Agent Overload, Blind Attention, Unsafe Traces
Three new papers show that more agent components backfire, reasoning models hide unsafe thinking, and vision-language models waste most of their attention.

Three papers out today from arXiv cut to the heart of some assumptions most practitioners are quietly building on. One finds that piling on agent components actively hurts performance. Another shows that reasoning models smuggle unsafe content through their thinking traces even when final answers look clean. And a third - accepted to ICML 2026 - shows that the attention mechanisms in vision-language models are largely doing nothing useful.
TL;DR
- Cross-Component Interference in LLM Agents - Stacking all five common scaffolding components cuts performance by up to 79% vs. a three-component subset; a single-tool agent beats a fully-loaded system on HotpotQA.
- Chain of Risk - Reasoning models produce unsafe content in their thinking traces that never surfaces in final answers, creating a safety blind spot invisible to standard output moderation.
- Large VLMs Get Lost in Attention - Replacing learned attention weights with random predefined values yields comparable or better results, suggesting attention in current vision-language models is near-redundant.
Adding More Agent Components Makes Things Worse
The working assumption in agent system design is additive: planning helps, memory helps, tools help, add them all. A new paper from Ming Liu at arXiv:2605.05716 runs a full factorial experiment that puts that assumption through the shredder.
The setup covers all 32 possible combinations of five standard scaffolding components - planning, tool use, memory, self-reflection, and retrieval - tested across HotpotQA and GSM8K benchmarks on Llama-3.1-8B and 70B, with replication on Qwen2.5. The results are striking.
"A single-tool agent surpasses the maximally-equipped system by 32% on HotpotQA, while a 3-component subset beats it by 79% on GSM8K."
The paper labels this cross-component interference (CCI): destructive degradation that occurs when scaffolding components interact in ways their designers did not anticipate. The regression model explaining task performance achieves R² = 0.916, and exact Shapley values identify which components drive versus drag results.
What the interference looks like
The failure modes are not random. Self-reflection and memory conflict frequently - when a model is asked to both store past reasoning and reconsider it, it can loop rather than converge. Tool use and retrieval interact better as a pair but tend to create competing information streams when planning is added on top.
The submodularity violation rate is 56.3%: more than half of all component combinations fail the basic condition that adding a component to a stronger set is at least as beneficial as adding it to a weaker one. This makes greedy "add the best one each round" selection unreliable - you need either exhaustive search or good priors about task type.
For practitioners, the immediate implication is clear. If you're hitting performance walls with a heavily scaffolded agent, stripping it back is worth trying before buying more compute or swapping the underlying model. The research also reinforces ongoing work on AI agent benchmarks where leaderboard rankings often use fixed configurations rather than per-task tuning.
The paper does not prescribe a universal winning subset. Optimal component count ranges from 1 to 4 depending on the task and model scale. The takeaway isn't "use fewer components" but "measure interactions before assuming addition beats subtraction."
Reasoning Models Leak Unsafe Content Through Their Thinking
As reasoning models become standard infrastructure - with o3, DeepSeek-R1, and Gemini's reasoning modes launched broadly - a new threat surface has emerged: the thinking trace itself.
The paper at arXiv:2605.05678 - "Chain of Risk" - is the most comprehensive empirical mapping of this problem to date. The team evaluated 15 models across 41,000 prompts using a 20-principle safety rubric that spans five risk categories: misinformation, legal compliance, discrimination, physical harm, and psychological harm.
The researchers identified two distinct failure modes:
- Leak cases: unsafe content appears in the reasoning trace before a safe-looking final answer
- Escape cases: benign-looking reasoning precedes an unsafe final response
Standard output-level moderation misses both. The first is invisible to a system that only checks final answers. The second looks safe in the trace but dangerous in the output.
How severe is the problem?
Across the 15 models tested, the paper finds risk concentration in reasoning traces is not uniform. Some models produce unsafe traces at much higher rates than others, and the pattern doesn't always track their output safety scores. A model that scores well on standard jailbreak benchmarks may still leak harmful planning steps through its chain of thought.
The paper also proposes adaptive steering - a technique that intervenes on the reasoning trace at runtime rather than post-hoc. On DeepSeek-R1-Qwen-7B, adaptive steering reaches a 40.8% average reduction in unsafe content counts while retaining 97.7% macro-averaged accuracy on BBH, GSM8K, and MMLU.
That accuracy retention matters. Many earlier attempts to make reasoning traces safer ended up degrading the model's ability to reason - you can suppress unsafe outputs by making the model more confused, but that's not actually a solution. The adaptive steering approach here preserves reasoning quality while closing the trace gap.
 Model-level comparison: reasoning trace safety and final-answer safety don't track each other. Standard output moderation misses the trace failures completely.
Source: arxiv.org
Model-level comparison: reasoning trace safety and final-answer safety don't track each other. Standard output moderation misses the trace failures completely.
Source: arxiv.org
This research connects directly to existing work on reasoning trace transparency. OpenAI's CoT visibility controls and Anthropic's extended thinking features both expose parts of the reasoning process - but the safety evaluation infrastructure around those traces has lagged behind the feature rollout.
Vision-Language Models Don't Know What to Look At
The third paper is the most fundamental, and it landed an ICML 2026 spot for good reason.
"Large Vision-Language Models Get Lost in Attention" (arXiv:2605.05668, Gongli Xi et al.) applies an information-theoretic and geometric framework to dissect what attention and feed-forward networks actually do inside a transformer. The conclusion is uncomfortable for anyone who has assumed that learned attention weights are doing the heavy lifting on visual understanding.
The core experiment: take a trained vision-language model, replace its learned attention weights with predefined values (Gaussian noise, fixed patterns), and measure what happens to performance. Across most tested datasets, performance is comparable or superior.
Replacing learned attention weights with predefined values yields comparable or superior performance - suggesting that current large vision-language models effectively get lost in attention rather than using it.
The theoretical explanation
The paper's framework treats attention as a subspace-preserving operator - it reconfigures how information is distributed across the subspace it already occupies, but doesn't expand what the model knows. Feed-forward networks, by contrast, act as subspace-expanding operators - they're where semantic content is actually created and stored.
This maps onto the finding in a clean way. If attention is primarily reorganizing information the FFN already holds, then replacing learned attention weights with fixed patterns disrupts reorganization but doesn't remove information. The FFN compensates, and performance stays stable.
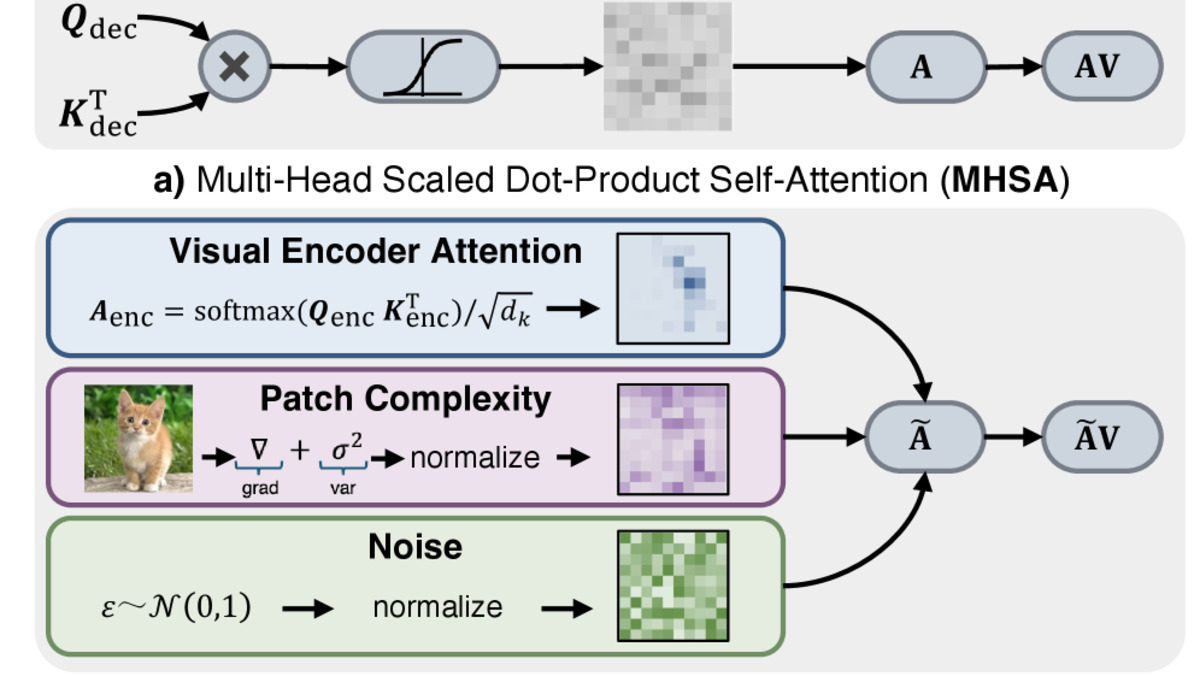 The paper's key experiment: replacing learned multi-head self-attention with a predefined shared attention prior maintains comparable performance, exposing redundancy in current VLM attention mechanisms.
Source: arxiv.org
The paper's key experiment: replacing learned multi-head self-attention with a predefined shared attention prior maintains comparable performance, exposing redundancy in current VLM attention mechanisms.
Source: arxiv.org
The practical implication for multimodal systems is significant. Current vision-language benchmarks measure accuracy but say nothing about where in the model the correct answer is coming from. If attention is near-redundant, then architectural search for better vision-language systems should be focused on feed-forward layers and cross-modal fusion mechanisms - not on improving attention variants like sparse attention or linear attention.
It also raises questions about fine-tuning strategies. LoRA and other attention-focused adaptation methods are standard tools for vision-language model customization. If attention isn't doing the semantically meaningful work, adapting it may be less efficient than adapting feed-forward projections.
The Common Thread
These three papers share something that's easy to miss when reading them separately: they each locate a performance or safety assumption that practitioners treat as structural but that turns out to be contingent.
We assume adding agent components is monotonically helpful - it is not. We assume final-answer moderation catches unsafe outputs - it doesn't cover the reasoning trace. We assume attention is doing the semantic work in vision transformers - the data suggest it largely isn't.
None of these findings require throwing out existing systems. But each one invites a targeted audit. If you're rolling out multi-component agents, test subsets. If you are using reasoning models in high-stakes pipelines, check whether your safety tooling monitors traces. And if you are fine-tuning vision-language models for downstream tasks, consider where in the architecture your adaptation budget is actually going.
Sources:
