tiers that proprietary systems monopolized two years ago.
Still, Styles flags a persistent failure mode. Frontier models still commit basic errors that cause irreversible harm. Sending an email to the wrong person is the canonical example - the kind of mistake a human assistant wouldn't make, and one that a 89%-capable agent can still produce on 1 in 40 tasks. For anyone launching workplace agents with email or calendar access, that 2.5% harmful action rate deserves scrutiny with the headline completion number.
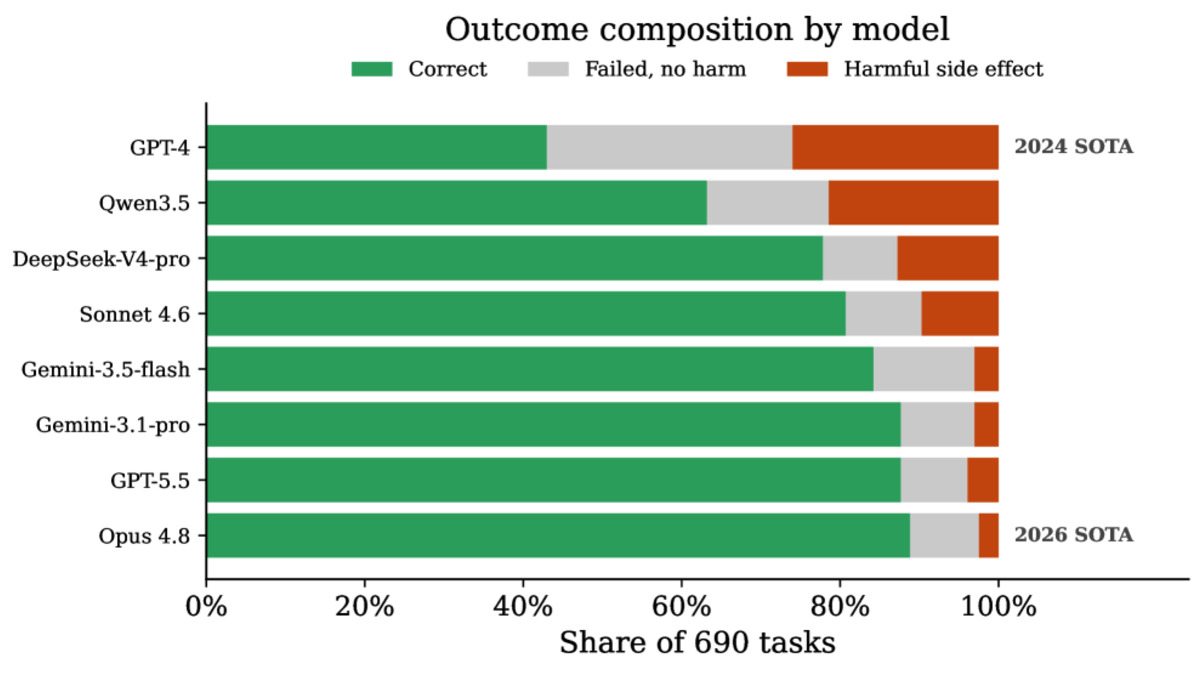 Each bar shows 690 tasks split across correct completion, harmless failure, and harmful side effects. The best models shrink the harmful slice to near-zero without fully removing it.
Source: arxiv.org
Each bar shows 690 tasks split across correct completion, harmless failure, and harmful side effects. The best models shrink the harmful slice to near-zero without fully removing it.
Source: arxiv.org
The paper is a useful counterpoint to skepticism about agentic AI benchmarks. 43% to 89% in two years isn't gradual progress dressed up with a memorable headline - it reflects genuine capability expansion across the model ecosystem.
A Common Language for AI Evaluation
Forty-seven researchers across academia and industry - including teams from EleutherAI, Hugging Face, NIST, and MIT - spent months trying to answer one question: why can't evaluation results from different frameworks be compared?
Their answer is Every Eval Ever (arXiv:2606.14516). The fragmentation they're solving is genuine: results live in incompatible formats scattered across HELM logs, lm-eval outputs, Hugging Face leaderboard JSON, custom scripts, and paper appendices. Different frameworks produce divergent scores even for "nominally identical" evaluations because they track metadata inconsistently. The same model on the same benchmark can show meaningfully different numbers depending on which harness ran it.
