Voxtral TTS Review: Mistral Takes On ElevenLabs
Mistral's first open-weights TTS model clones voices from 3 seconds of audio, beats ElevenLabs on price, and arrives with real limitations worth knowing.

Mistral AI has spent two years building a reputation on model quality and open weights. With Voxtral TTS, released on March 26, 2026, the company steps into a market led by ElevenLabs, Cartesia, and OpenAI - and does it with an open-weights model that runs on a single GPU, clones voices from three seconds of audio, and costs roughly half what ElevenLabs charges per character on the API.
TL;DR
- 8.1/10 - the strongest open-weights TTS option available today, with real trade-offs around language coverage and on-device feasibility
- Clones voices from 3 seconds of reference audio with strong speaker similarity; won 68.4% of human eval comparisons against ElevenLabs Flash v2.5 on zero-shot cloning
- Dutch performance is weak (49.4% win rate vs. ElevenLabs), no explicit emotion tags, speech speed control is missing at launch, 16 GB VRAM minimum limits self-hosting
- Use it if you're building enterprise voice agents or need a commercially viable open alternative to ElevenLabs on the Mistral API; skip it if you need 70+ language support or smooth consumer-GPU deployment today
Whether Voxtral TTS actually displaces ElevenLabs in production depends on factors the benchmark numbers don't fully capture. I spent time with the model documentation, the arxiv preprint, and community feedback from day-one adopters. This is what I found.
What Voxtral TTS Is
Voxtral TTS is Mistral's first speech generation model. It outputs 24 kHz audio in WAV, PCM, FLAC, MP3, AAC, and Opus formats, covers nine languages (English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, Arabic), and ships with 20 preset voices plus zero-shot voice cloning from short reference clips.
The model is available two ways: as open weights on Hugging Face under a CC BY-NC 4.0 license (non-commercial use only), and as a commercial API at $0.016 per 1,000 characters via the Mistral platform. That API pricing sits meaningfully below ElevenLabs' ~$0.03 per 1,000 characters.
Voxtral is actually a pair of models - the TTS system reviewed here plus a separate speech recognition component, as our news coverage of the launch covered in detail. The full Voxtral platform positions Mistral as an end-to-end voice AI vendor, not just a model shop.
Architecture - Three Components, One Pipeline
The official arxiv paper describes a three-part architecture. Understanding it helps make sense of both the model's strengths and its constraints.
The backbone is an adapted version of Ministral 3B - a 3.4B-parameter autoregressive transformer that receives concatenated voice reference tokens plus text tokens and creates semantic token sequences. A custom audio codec (300M parameters) compresses 24 kHz audio into 12.5 Hz frames at 2.14 kbps, using a semantic quantizer trained with distillation from Whisper. Then a flow-matching transformer (390M parameters) converts the semantic tokens into actual acoustic waveforms.
Total weights: 8.04 GB, stored in BF16. For self-hosting, you need vLLM 0.18.0+ and a minimum 16 GB of GPU VRAM.
The flow-matching design is what drives the voice cloning quality. Rather than requiring fine-tuning or multi-step voice profiles, it transports Gaussian noise to acoustic embeddings conditioned on the reference audio. The result is a model that captures not just a speaker's tone but their accent, rhythm, and natural hesitations - "ums," "ahs," and pauses included.
Dec 2025 - Ministral 3B released as the base model for Voxtral's decoder backbone.
Mar 25, 2026 - ElevenLabs announces IBM partnership, widely read as a defensive enterprise move ahead of open-source competition.
Mar 26, 2026 - Voxtral TTS released. Open weights on Hugging Face. API goes live on Mistral platform same day.
Voice Quality and Cloning in Practice
The numbers Mistral published are encouraging. On the SEED-TTS benchmark, Voxtral TTS hits a 1.23% word error rate (vs. 1.26% for ElevenLabs v3) and a speaker similarity score of 0.628 (vs. 0.392 for ElevenLabs v3). The UTMOS-v2 naturalness score sits at 4.11, just above ElevenLabs Flash v2.5's 4.09.
In human evaluation, Voxtral won 68.4% of zero-shot voice cloning comparisons against Flash v2.5. For flagship preset voices showing implicit emotion, it won 58.3% against Flash v2.5 and 55.4% against the more expensive ElevenLabs v3.
Language-specific win rates ranged from 49.4% for Dutch to 87.8% for Spanish - a swing that matters if your target market isn't English or Spanish.
All benchmarks are self-reported by Mistral. The evaluator pool sizes and blind conditions haven't been independently verified. Third-party evaluations haven't landed as of this writing. Take the exact percentages as directional, not conclusive.
The cloning mechanism deserves specific attention. Voxtral needs as little as three seconds of reference audio and performs well in the 3-25 second range. Cross-lingual cloning works zero-shot - you can clone a French speaker's voice and create English output, preserving accent and cadence. That's a genuinely useful capability for localization pipelines. No explicit emotion tags are needed: the model infers emotion from the voice prompt itself.
Performance - Latency at Scale
Mistral measured inference on a single NVIDIA H200 with vLLM 0.18.0 and a 500-character input with a 10-second reference clip:
| Concurrency | Latency | Real-Time Factor |
|---|---|---|
| 1 user | 70 ms | 0.103 |
| 16 users | 331 ms | 0.237 |
| 32 users | 552 ms | 0.302 |
The API time-to-first-audio is around 0.8 seconds for PCM and ~3 seconds for MP3. A single H200 serves 30+ concurrent users under 1 second. CUDA graph acceleration reportedly delivered a 2.5x improvement in real-time factor during development.
For voice agent builders - phone trees, customer support bots, in-vehicle assistants - these numbers clear the threshold for real-time interaction. The latency profile is broadly competitive with ElevenLabs Flash v2.5, which targets a similar market.
Pricing and Licensing - the Catch
The $0.016 per 1,000 characters API price is truly competitive. At scale, a workload producing 10 million characters daily costs roughly $160 via Mistral API vs. ~$300 via ElevenLabs. Self-hosting removes per-character costs completely, which is a strong draw for large-volume deployments.
The licensing split, however, matters. The open weights on Hugging Face carry a CC BY-NC 4.0 license - non-commercial use only. Commercial applications require the Mistral API or a separate enterprise agreement. This is a sharper restriction than Mistral's text models, most of which ship under Apache 2.0.
For developers hoping to run Voxtral locally in a revenue-creating product, this is a hard stop. Compare this to Mistral's recent trajectory in the text model space - our Mistral Small 4 review noted that Mistral has been increasingly commercial with its licensing terms, and Voxtral continues that trend.
The audio space is also getting crowded with open alternatives. Tencent's Covo-Audio 7B, released the same week, takes a different approach - an end-to-end audio language model with native full-duplex conversation. Covo-Audio targets OpenAI's Realtime API rather than ElevenLabs, but both releases together signal that proprietary voice AI's cost moat is eroding fast.
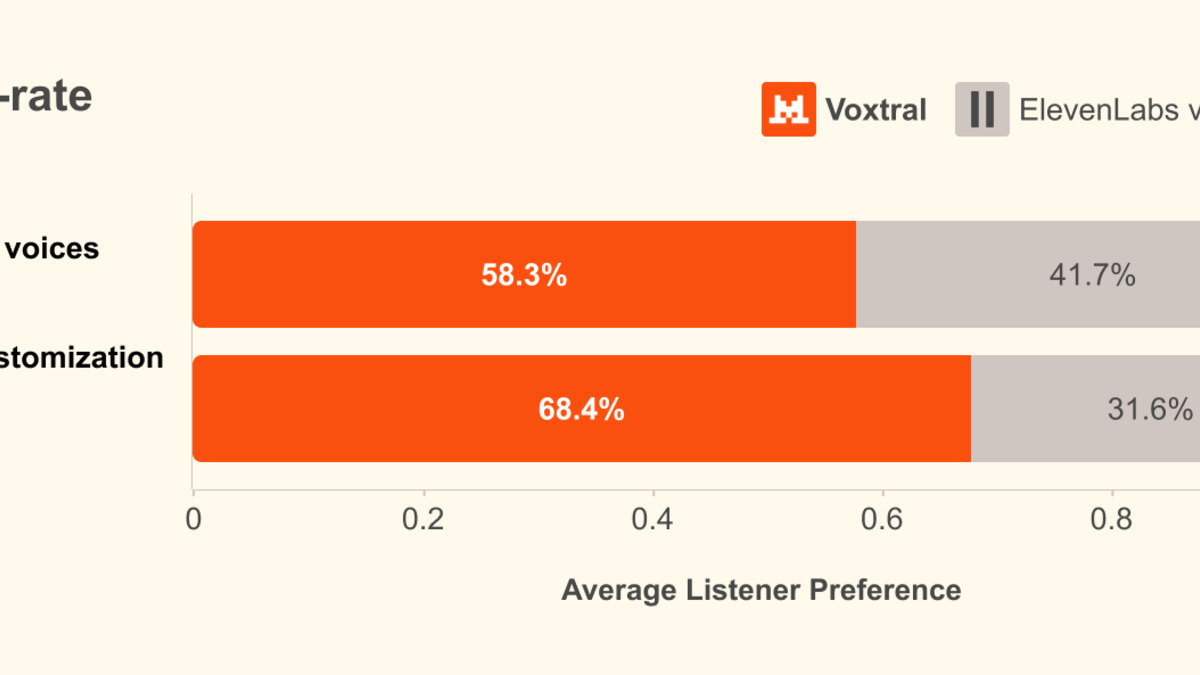 Voxtral TTS benchmark comparisons from the official arxiv preprint (2603.25551), covering WER, speaker similarity, and UTMOS-v2 scores.
Source: arxiv.org
Voxtral TTS benchmark comparisons from the official arxiv preprint (2603.25551), covering WER, speaker similarity, and UTMOS-v2 scores.
Source: arxiv.org
Limitations Worth Knowing
Day-one community feedback on HuggingFace surfaced several real limitations.
Speed control is absent. A filed issue within hours of release reported speech delivery as too fast with no pause control. For voice agents reading financial disclosures or medical instructions, speed pacing matters.
16 GB VRAM minimum. Consumer GPUs in the RTX 4060/4070 range often have 8-12 GB of VRAM. Running Voxtral locally without quantization requires higher-end hardware. The community is asking about INT4 quantization support; none was shipped at launch. MLX optimization for Apple Silicon also wasn't available on day one.
Dutch is the weakest language. The 49.4% win rate against ElevenLabs in Dutch means ElevenLabs is the better product for that market. Hindi showed a +1.61% word error rate regression specifically from the DPO training step, which the paper acknowledges.
Voice cloning instability. Multiple HuggingFace discussions reported the feature as unreliable for some users on day one. Accent inconsistencies surfaced too - German male voices being rendered with an Austrian accent rather than standard German.
No emotion steering via text. ElevenLabs lets you tag emotional delivery using instruction prompts. Voxtral relies completely on what the reference clip carries. That's elegant for voice cloning but limiting if you want a neutral preset voice to express excitement without providing a reference recording of someone sounding excited.
Developer Experience
The API follows an OpenAI-compatible structure at POST /v1/audio/speech, which means existing code built against OpenAI TTS integrates with minimal changes. Mistral Studio includes a browser-based audio preview. The self-hosting path uses Docker via vllm/vllm-openai:v0.18.0 with the --omni flag.
docker run --gpus all -p 8000:8000 \
vllm/vllm-openai:v0.18.0 \
vllm serve mistralai/Voxtral-4B-TTS-2603 --omni
Long-form generation beyond the 2-minute native limit is handled transparently by the API through smart interleaving. You don't need to chunk your own text.
The two API modes - Voices (persistent voice profiles for brand consistency) and Speech Generation (one-off reference clips) - cover the main enterprise use cases cleanly. Voice profile creation is especially useful for call center deployments where a consistent "agent voice" needs to stay stable across millions of interactions.
Installation complexity on the self-hosted path is a known friction point. Early community reports flagged compilation errors during setup. The documentation is functional but lean for a first release.
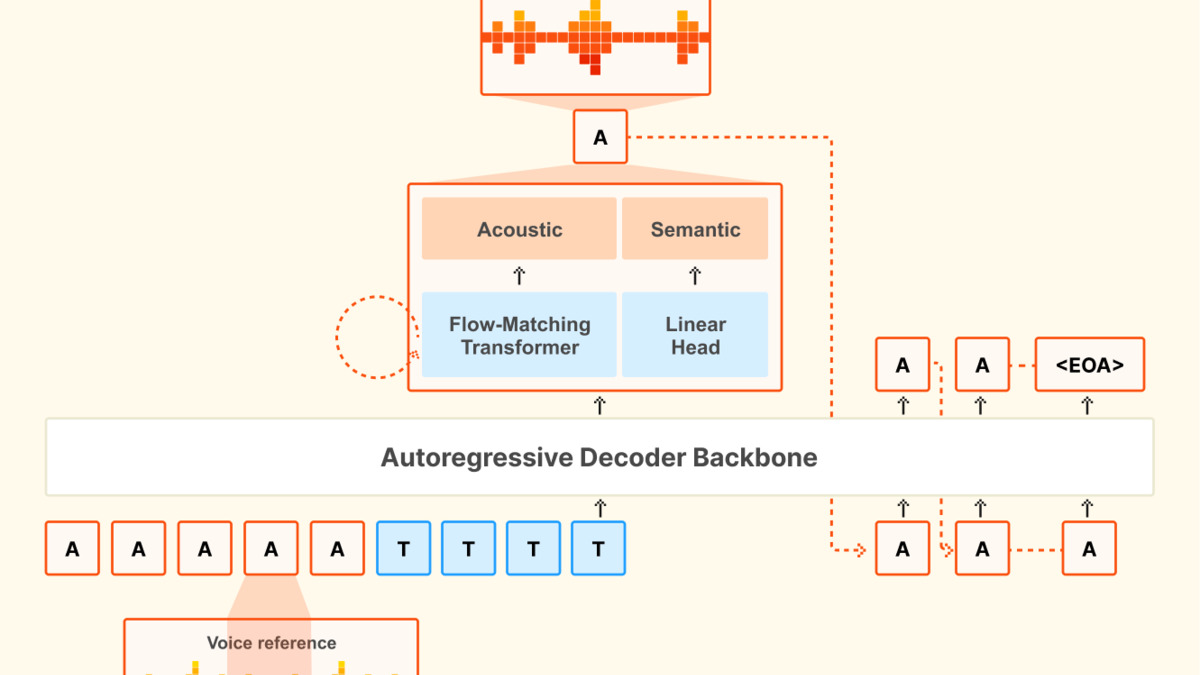 Voxtral TTS architecture: the decoder backbone, audio codec, and flow-matching transformer work together in a three-stage pipeline.
Source: mistral.ai
Voxtral TTS architecture: the decoder backbone, audio codec, and flow-matching transformer work together in a three-stage pipeline.
Source: mistral.ai
Where It Fits in the Voice AI Market
Our Best AI Voice Generators 2026 roundup currently ranks ElevenLabs Flash v2.5 as the API-first default for English applications. Voxtral doesn't displace it today - not with 9 languages against ElevenLabs' 70+, not with day-one voice cloning instability reports, and not with a non-commercial open-weights license.
What Voxtral does do is define a credible API-tier competitor at a lower price point and establish Mistral as a real participant in enterprise voice infrastructure. Pierre Stock, VP of Science Operations at Mistral, described the model as a direct response to enterprise demand for efficient speech systems. That framing - efficiency and cost at enterprise scale - is where the model genuinely delivers.
For teams already invested in the Mistral API ecosystem, adding Voxtral for voice agent features makes straightforward sense. For teams assessing voice providers from scratch, the language coverage gap and the licensing terms are meaningful factors against choosing Voxtral as a primary provider.
Verdict
Voxtral TTS is a strong first entry from a company that has repeatedly shipped models worth taking seriously. The voice cloning quality is real, the API pricing is competitive, and the OpenAI-compatible endpoint makes adoption friction low. The limitations are also real: 9 languages, a hardware floor that excludes consumer GPUs for self-hosting, a CC BY-NC 4.0 license that restricts free commercial use, and a set of first-week issues around speed control and cloning stability that need resolution.
Score: 8.1/10
At $0.016 per 1,000 characters, it's the most cost-effective option at this quality tier on the API. The open weights are a meaningful commitment to transparency even with the non-commercial constraint. Mistral built a legitimate product here - not a dominant one yet, but a competitive one.
Sources
- Mistral Official Voxtral TTS Announcement
- Voxtral TTS - Arxiv Paper 2603.25551
- Hugging Face Model Card - Voxtral-4B-TTS-2603
- Mistral TTS API Documentation
- TechCrunch - Mistral releases open source speech model
- The AI Insider - Mistral Voxtral TTS launch
- SiliconAngle - Mistral Voxtral TTS coverage
- The Decoder - Voxtral clones voices from three seconds
- DEV.to - Developer cost analysis