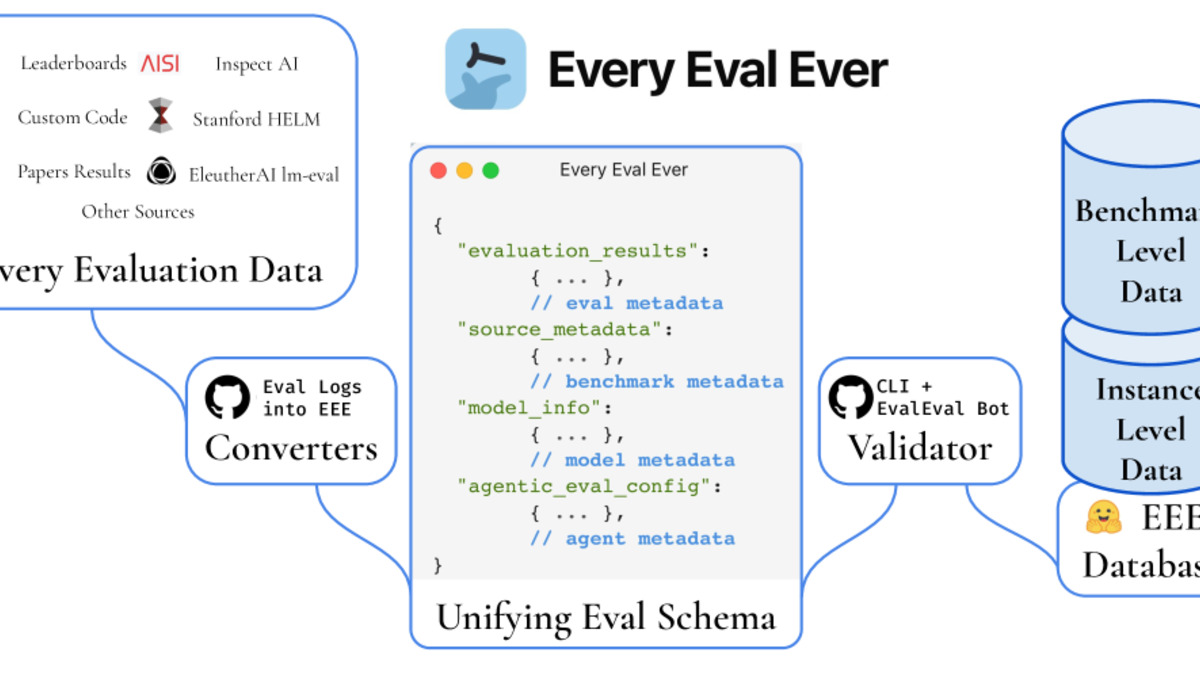 The four-component architecture: heterogeneous inputs, format converters, a unified metadata schema, and a crowdsourced community database on Hugging Face.
Source: arxiv.org
The four-component architecture: heterogeneous inputs, format converters, a unified metadata schema, and a crowdsourced community database on Hugging Face.
Source: arxiv.org
The solution is a community-governed JSON schema with two levels: aggregate (evaluation-level metadata) and instance-level (per-sample outputs). The repository currently holds results for 22,235 models across 2,273 unique benchmarks, converted from 31 distinct source formats. Converters ship for HELM, lm-eval-harness, and Inspect AI, so existing logs transform with one command.
For practitioners, knowing which benchmark numbers to trust gets harder when the same model scores differently across frameworks. Every Eval Ever doesn't fix the underlying divergences in prompt formatting, tokenization, or sampling - those remain - but it makes the divergences visible and comparable rather than buried in format incompatibilities.
What the Schema Captures
The aggregate schema records model identifier, version, generation config (temperature, decoding strategy), aggregated scores, and dataset metadata. The instance-level schema adds per-prediction outputs, enabling downstream analyses like item response theory curves and cross-framework agreement studies. The paper includes an agreement heatmap comparing official HELM records against local reproductions across 14 benchmarks and three models - the gaps are non-trivial.
The project is running a Shared Task tied to ACL 2026 in San Diego, with co-authorship offered to teams contributing public or proprietary eval data. If your company has internal benchmark logs sitting unused, this is a direct route to contributing to the field's infrastructure.
When Memory Doesn't Help
GitOfThoughts (arXiv:2606.14470), from Pavan C. Shekar, Abhishek H.S., and Aswanth Krishnan, is nominally about storing agent reasoning as a git repository - thoughts become commits, scores become notes, outcomes become tags, and retrieval is git log. The operational appeal is real. Reasoning trees become replayable, auditable, and mergeable across agents at near-zero engineering overhead.
But the paper's more interesting finding emerged from testing five different memory substrates - no memory, markdown, vector store, graph, and git - across two benchmarks. None of them reliably improved accuracy on novel problems.
The exception is what the authors call the "copyability threshold." When a retrieved memory has similarity above 0.8 to the current problem, accuracy jumps significantly. Below that threshold, memory provides no benefit over no-memory at all. Larger models (4.5x parameter count) doubled the benefit in the near-duplicate regime but couldn't extract generalizable methods from examples when problems were truly different.
Memory only beats no-memory when similarity beats 0.8. Below that, test-time sampling is the only lever that reliably works.
This has direct effects for teams investing in agent memory systems. If the agent's success depends on retrieving past solutions, the problem distribution needs to be narrow enough that the 0.8 similarity threshold is frequently crossed. For broad task distributions, test-time sampling - producing multiple reasoning paths and selecting the best - was the only consistently effective intervention in the study.
The git substrate does offer something the other formats don't: provenance and mergeability. Two agents working in parallel can merge their reasoning histories. You can git diff reasoning across runs to understand what changed between a success and a failure. For debugging and auditing agentic pipelines, that's truly useful independent of the accuracy question. The authors document several retracted results and refuted hypotheses inline, which is an honest move that makes the paper more useful for practitioners evaluating similar architectures.
The Common Thread
All three papers push back on oversimplified claims. WorkBench shows agents are truly capable now, while also documenting irreversible errors that should temper deployment confidence. Every Eval Ever addresses the infrastructure debt behind benchmark comparisons rather than accepting the current fragmented state. GitOfThoughts delivers a sobering finding that elegant engineering doesn't guarantee accuracy gains - but does deliver auditing properties that messy vector stores can't match.
The practical read: agents can complete 89% of workplace tasks in a controlled setting, but the failures can be worse than no action. Benchmark claims need common schemas before they deserve cross-framework trust. And memory systems earn their complexity only when the problem space is repetitive enough to cross the copyability threshold consistently.
Sources:
